Целью контролируемого машинного обучения является построение модели, которая делает прогнозы на основе доказательств при наличии неопределенности. Поскольку адаптивные алгоритмы идентифицируют паттерны в данных, компьютер «учится» на наблюдениях. Когда компьютер подвергается большему количеству наблюдений, он повышает свою прогностическую производительность.
В частности, управляемый алгоритм обучения принимает известный набор входных данных и известных ответов на данные (выходные данные) и тренирует модель для генерации разумных прогнозов для ответа на новые данные.
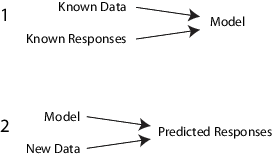
Например, предположим, что вы хотите предсказать, будет ли у кого-то сердечный приступ в течение года. У вас есть набор данных о предыдущих пациентах, включая возраст, вес, рост, артериальное давление и т. Д. Вы знаете, были ли сердечные приступы у предыдущих пациентов в течение года после их измерений. Так, проблема заключается в объединении всех существующих данных в модель, которая может предсказать, будет ли у нового человека сердечный приступ в течение года.
Весь набор входных данных можно рассматривать как неоднородную матрицу. Строки матрицы называются наблюдениями, примерами или экземплярами, и каждая из них содержит набор измерений для субъекта (пациентов в примере). Столбцы матрицы называются предикторами, атрибутами или признаками, и каждый из них представляет собой переменные, представляющие измерение, принятое для каждого субъекта (возраст, вес, рост и т.д. в примере). Можно рассматривать данные ответа как вектор столбца, где каждая строка содержит выходные данные соответствующего наблюдения во входных данных (был ли у пациента сердечный приступ). Чтобы подогнать или обучить контролируемую модель обучения, выберите соответствующий алгоритм, а затем передайте ему входные и ответные данные.
Контролируемое обучение делится на две широкие категории: классификация и регрессия.
В классификации целью является назначение класса (или метки) из конечного набора классов наблюдению. То есть ответы являются категориальными переменными. Приложения включают фильтры нежелательной почты, системы рекомендаций по рекламе, распознавание изображений и речи. Прогнозирование того, будет ли у пациента сердечный приступ в течение года, является проблемой классификации, и возможные классы true и false. Алгоритмы классификации обычно применяются к номинальным значениям отклика. Однако некоторые алгоритмы могут приспосабливаться к порядковым классам (см. fitcecoc).
В регрессии целью является прогнозирование непрерывного измерения для наблюдения. То есть переменные ответов являются реальными числами. Приложения включают прогнозирование цен на акции, потребления энергии или заболеваемости.
Статистика и машинное обучение Toolbox™ контролируемые функции обучения включают в себя потоковую объектную структуру. Можно эффективно обучать различные алгоритмы, объединять модели в ансамбль, оценивать производительность моделей, перекрестную проверку и прогнозировать ответы на новые данные.
Хотя для контролируемого обучения существует много алгоритмов Statistics и Machine Learning Toolbox, большинство используют один и тот же базовый рабочий процесс для получения модели предиктора. (Подробная инструкция по шагам обучения ансамблю приведена в разделе «Структура обучения ансамблю».) Шаги для контролируемого обучения:
Все контролируемые методы обучения начинаются с матрицы входных данных, обычно называемой X здесь. Каждая строка X представляет одно наблюдение. Каждый столбец X представляет одну переменную или предиктор. Представить отсутствующие записи с NaN значения в X. Управление статистикой и управляемыми алгоритмами обучения Machine Learning Toolbox NaN значения, либо игнорируя их, либо игнорируя любую строку с NaN значение.
Для данных ответа можно использовать различные типы данных. Y. Каждый элемент в Y представляет ответ на соответствующую строку X. Наблюдения с отсутствующими Y данные игнорируются.
Для регрессии Y должен быть числовым вектором с тем же количеством элементов, что и число строк X.
Для классификации, Y может быть любым из этих типов данных. Эта таблица также содержит метод включения отсутствующих записей.
| Тип данных | Отсутствует запись |
|---|---|
| Числовой вектор | NaN |
| Категориальный вектор | <undefined> |
| Символьный массив | Строка пробелов |
| Строковый массив | <missing> или "" |
| Массив ячеек символьных векторов | '' |
| Логический вектор | (Не может представлять) |
Существуют компромиссы между несколькими характеристиками алгоритмов, такими как:
Скорость обучения
Использование памяти
Точность прогнозирования новых данных
Прозрачность или интерпретируемость, что означает, насколько легко вы можете понять причины, по которым алгоритм делает свои прогнозы
Подробная информация о алгоритмах приведена в разделе Характеристики алгоритмов классификации. Более подробная информация о алгоритмах ансамбля приведена в разделе Выбор применимого метода агрегирования ансамбля.
Используемая функция фитинга зависит от выбранного алгоритма.
| Алгоритм | Функция подгонки |
|---|---|
| Деревья классификации | fitctree |
| Регрессионные деревья | fitrtree |
| Дискриминантный анализ (классификация) | fitcdiscr |
| k-Ближайшие соседи (классификация) | fitcknn |
| Наивный Байес (классификация) | fitcnb |
| Поддержка векторных машин (SVM) для классификации | fitcsvm |
| SVM для регрессии | fitrsvm |
| Многоклассовые модели для SVM или других классификаторов | fitcecoc |
| Классификационные ансамбли | fitcensemble |
| Ансамбли регрессии | fitrensemble |
| Ансамбли классификационных или регрессионных деревьев (например, случайные леса [1]) | TreeBagger |
Сравнение этих алгоритмов см. в разделе Характеристики алгоритмов классификации.
Тремя основными методами проверки точности полученной подогнанной модели являются:
Проверьте ошибку повторного предоставления. Примеры см. в разделе:
Проверьте ошибку перекрестной проверки. Примеры см. в разделе:
Проверьте ошибку вне мешка для пакетных деревьев принятия решений. Примеры см. в разделе:
После проверки модели может потребоваться изменить ее для большей точности, большей скорости или использования меньшего объема памяти.
Измените параметры фитинга, чтобы попытаться получить более точную модель. Примеры см. в разделе:
Измените параметры фитинга, чтобы попытаться получить модель меньшего размера. Это иногда дает модель с большей точностью. Примеры см. в разделе:
Попробуйте другой алгоритм. Применимые варианты см. в разделе:
При удовлетворении моделью некоторых типов ее можно обрезать с помощью соответствующего compact функция (compact для классификационных деревьев, compact для регрессионных деревьев, compact для дискриминантного анализа, compact для наивного Байеса, compact для SVM, compact для моделей ECOC, compact для классификационных ансамблей, и compact для регрессионных ансамблей). compact удаляет обучающие данные и другие свойства, не необходимые для прогнозирования, например информацию отсечения для деревьев принятия решений, из модели, чтобы уменьшить потребление памяти. Поскольку модели классификации kNN требуют всех обучающих данных для прогнозирования меток, нельзя уменьшить размер ClassificationKNN модель.
Чтобы предсказать классификацию или регрессионную реакцию для большинства подходящих моделей, используйте predict способ:
Ypredicted = predict(obj,Xnew)
obj является подогнанной моделью или подогнанной компактной моделью.
Xnew - новые входные данные.
Ypredicted является прогнозируемым ответом, либо классификацией, либо регрессией.
В этой таблице представлены типичные характеристики различных алгоритмов обучения под наблюдением. Характеристики в любом конкретном случае могут отличаться от перечисленных. Используйте таблицу в качестве руководства для первоначального выбора алгоритмов. Выберите необходимый компромисс в скорости, использовании памяти, гибкости и интерпретируемости.
Совет
Сначала попробуйте дерево решений или дискриминант, потому что эти классификаторы быстро и легко интерпретировать. Если модели недостаточно точно предсказывают отклик, попробуйте другие классификаторы с более высокой гибкостью.
Для управления гибкостью см. подробные сведения для каждого типа классификатора. Чтобы избежать переоборудования, найдите модель меньшей гибкости, которая обеспечивает достаточную точность.
| Классификатор | Поддержка мультиклассов | Поддержка категориального предиктора | Скорость прогнозирования | Использование памяти | Интерпретируемость |
|---|---|---|---|---|---|
Деревья принятия решений - fitctree | Да | Да | Быстро | Маленький | Легкий |
Дискриминантный анализ - fitcdiscr | Да | Нет | Быстро | Малый для линейных, большой для квадратичных | Легкий |
SVM - fitcsvm | Нет. Объединение нескольких двоичных классификаторов SVM с помощью fitcecoc. | Да | Среда для линейных. Медленный для других. | Среда для линейных. Все остальные: средний для мультикласса, большой для бинарного. | Простота для линейного SVM. Трудно для всех других типов ядра. |
Наивный Байес - fitcnb | Да | Да | Среда для простых распределений. Медленный для распределений ядра или высокоразмерных данных | Небольшие для простых дистрибутивов. Носитель для распределения ядра или высокоразмерных данных | Легкий |
Ближайший сосед - fitcknn | Да | Да | Медленно для кубических. Средний для других. | Среда | Трудно |
Ансамбли - fitcensemble и fitrensemble | Да | Да | Быстрый и средний в зависимости от выбора алгоритма | От низкого до высокого в зависимости от выбора алгоритма. | Трудно |
Результаты в этой таблице основаны на анализе многих наборов данных. Наборы данных в исследовании имеют до 7000 наблюдений, 80 предикторов и 50 классов. Этот список определяет термины в таблице.
Скорость:
Быстрый - 0,01 секунды
Средняя - 1 секунда
Медленный - 100 секунд
Память
Малый - 1MB
Средний - 4MB
Большой - 100MB
Примечание
В таблице представлено общее руководство. Результаты зависят от данных и скорости машины.
В этой таблице описывается поддержка типа данных предикторов для каждого классификатора.
| Классификатор | Все предикторы числовые | Все предикторы категоричны | Некоторые категориальные, некоторые числовые |
|---|---|---|---|
| Деревья принятия решений | Да | Да | Да |
| Дискриминантный анализ | Да | Нет | Нет |
| SVM | Да | Да | Да |
| Наивный Байес | Да | Да | Да |
| Ближайший сосед | Только евклидово расстояние | Только расстояние хэмминга | Нет |
| Ансамбли | Да | Да, кроме подпространственных ансамблей классификаторов дискриминантного анализа | Да, кроме подпространственных ансамблей |
[1] Брейман, Л. «Случайные леса». Машинное обучение 45, 2001, стр. 5-32.
