Растянутое во времени аудио
Считывайте аудиосигнал. Прослушайте аудиосигнал и постройте график с течением времени.
[audioIn,fs] = audioread("Counting-16-44p1-mono-15secs.wav"); t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

sound(audioIn,fs)
Использование stretchAudio для применения 1,5 коэффициента ускорения. Прослушайте измененный аудиосигнал и постройте график с течением времени. Частота дискретизации остается прежней, но длительность сигнала уменьшилась.
audioOut = stretchAudio(audioIn,1.5); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 1.5') axis tight grid on

sound(audioOut,fs)
Замедлите исходный аудиосигнал на 0,75 множителя. Прослушайте измененный аудиосигнал и постройте график с течением времени. Частота дискретизации остается такой же, как и исходное аудио, но длительность сигнала увеличилась.
audioOut = stretchAudio(audioIn,0.75); t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, Speedup Factor = 0.75') axis tight grid on

sound(audioOut,fs)
stretchAudio поддерживает TSM на аудио частотного диапазона при использовании метода вокодера по умолчанию. Применение TSM к частотному диапазону аудио позволяет вам повторно использовать расчет STFT для нескольких факторов TSM.
Считывайте аудиосигнал. Прослушайте аудиосигнал и постройте график с течением времени.
[audioIn,fs] = audioread('FemaleSpeech-16-8-mono-3secs.wav'); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Преобразуйте аудиосигнал в частотный диапазон.
win = sqrt(hann(256,'periodic')); ovrlp = 192; S = stft(audioIn,'Window',win,'OverlapLength',ovrlp,'Centered',false);
Ускорите аудиосигнал в 1,4 раза. Задайте длину окна и перекрытия, используемые для создания представления частотного диапазона.
alpha = 1.4; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 1.4') axis tight grid on

Замедлите аудиосигнал в множителе 0,8. Задайте длину окна и перекрытия, используемые для создания представления частотного диапазона.
alpha = 0.8; audioOut = stretchAudio(S,alpha,'Window',win,'OverlapLength',ovrlp); sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, TSM Factor = 0.8') axis tight grid on

Метод TSM по умолчанию (вокодер) позволяет вам дополнительно применить фазовую автоподстройку, чтобы повысить точность исходного аудио.
Считывайте аудиосигнал. Прослушайте аудиосигнал и постройте график с течением времени.
[audioIn,fs] = audioread("SpeechDFT-16-8-mono-5secs.wav"); sound(audioIn,fs) t = (0:size(audioIn,1)-1)/fs; plot(t,audioIn) xlabel('Time (s)') ylabel('Amplitude') title('Original Signal') axis tight grid on

Фазовая блокировка добавляет нетривиальную вычислительную нагрузку к TSM и не всегда требуется. По умолчанию фазовая блокировка отключена. Примените коэффициент скорости 1,8 к входу аудиосигналу. Прослушайте аудиосигнал и постройте график с течением времени.
alpha = 1.8; tic audioOut = stretchAudio(audioIn,alpha); processingTimeWithoutPhaseLocking = toc
processingTimeWithoutPhaseLocking = 0.0798
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = false') axis tight grid on

Примените тот же 1,8 коэффициент скорости к входу аудиосигналу, на этот раз включив фазовую автоподстройку. Прослушайте аудиосигнал и постройте график с течением времени.
tic
audioOut = stretchAudio(audioIn,alpha,"LockPhase",true);
processingTimeWithPhaseLocking = tocprocessingTimeWithPhaseLocking = 0.1154
sound(audioOut,fs) t = (0:size(audioOut,1)-1)/fs; plot(t,audioOut) xlabel('Time (s)') ylabel('Amplitude') title('Modified Signal, alpha = 1.8, LockPhase = true') axis tight grid on

Метод TSM перекрытия-добавления подобия формы волны (WSOLA) позволяет вам задать максимальное количество выборок для поиска наилучшего выравнивания сигнала. По умолчанию дельта WSOLA является количеством выборок в окне анализа минус количество выборок, перекрывающихся между смежными окнами анализа. Увеличение дельты WSOLA увеличивает вычислительную нагрузку, но может также увеличить точность.
Считывайте аудиосигнал. Прослушайте первые 10 секунд аудиосигнала.
[audioIn,fs] = audioread('RockGuitar-16-96-stereo-72secs.flac');
sound(audioIn(1:10*fs,:),fs)Примените коэффициент TSM 0,75 к входу аудиосигналу с помощью метода WSOLA. Прослушайте первые 10 секунд полученного аудиосигнала.
alpha = 0.75; tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola"); processingTimeWithDefaultWSOLADelta = toc
processingTimeWithDefaultWSOLADelta = 19.4403
sound(audioOut(1:10*fs,:),fs)
Применить коэффициент TSM 0,75 к входу аудиосигналу, на этот раз увеличив дельту WSOLA до 1024. Прослушайте первые 10 секунд полученного аудиосигнала.
tic audioOut = stretchAudio(audioIn,alpha,"Method","wsola","WSOLADelta",1024); processingTimeWithIncreasedWSOLADelta = toc
processingTimeWithIncreasedWSOLADelta = 25.5306
sound(audioOut(1:10*fs,:),fs)
Алгоритм фазы вокодера является частотным диапазоном подходом к [1][2] TSM. Основные шаги алгоритма фазы вокодера:
Окна алгоритма сигнал временной области в интервале η, где η = numel . Окна затем преобразуются в частотный диапазон.(Window) - OverlapLength
Чтобы сохранить горизонтальную (через время) когерентность фазы, алгоритм обрабатывает каждый интервал как независимую синусоиду, фаза которой вычисляется путем накопления оценок его мгновенной частоты.
Чтобы сохранить вертикальную (по отдельному спектру) когерентность фазы, алгоритм блокирует усовершенствование групп интервалов к фазовому усовершенствованию локального peaks. Этот шаг применяется только в том случае LockPhase установлено в true.
Алгоритм возвращает измененную спектрограмму к временному интервалу, с окнами, располагаемыми с промежутками в δ, где δ ≈ η/α. α - коэффициент скорости, заданный alpha входной параметр.

Алгоритм WSOLA является подходом во временной области к [1][2] TSM. WSOLA является расширением алгоритма перекрытия и добавления (OLA). В алгоритме OLA сигнал временной области - windowed в интервале η, где η = numel . Чтобы создать измененное во временной шкале выходное аудио, окна разнесены между интервалами, где и ≈, и/или. α - коэффициент TSM, заданный (Window) - OverlapLengthalpha входной параметр.
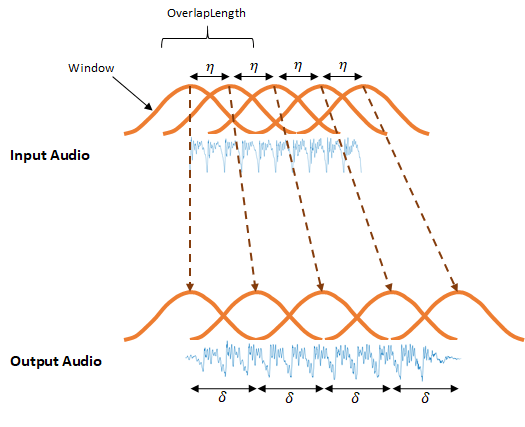
Алгоритм OLA хорошо справляется с воссозданием спектров величин, но может ввести скачки фазы между окнами. Алгоритм WSOLA пытается сглаживать переходы фазы путем поиска WSOLADelta дискретизирует вокруг интервала и для окна, которое минимизирует переходы фазы. Алгоритм ищет лучшее окно итеративно, так что каждое последующее окно выбирается относительно ранее выбранного окна.
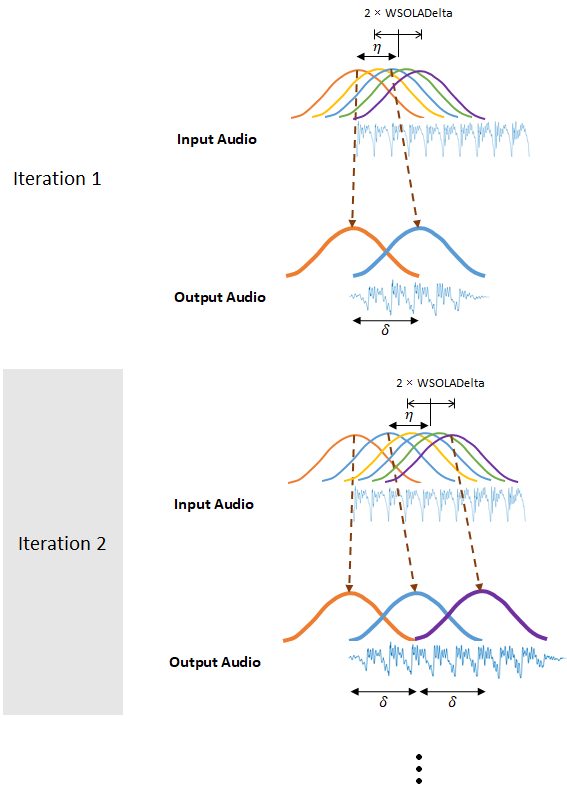
Если WSOLADelta установлено в 0, затем алгоритм сокращается до OLA.
[1] Дриджер, Джонатан и Майнард Мюллер. A Review of Time-Scale Modification of Music Signals (неопр.) (недоступная ссылка). Прикладные науки. Том 6, Выпуск 2, 2016.
[2] Дриджер, Джонатан. Алгоритмы модификации музыкальных аудиосигналов шкалы времени, магистерская диссертация, Саарландский университет, Саарбрюккен, Германия, 2011 год.
audioDataAugmenter | audioTimeScaler | reverberator | shiftPitch
