Вычислите количество чтений, сопоставленных с геномными функциями
T = featurecount(GTFfile,Inputfile)Inputfile которые сопоставляются с геномными функциями, заданными в GTF-форматированном файле GTFfile. GTFfile задает файл аннотации. Inputfile задает имена учитываемых файлов BAM или SAM. Область выхода T - таблица, в которой строки соответствуют функциям, а столбцы - файлам входа. Элементы таблицы состоят из количества чтений, сопоставленных с каждой функцией для данного входного файла.
[___] = featurecount(___, использует дополнительные опции, заданные одним или несколькими Name,Value)Name,Value аргументы в виде пар.
GTFfile - имя файла в формате GTFGTF-форматированное имя файла, заданное как вектор символов или строка.
Пример: 'Dmel_BDGP5_nohc.gtf'
Inputfile - имя файла в формате BAM или SAM;Имя файла в формате BAM или SAM, заданное как вектор символов, строка, строковый вектор или массив ячеек векторов символов.
Пример: 'rnaseq_sample1.sam'
Задайте необязательные разделенные разделенными запятой парами Name,Value аргументы. Name - имя аргумента и Value - соответствующее значение. Name должны находиться внутри кавычек. Можно задать несколько аргументов в виде пар имен и значений в любом порядке Name1,Value1,...,NameN,ValueN.
'CountFragments',true задает, что счетчик считывает как пары пар.'BothEndsMapped' - Логическая переменная, указывающая, должны ли быть сопоставлены оба фрагментаfalse (по умолчанию) | trueЛогическая переменная, указывающая, должны ли быть сопоставлены оба фрагмента, заданная как true или false. Информация о сопоставлении извлекается из FLAG поле в файле входа. По умолчанию это false.
'ProperlyPaired' - Логическая переменная, указывающая, должен ли фрагмент быть правильно спаренfalse (по умолчанию) | trueЛогическая переменная, указывающая, должен ли фрагмент быть правильно соединен в пару, заданная как true или false. Информация о сопряжении извлекается из FLAG поле в файле входа. По умолчанию это false.
'ShowZeroCounts' - Логическая переменная, указывающая, сообщать ли о функциях или метафункциях с нулевым количествомfalse (по умолчанию) | trueЛогическая переменная, указывающая, сообщать ли о функциях или метафункциях с нулевым количеством для каждого входного файла в выходной таблице, заданная как true или false.
По умолчанию это falseто есть в выходную таблицу включаются только строки с ненулевыми счетчиками и столбцы с ненулевыми счетчиками.
'OverlapMethod' - Метод, используемый при присвоении данного чтения метафункции'partial' (по умолчанию) | 'full' | 'max' | 'hits'Метод, используемый при назначении заданного чтения метафункции, заданный как 'partial', 'full', 'max', или 'hits'. Если 'Summarization' установлено в false, затем чтение назначается функциям, вместо метафункции, на основе заданного метода.
В следующей таблице R ссылается на чтение или фрагмент, а M - на метафункцию.
| Метод | Описание |
|---|---|
'partial' | R назначается, чтобы M, если R перекрывается (даже частично) только с M. В противном случае R рассматривается неоднозначным. |
'full' | R присвоено M, если R полностью отображена только внутри M, то есть полностью перекрывается только M. В противном случае R рассматривается как неоднозначное |
'max' | R назначается M, удовлетворяет ли R критериям перекрытия только M, или если R удовлетворяет критериям перекрытия с несколькими метафункциями, но полностью перекрывается только с M. |
'hits' | R назначается, чтобы M, если R перекрывается даже частично только M, или если M является единственной метафункцией с наибольшим количеством функций, пораженных R; в противном случае R рассматривается неоднозначным. |
Следующая принципиальная схема и таблица иллюстрируют результаты этих методов в сочетании с 'CountMultiOverlap' аргумент пары "имя-значение". На рисунке чтение относится к последовательности короткого чтения из файла входа, а функция A и функция B - к функциям, перечисленным в файле GTF.
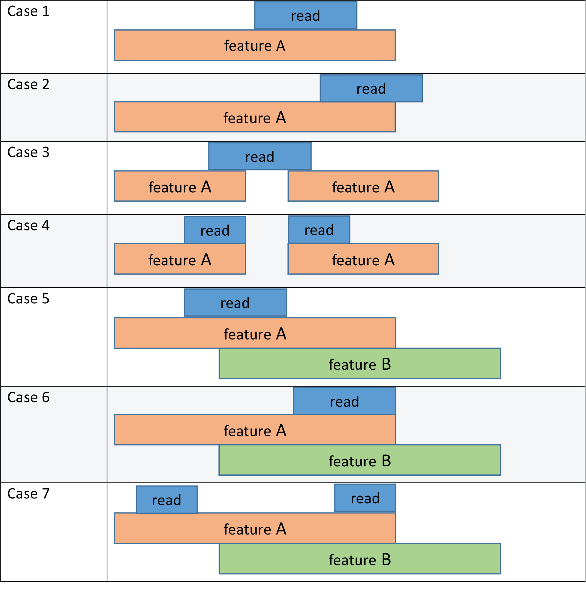
В каждом столбце метода перечислены функции, которым назначено чтение на основе соответствующего метода. The 'CountMultiOverlap' столбец указывает, установлена ли эта пара "имя-значение" true или false и если это имеет какой-либо эффект на результат каждого метода.
'CountMultiOverlap' | 'partial' | 'full' | 'max' | 'hits' | |
|---|---|---|---|---|---|
| Случай 1 | Эффект отсутствует, поскольку чтение преобразуется только в одну функцию (элемент A). | функция A | функция A | функция A | функция A |
| Дело 2 | Эффект отсутствует, поскольку чтение преобразуется только в одну функцию (элемент A). | функция A | нет функции | функция A | функция A |
| Дело 3 | Эффект отсутствует, поскольку чтение преобразуется только в одну функцию (элемент A). | функция A | нет функции | функция A | функция A |
| Дело 4 | Эффект отсутствует, поскольку чтение преобразуется только в одну функцию (элемент A). | функция A | функция A | функция A | функция A |
| Дело 5 | false | неоднозначный | функция A | функция A | неоднозначный |
true | функция A, функция B | функция A | функция A | функция A, функция B | |
| Дело 6 | false | неоднозначный | неоднозначный | неоднозначный | неоднозначный |
true | функция A, функция B | функция A, функция B | функция A, функция B | функция A, функция B | |
| Дело 7 | false | Неоднозначный | функция A | функция A | функция A |
true | функция A, функция B | функция A | функция A | функция A |
отсутствие функции означает, что чтение не назначено ни одному элементу. Если вы задали вторую выходную таблицу S, его Unassigned_noFeature строка для такого вхождения увеличивается на единицу. неоднозначное означает, что чтение не назначено никакой функции, поскольку оно удовлетворяет перекрывающимся критериям для нескольких функций и Unassigned_ambiguous строка для такого вхождения увеличивается на единицу.
'UseParallel' - Логическая переменная, указывающая, вычислять ли параллельноfalse (по умолчанию) | trueЛогическая переменная, указывающая, вычислять ли параллельно, задается как true или false.
В порядок выполнения расчета параллельно, вы должны иметь Toolbox™ Parallel Computing. Если MATLAB® параллельный пул не существует, он создается автоматически, когда опция автоматического создания включена в ваших параллельных настройках. В противном случае расчет выполняется в последовательном режиме.
По умолчанию это false, то есть последовательный режим.
'Verbose' - Логическая переменная, указывающая, отображать ли прогресс расчетовtrue (по умолчанию) | falseЛогическая переменная, указывающая, отображать ли прогресс расчетов, заданная как true или false.
