Оцените ключевые возможности по критериям разделимости классов
[IDX, Z]
= rankfeatures(X, Group)
[IDX, Z]
= rankfeatures(X, Group,
...'Criterion', CriterionValue, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'CCWeighting', ALPHA, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'NWeighting', BETA, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'NumberOfIndices', N, ...)
[IDX, Z]
= rankfeatures(X, Group,
...'CrossNorm', CN, ...)
[ ранжирует функции в IDX, Z]
= rankfeatures(X, Group)X использование независимого критерия оценки для двоичной классификации. X является матрицей, где каждый столбец является наблюдаемым вектором, и количество строк соответствует исходному количеству функций. Group содержит метки классов.
IDX список индексов для строк в X с наиболее значимыми функциями. Z - абсолютное значение используемого критерия (см. ниже).
Group может быть числовым вектором, массивом ячеек из векторов символов или строковым вектором. numel(Group) совпадает с количеством столбцов в X, и Group должно иметь только два уникальных значения. Если он содержит какие-либо значения NaN, функция игнорирует соответствующий вектор наблюдения в X.
[ вызывает IDX, Z] = rankfeatures (X, Group... 'PropertyName', PropertyValue, ...)rankfeatures с необязательными свойствами, которые используют пары имя/значение свойства. Можно задать одно или несколько свойств в любом порядке. Каждый PropertyName должны быть заключены в одинарные кавычки и нечувствительны к регистру. Эти имена свойства/пары значения свойств следующие:
[ устанавливает критерий, используемый для оценки значимости каждой функции для разделения двух маркированных групп. Варианты:IDX, Z]
= rankfeatures(X, Group,
...'Criterion', CriterionValue, ...)
'ttest' (по умолчанию) - Абсолютное значение t-критерия с двумя образцами с объединенной оценкой отклонения.
'entropy' - Относительная энтропия, также известная как расстояние Кулбэка-Лейблера или расхождение.
'bhattacharyya' - Минимальная достижимая ошибка классификации или граница Черноффа.
'roc' - Площадь между кривой рабочей характеристики эмпирического приемника (ROC) и наклоном случайного классификатора.
'wilcoxon' - Абсолютное значение стандартизированной u-статистики двухвыборочного непарного теста Уилкоксона, также известного как Манн-Уитни.
Примечание
'ttest', 'entropy', и 'bhattacharyya' предположим, что нормальные распределенные классы во время 'roc' и 'wilcoxon' являются непараметрическими тестами. Все тесты являются независимыми от функций.
[ использует корреляционную информацию, чтобы перевесить IDX, Z]
= rankfeatures(X, Group,
...'CCWeighting', ALPHA, ...)Z значение потенциальных функций с помощью Z * (1-<reservedrangesplaceholder0>* (RHO))RHO - среднее значение абсолютных значений коэффициента перекрестной корреляции между функцией-кандидатом и всеми ранее выбранными функциями. ALPHA устанавливает весовой коэффициент. Это скалярное значение между 0 и 1. Когда ALPHA является 0 (по умолчанию) потенциальные функции не взвешены. Большое значение RHO (близко к 1) перевешивает статистику значимости; это означает, что функции, которые сильно коррелируют с уже выбранными функциями, с меньшей вероятностью будут включены в выходной список.
[ использует региональную информацию, чтобы перевесить IDX, Z]
= rankfeatures(X, Group,
...'NWeighting', BETA, ...)Z значение потенциальных функций с помощью Z * (1-exp (- (DIST/ BETA).^2))DIST - расстояние (в строках) между кандидатом функции и ранее выбранными функциями. BETA устанавливает весовой коэффициент. Это больше или равно 0. Когда BETA является 0 (по умолчанию) потенциальные функции не взвешены. Небольшой DIST (близко к 0) перевешивает статистику значимости только близких функций. Это означает, что функции, близкие к уже выбранным функциям, с меньшей вероятностью будут включены в выходной список. Эта опция полезна для извлечения функций из временных рядов с временной корреляцией.
BETA может также быть функцией расположения признака, заданной с помощью @ или анонимную функцию. В обоих случаях rankfeatures передает положение строки функции в BETA() и ожидает назад значение, больше или равное 0.
Примечание
Можно использовать 'CCWeighting' и 'NWeighting' вместе.
[ устанавливает количество индексов выхода в IDX, Z]
= rankfeatures(X, Group,
...'NumberOfIndices', N, ...)IDX. Значение по умолчанию совпадает с количеством функций при ALPHA и BETA являются 0, или 20 в противном случае.
[ применяет независимую нормализацию к наблюдениям для каждой функции. Перекрестная нормализация обеспечивает сопоставимость между различными функциями, хотя это не всегда необходимо, потому что выбранный критерий может уже объяснить это. Варианты:IDX, Z]
= rankfeatures(X, Group,
...'CrossNorm', CN, ...)
'none' (по умолчанию) - Интенсивность не является перекрестной нормализацией.
'meanvar' — x_new = (x - mean(x))/std(x)
'softmax' — x_new = (1+exp((mean(x)-x)/std(x)))^-1
'minmax' — x_new = (x - min(x))/(max(x)-min(x))
Найдите уменьшенный набор генов, который достаточен для дифференцирования камер рака молочной железы от всех других типов рака, в наборе данных t-matrix NCI60. Загрузите выборочные данные.
load NCI60tmatrixПолучите логический вектор индекса к камерам рака молочной железы.
BC = GROUP == 8;
Выберите функции.
I = rankfeatures(X,BC,'NumberOfIndices',12);Тестовые функции с линейным классификатором дискриминантов.
C = classify(X(I,:)',X(I,:)',double(BC)); cp = classperf(BC,C); cp.CorrectRate
ans =
1Используйте перекрестное корреляционное взвешивание для дальнейшего уменьшения необходимого количества генов.
I = rankfeatures(X,BC,'CCWeighting',0.7,'NumberOfIndices',8); C = classify(X(I,:)',X(I,:)',double(BC)); cp = classperf(BC,C); cp.CorrectRate
ans =
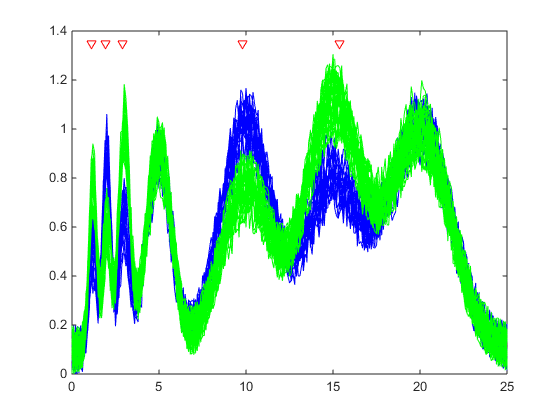
1Найдите дискриминантный peaks двух групп сигналов с Гауссовыми импульсами, модулированными двумя различными источниками.
load GaussianPulses f = rankfeatures(y',grp,'NWeighting',@(x) x/10+5,'NumberOfIndices',5); plot(t,y(grp==1,:),'b',t,y(grp==2,:),'g',t(f),1.35,'vr')
[1] Theodoridis, S., and Koutroumbas, K. (1999). Распознавание шаблонов, Академическая пресса, 341-342.
[2] Liu, H., Motoda, H. (1998). Выбор признаков по открытию знаний и Данных майнингу, Kluwer Academic Publishers.
[3] Росс, Д. Т. et.al. (2000). Систематические изменения шаблонов экспрессии генов в клеточных линиях рака человека. Генетика природы. 24 (3), 227-235.
classify | classperf | crossvalind | randfeatures | sequentialfs
