Выровняйте два набора данных, содержащих последовательные наблюдения, введя погрешности
[I, J]
= samplealign(X, Y)
[I, J]
= samplealign(X, Y,
...'Band', BandValue, ...)
[I, J]
= samplealign(X, Y,
...'Width', WidthValue, ...)
[I, J]
= samplealign(X, Y,
...'Gap', GapValue, ...)
[I, J]
= samplealign(X, Y,
...'Quantile', QuantileValue, ...)
[I, J]
= samplealign(X, Y,
...'Distance', DistanceValue, ...)
[I, J]
= samplealign(X, Y,
...'Weights', WeightsValue, ...)
[I, J]
= samplealign(X, Y,
...'ShowConstraints', ShowConstraintsValue,
...)
[I, J]
= samplealign(X, Y,
...'ShowNetwork', ShowNetworkValue, ...)
[I, J]
= samplealign(X, Y,
...'ShowAlignment', ShowAlignmentValue,
...)
X, Y | Матрицы данных, где строки соответствуют наблюдениям или выборкам, и столбцы соответствуют функциям или размерностям. X и Y может иметь разное количество строк, но они должны иметь одинаковое число столбцов. Первый столбец является ссылочной размерностью и должен содержать уникальные значения в порядке возрастания. Эталонная размерность может содержать выборочные индексы наблюдений или измеряемое значение, такое как время. |
BandValue | Одно из следующих:
|
WidthValue | Одно из следующих:
|
GapValue | Любое из следующих:
|
QuantileValue | Скаляр между 0 и 1 который задает значение квантиля, используемое для вычисления термина QMS, который используется в 'Gap' свойство для вычисления штрафов за разрыв. По умолчанию это 0.75. |
DistanceValue | Указатель на функцию, заданный как
По умолчанию это евклидово расстояние между парами. Внимание Все столбцы в |
WeightsValue | Одно из следующих:
Это свойство контролирует включение/исключение столбцов ( функций) или акцент столбцов ( функций) при вычислении счета расстояния между наблюдениями, которые являются потенциальными совпадениями, то есть при использовании Совет Использование числового вектора-строки для Примечание Значения веса не учитываются при использовании |
ShowConstraintsValue | Управляет отображением пространства поиска, ограниченного заданным 'Band' и 'Width' входные параметры, тем самым давая указание на память, необходимую для запуска алгоритма с определенным 'Band' и 'Width' параметры на ваших наборах данных. Варианты true или false (по умолчанию). |
ShowNetworkValue | Управляет отображением сети динамического программирования, счетов матчей, штрафов за разрыв и пути выигрыша. Варианты true или false (по умолчанию). |
ShowAlignmentValue | Управление отображением первого и второго столбцов X и Y наборы данных в абсциссе и ординате соответственно двумерного графика. Варианты true, false (по умолчанию) или целое число, задающее столбец X и Y наборы данных для построения графика как ординаты. |
I | Вектор-столбец, содержащий индексы строк (наблюдений) в X которые соответствуют строке (наблюдению) в Y. Отсутствующие индексы указывают, что строка (наблюдение) совпадает с погрешностью. |
J | Вектор-столбец, содержащий индексы строк (наблюдений) в Y которые соответствуют строке (наблюдению) в X. Отсутствующие индексы указывают, что строка (наблюдение) совпадает с погрешностью. |
[ выравнивает наблюдения в двух матрицах данных, I, J]
= samplealign(X, Y)X и Y, путем введения пробелов. X и Y являются матрицами данных, где строки соответствуют наблюдениям или выборкам, а столбцы соответствуют функциям или размерностям. X и Y может иметь разное количество строк, но должно иметь одинаковое число столбцов. Первый столбец является ссылочной размерностью и должен содержать уникальные значения в порядке возрастания. Эталонная размерность может содержать выборочные индексы наблюдений или измеряемое значение, такое как время. The samplealign функция использует алгоритм динамического программирования, чтобы минимизировать сумму положительных счетов, полученных из пар наблюдений, которые являются потенциальными совпадениями и штрафами, вытекающими из вставки погрешностей. Возвращаемые значения I и J Векторы-столбцы содержат индексы, которые указывают соответствие для каждой строки (наблюдение) в X и Y соответственно.
Совет
Если вы не задаете возвращаемые значения, samplealign не запускает алгоритм динамического программирования. Выполняемые samplealign без возвращаемых значений, но установка 'ShowConstraints', 'ShowNetwork', или 'ShowAlignment' свойство к true, позволяет исследовать ограниченное пространство поиска, динамическую сеть программирования или выровненные наблюдения, не сталкиваясь с потенциальными проблемами памяти.
[ вызывает I, J] = samplealign (X, Y... 'PropertyName', PropertyValue, ...)samplealign с необязательными свойствами, которые используют пары имя/значение свойства. Можно задать одно или несколько свойств в любом порядке. Каждый PropertyName должны быть заключены в одинарные кавычки и нечувствительны к регистру. Эти имена свойства/пары значения свойств следующие:
[ задает максимально допустимое расстояние между наблюдениями (только вдоль ссылки размерности) в двух наборах данных, таким образом ограничивая количество потенциальных соответствий между наблюдениями в двух наборах данных. Если I, J]
= samplealign(X, Y,
...'Band', BandValue, ...)S - значение в ссылку размерности для заданного наблюдения (строки) в одном наборе данных, тогда это наблюдение согласовывается только с наблюдениями в другом наборе данных, значения которого в ссылку размерности попадать внутрь S ± BandValue. Затем в алгоритм для дальнейшей оценки передаются только эти потенциальные матчи. BandValue может быть скаляром или функцией, заданной с помощью @ , где (z)z является средней точкой между заданным наблюдением в одном наборе данных и заданным наблюдением в другом наборе данных. Значения по умолчанию BandValue является Inf.
Это ограничение уменьшает время и сложность памяти алгоритма от O (MN) по О (sqrt (MN) * K), где M и N количество наблюдений в X и Y соответственно и K является маленькой константой, такой что K<<M и K<<N. Настройте BandValue к максимальному ожидаемому сдвигу между ссылочными размерностями в двух наборах данных, то есть между X(:, 1) и Y(:,1).
[ ограничивает количество потенциальных совпадений между наблюдениями в двух наборах данных; то есть каждое наблюдение в I, J]
= samplealign(X, Y,
...'Width', WidthValue, ...)X подсчитывается ближайшему U наблюдения в Yи каждое наблюдение в Y подсчитывается ближайшему V наблюдения в X. Затем в алгоритм для дальнейшей оценки передаются только эти потенциальные матчи. WidthValue является либо двухэлементным вектором, [U, V] или скаляр, который используется для обоих U и V. Близость измеряется только с использованием первого столбца (ссылочной размерности) в каждом наборе данных. По умолчанию это Inf если 'Band' указывается; в противном случае значение по умолчанию 10.
Это ограничение уменьшает время и сложность памяти алгоритма от O (MN) по О (sqrt (MN) * sqrt (UV)), где M и N количество наблюдений в X и Y соответственно и U и V малы, что U<<M и V<<N.
Примечание
Если вы задаете оба 'Band' и 'Width', только пары наблюдений, которые удовлетворяют обоим ограничениям, считаются потенциальными совпадениями и передаются в алгоритм оценки.
Совет
Задайте 'Width' когда у вас нет хорошей оценки для 'Band' свойство. Чтобы получить указание на память, необходимую для запуска алгоритма с определенными 'Band' и 'Width' параметры на ваших наборах данных, запустите samplealign, но не задавать возвращаемые значения и устанавливать 'ShowConstraints' на true.
[ задает зависимые от положения условия для назначения штрафов за разрыв. I, J]
= samplealign(X, Y,
...'Gap', GapValue, ...)
GapValue является любым из следующих:
Массив ячеек, {G, H}, где G является скаляром или указателем на функцию, заданным с помощью @ , и (X)H является скаляром или указателем на функцию, заданным с помощью @ . Функции (Y)@ и (X)@ необходимо вычислить штраф для каждого наблюдения (строка), если он согласован с погрешностью в другом наборе данных. Функции (Y)@ и (X)@ необходимо вернуть вектор-столбец с одинаковым числом строк, как (Y)X или Y, содержащий штраф за разрыв для каждого наблюдения (строка).
Один указатель на функцию, заданный как @ , который используется для обоих (Z)G и H. Функция @ необходимо вычислить штраф за каждое наблюдение (строка) в обоих (Z)X и Y когда он сопоставлен с погрешностью в другом наборе данных. Функция @ должен принимать в качестве аргументов (Z)X и Y. Функция @ необходимо вернуть вектор-столбец с одинаковым числом строк, как (Z)X или Y, содержащий штраф за разрыв для каждого наблюдения (строка).
Скаляр, который используется для обоих G и H.
Вычисленное значение, GPX, является штрафом за погрешность для совпадения наблюдений из первого набора данных X к погрешностям, вставленным во второй набор данных Y, и является продуктом двух членов: GPX = G * QMS. Термин G принимает свое значение как функцию от наблюдений в X. Точно так же GPY - штраф за погрешность для совпадения наблюдений из Y в зазоры, вставленные в X, и является продуктом двух членов: GPY = H * QMS. Термин H принимает свое значение как функцию от наблюдений в Y. По умолчанию термин QMS является 0,75 квантилем счета для пар наблюдений, которые являются потенциальными совпадениями (то есть парами, которые соответствуют 'Band' и 'Width' ограничения).
Если G и H Положительные скалярные величины, тогда GPX и GPY не зависят от наблюдения, в которое вставляется зазор.
Значения по умолчанию GapValue является 1, то есть оба G и H являются 1, что указывает на то, что штраф по умолчанию для вставок зазоров в обеих последовательностях эквивалентен квантилю (устанавливается 'Quantile' свойство, по умолчанию = 0.75) счет для пар наблюдений, которые являются потенциальными совпадениями.
Примечание
GapValue по умолчанию задается относительно безопасное значение. Однако успех алгоритма зависит от тонкой настройки штрафов за погрешность, которая зависит от приложения. Когда разрыв штрафов велик относительно счета правильных матчей, samplealign возвращает выравнивания с меньшим количеством промежутков, но с более неправильно выровненными областями. Когда штрафы за погрешность меньше, выравнивание выхода содержит более длинные области с погрешностями и меньше совпадающих наблюдений. Задайте 'ShowNetwork' на true сравнение штрафов за погрешность с счетом совпадающих наблюдений в различных областях выравнивания.
[ задает значение квантиля, используемое для вычисления термина I, J]
= samplealign(X, Y,
...'Quantile', QuantileValue, ...)QMS, который используется в 'Gap' свойство для вычисления штрафов за разрыв. QuantileValue является скаляром между 0 и 1. По умолчанию это 0.75.
Совет
Задайте QuantileValue в пустой массив ([]) сделать меры наказания за разрыв независимыми от QMS, то есть GPX и GPY являются функциями только G и H входные параметры соответственно.
[ задает функцию, чтобы вычислить расстояние между парами наблюдений, которые являются потенциальными совпадениями. I, J]
= samplealign(X, Y,
...'Distance', DistanceValue, ...)DistanceValue - указатель на функцию, заданный с помощью @ . Функция (R, S)@ должен принимать в качестве аргументов, (R, S)R и S, матрицы, которые имеют одинаковое число строк и столбцы и чьи парные строки представляют все потенциальные совпадения наблюдений в X и Y соответственно. Функция @ необходимо вернуть вектор-столбец положительных значений с таким же количеством элементов, как и строки в (R, S)R и S. По умолчанию это евклидово расстояние между парами.
Внимание
Все столбцы в X и Y, включая ссылочную размерность, учитываются при вычислении расстояний. Если вы не хотите включать ссылочную размерность в расчеты расстояния, используйте 'Weight' свойство, чтобы исключить его.
[ управляет включением/исключением столбцов ( функций) или акцентом столбцов ( функций) при вычислении счета расстояния между наблюдениями, которые являются потенциальными совпадениями, то есть при использовании I, J]
= samplealign(X, Y,
...'Weights', WeightsValue, ...)'Distance' свойство. WeightsValue может быть логическим вектором-строкой, который задает столбцы в X и Y. WeightsValue может также быть числовым вектором-строкой с таким же количеством элементов, как и столбцы в X и Y, который задает относительные веса столбцов ( функций). По умолчанию это логический вектор-строка со всеми элементами, установленными на true.
Совет
Использование числового вектора-строки для WeightsValue и установка некоторых значений равными 0 может упростить вычисление расстояния, когда наборы данных имеют много столбцов ( функций).
Примечание
Значения веса не учитываются при вычислении ограниченного пространства выравнивания, то есть при использовании 'Band' или 'Width' свойства, или при вычислении штрафов за погрешность, то есть при использовании 'Gap' свойство.
[ управляет отображением пространства поиска, ограниченного входными параметрами I, J]
= samplealign(X, Y,
...'ShowConstraints', ShowConstraintsValue,
...)'Band' и 'Width', с указанием памяти, необходимой для запуска алгоритма с определенными 'Band' и 'Width' на ваших наборах данных. Варианты true или false (по умолчанию).
[ управляет отображением сети динамического программирования, счетов матчей, штрафов за разрыв и пути выигрыша. Варианты I, J]
= samplealign(X, Y,
...'ShowNetwork', ShowNetworkValue, ...)true или false (по умолчанию).
[ управляет отображением первого и второго столбцов I, J]
= samplealign(X, Y,
...'ShowAlignment', ShowAlignmentValue,
...)X и Y наборы данных в абсциссе и ординате соответственно двумерного графика. Ссылки между всеми потенциальными совпадениями, которые удовлетворяют ограничениям, отображаются, и подсвечиваются совпадения, принадлежащие выходу выравниванию. Варианты true, false (по умолчанию) или целое число, задающее столбец X и Y наборы данных для построения графика как ординаты.
Загрузка sunspot.dat, файл данных, включенный в MATLAB® программное обеспечение, содержащее переменную sunspot, которая является двухколоночной матрицей, содержащей изменения активности солнечных пятен за последние 300 лет. Первый столбец является ссылочной размерностью (годами), а второй столбец содержит значения активности солнечного пятна. Активность солнечных пятен циклическая, достигает максимума около каждые 11 лет.
load sunspot.datСоздайте синусоиду с известным периодом активности солнечных пятен.
years = (1700:1990)'; T = 11.038; f = @(y) 60 + 60 * sin(y*(2*pi/T));
Выровнять наблюдения между синусоидой и активностью солнечного пятна путем введения погрешностей.
[i,j] = samplealign([years f(years)],sunspot,'weights',... [0 1],'showalignment',true);
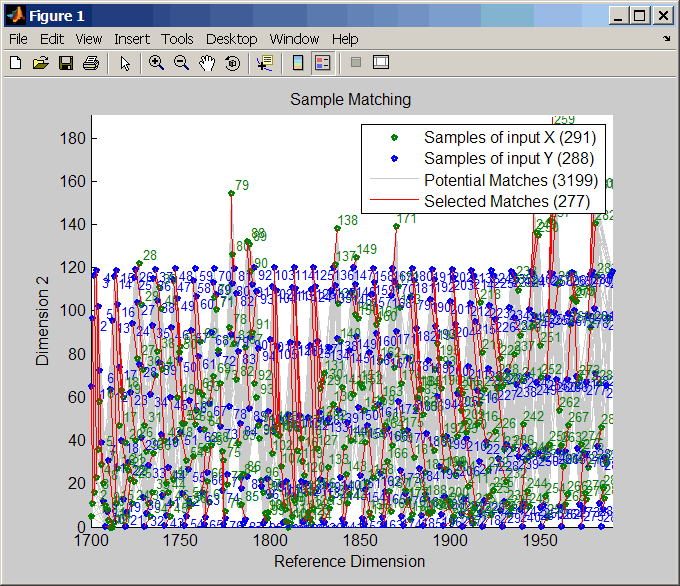
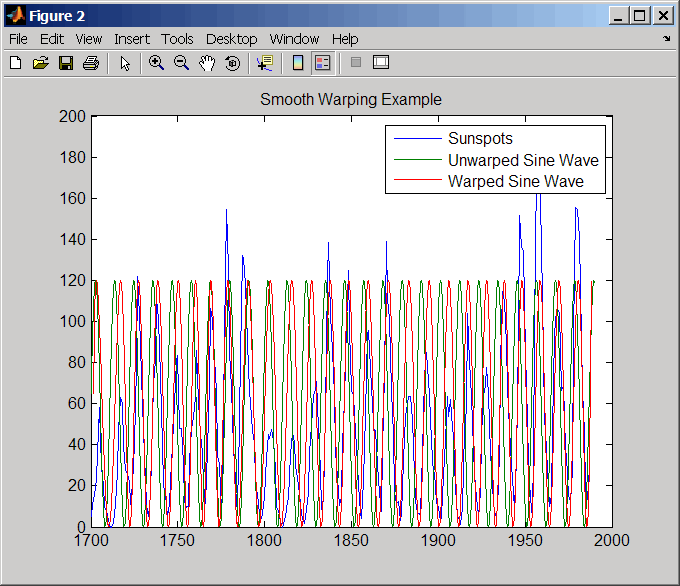
Оцените сглаженную функцию, чтобы деформировать синусоиду.
[p,s,mu] = polyfit(years(i),years(j),15); wy = @(y) polyval(p,(y-mu(1))./mu(2));
Постройте графики циклов солнечного пятна, размотанной синусоиды и деформированной синусоиды.
years = (1700:1/12:1990)'; figure plot(sunspot(:,1),sunspot(:,2),years,f(years),wy(years),... f(years)) legend('Sunspots','Unwarped Sine Wave','Warped Sine Wave') title('Smooth Warping Example')
Создайте два сигнала с зашумленным Гауссовым peaks.
rng('default')
peakLoc = [30 60 90 130 150 200 230 300 380 430];
peakInt = [7 1 3 10 3 6 1 8 3 10];
time = 1:450;
comp = exp(-(bsxfun(@minus,time,peakLoc')./5).^2);
sig_1 = (peakInt + rand(1,10)) * comp + rand(1,450);
sig_2 = (peakInt + rand(1,10)) * comp + rand(1,450);Задайте нелинейную функцию искривления.
wf = @(t) 1 + (t<=100).*0.01.*(t.^2) + (t>100).*...
(310+150*tanh(t./100-3));Деформируйте второй сигнал, чтобы искажать его.
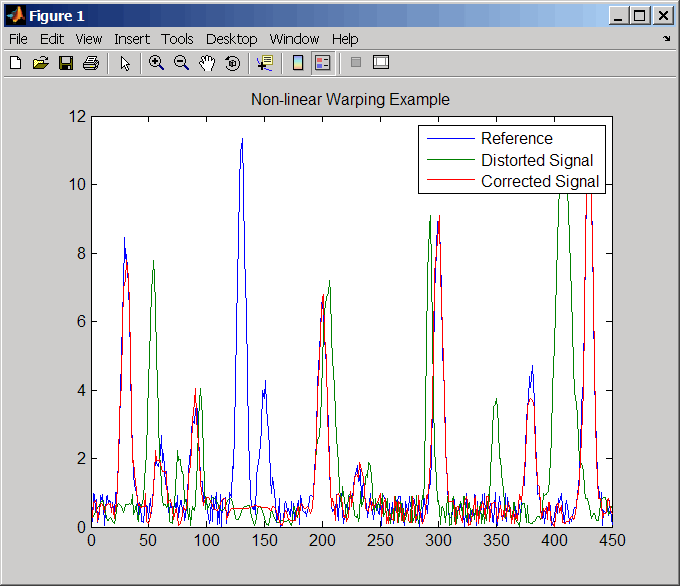
sig_2 = interp1(time,sig_2,wf(time),'pchip');Выровняйте наблюдения между двумя сигналами путем введения погрешностей.
[i,j] = samplealign([time;sig_1]',[time;sig_2]',... 'weights',[0,1],'band',35,'quantile',.5);
Постройте график опорного сигнала, искаженного сигнала и искаженного (исправленного) сигнала.
figure sig_3 = interp1(time,sig_2,interp1(i,j,time,'pchip'),'pchip'); plot(time,sig_1,time,sig_2,time,sig_3) legend('Reference','Distorted Signal','Corrected Signal') title('Non-linear Warping Example')
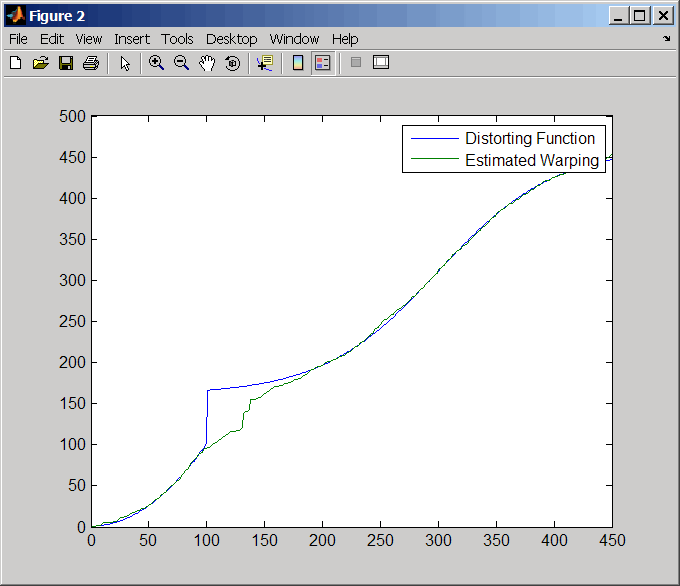
Постройте график действительных и предполагаемых функций деформации.
figure plot(time,wf(time),time,interp1(j,i,time,'pchip')) legend('Distorting Function','Estimated Warping')
Примечание
Для примеров использования указателей на функцию для Band, Gap, и Distance свойства, см. Визуализация и предварительная обработка переносимых наборов данных масс-спектрометрии для профилирования метаболитов и белков/пептидов.
[1] Майерс, К.С. и Рабинер, Л.Р. (1981). Сравнительное исследование нескольких динамических трансформаций временной шкалы алгоритмов распознавания связанных слов. Технический журнал Bell System 60:7, 1389-1409.
[2] Сакое, Х. и Чиба, С. (1978). Оптимизация алгоритма динамического программирования для распознавания разговорного слова. IEEE Trans. Acoustics, Speech and Signal Processing ASSP-26 (1), 43-49 .
msalign | msheatmap | mspalign | msppresample | msresample
