В этом разделе приводится введение в фиктивные переменные, описывается, как программное обеспечение создает их для задач классификации и регрессии, и показано, как вы можете создать фиктивные переменные при помощи dummyvar функция.
Когда вы выполняете классификационный и регрессионный анализ, часто нужно включать как непрерывные (количественные), так и категориальные (качественные) переменные. Категориальная переменная не должна быть включена в качестве числового массива. Числовые массивы имеют как порядок, так и величину. Категориальная переменная может иметь порядок (для примера, порядковая переменная), но она не имеет величины. Использование числового массива подразумевает известное «расстояние» между категориями. Подходящий способ включить категориальные предикторы - это фиктивные переменные. Чтобы задать переменные фиктива, используйте переменные индикатора, которые имеют значения 0 и 1.
Программа выбирает одну из четырех схем, чтобы задать фиктивные переменные на основе типа анализа, как описано в следующих разделах. Например, предположим, что у вас есть категориальная переменная с тремя категориями: Cool, Cooler, и Coolest.
Представление категориальной переменной с тремя категориями с использованием трех фиктивных переменных, по одной переменной для каждой категории.
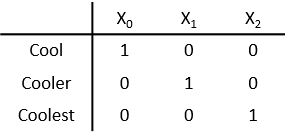
X 0 является фиктивной переменной, которая имеет 1 значений для Cool, и 0 в противном случае. X 1 является фиктивной переменной, которая имеет 1 значений для Cooler, и 0 в противном случае. X 2 является фиктивной переменной, которая имеет 1 значений для Coolest, и 0 в противном случае.
Представьте категориальную переменную с тремя категориями, используя две фиктивные переменные с ссылкой группой.
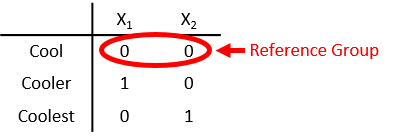
Можно различать Cool, Cooler, и Coolest использование только X 1 и X 2, без X 0. Наблюдения за Cool имеют 0 для обеих фиктивных переменных. Категория, представленная всеми 0s, является reference group.
Предположим, что математическое упорядоченное расположение категорий Cool <Cooler <Coolest. Эта схема кодирования использует 1 и -1 значения и использует больше 1с для более высоких категорий, чтобы указать упорядоченное расположение.
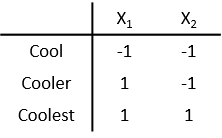
X 1 является фиктивной переменной, которая имеет 1 значений для Cooler и Coolest, и -1 для Cool. X 2 является фиктивной переменной, которая имеет 1 значений для Coolest, и -1 в противном случае.
Можно указать, что категориальная переменная имеет математическое упорядоченное расположение при помощи 'Ordinal' Аргумент пары "имя-значение" из categorical функция.
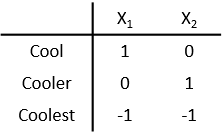
Кодирование эффектов использует 1, 0 и -1, чтобы создать фиктивные переменные. Вместо того, чтобы использовать 0 значений для представления ссылочной группы, как в Переменные Пустышки с Ссылочной Группой, кодирование эффектов использует -1, чтобы представлять последнюю категорию.
Statistics and Machine Learning Toolbox™ предлагает несколько функций классификации и регрессии подбора кривой, которые принимают категориальные предикторы. Некоторые функции аппроксимации создают фиктивные переменные для обработки категориальных предикторов.
Следующее является поведением по умолчанию для подгонки функций при идентификации категориальных предикторов.
Если данные предиктора находятся в таблице, функции предполагают, что переменная категориальна, если это логический вектор, категориальный вектор, символьный массив, строковые массивы или массив ячеек из векторов символов. Функции аппроксимации, которые используют деревья принятия решений, предполагают, что упорядоченные категориальные векторы являются непрерывными переменными.
Если данные предиктора являются матрицей, функции предполагают, что все предикторы непрерывны.
Чтобы идентифицировать любые другие предикторы как категориальные предикторы, задайте их с помощью 'CategoricalPredictors' или 'CategoricalVars' аргумент пары "имя-значение".
Функции аппроксимации обрабатывают идентифицированные категориальные предикторы следующим образом:
fitckernel, fitclinear, fitcnet, fitcsvm, fitrgp, fitrkernel, fitrlinear, fitrnet, и fitrsvm используйте две различные схемы для создания фиктивных переменных, в зависимости от того, является ли категориальная переменная неупорядоченной или упорядоченной.
Для неупорядоченной категориальной переменной функции используют Full Dummy Переменные.
Для упорядоченной категориальной переменной функции используют Фиктивные переменные для упорядоченной категориальной переменной.
Параметрические функции регрессии подбора кривой, такие как fitlm, fitglm, и fitcox Использовать фиктивные переменные с ссылочной группой. Когда функции включают фиктивные переменные, оценочные коэффициенты фиктивных переменных относятся к ссылочной группе. Для получения примера см. «Линейная регрессия с категориальным предиктором».
fitlme, fitlmematrix и fitglme позволяет вам задать схему создания фиктивных переменных при помощи 'DummyVarCoding' аргумент пары "имя-значение". Функции поддерживают три схемы: Full Dummy Переменные ('DummyVarCoding','full'), Фиктивные Переменные с ссылочной группой ('DummyVarCoding','reference') и фиктивные переменные, созданные с кодированием эффектов ('DummyVarCoding','effects'). Обратите внимание, что эти функции не предлагают аргумент пары "имя-значение" для определения категориальных переменных.
fitrm использует Фиктивные переменные, созданные с помощью кодирования эффектов.
Другие подгоняющие функции, которые принимают категориальные предикторы, используют алгоритмы, которые могут обрабатывать категориальные предикторы, не создавая фиктивных переменных.
В этом примере показано, как создать свою собственную матрицу модели переменной с помощью dummyvar функция. Эта функция принимает сгруппированные переменные и возвращает матрицу, содержащую нули и таковые, столбцы которой являются фиктивными переменными для сгруппированных переменных.
Создайте вектор-столбец категориальных данных, указывающих пол.
gender = categorical({'Male';'Female';'Female';'Male';'Female'});Создайте фиктивные переменные для gender.
dv = dummyvar(gender)
dv = 5×2
0 1
1 0
1 0
0 1
1 0
dv имеет пять строк, соответствующих количеству строк в gender и два столбца для уникальных групп, Female и Male. Порядок столбцов соответствует порядку уровней в gender. Для категориальных массивов порядок по умолчанию является возрастающим в алфавитном порядке. Вы можете проверить порядок при помощи categories функция.
categories(gender)
ans = 2x1 cell
{'Female'}
{'Male' }
Чтобы использовать фиктивные переменные в регрессионной модели, необходимо либо удалить столбец (чтобы создать ссылочную группу), либо подогнать регрессионую модель без термина точки пересечения. Для примера пола вам нужна только одна переменная, чтобы представлять два пола. Заметьте, что происходит, если вы добавляете термин точки пересечения к полной матрице проекта dv.
X = [ones(5,1) dv]
X = 5×3
1 0 1
1 1 0
1 1 0
1 0 1
1 1 0
rank(X)
ans = 2
Матрица проекта с термином точки пересечения не имеет полного ранга и не является инвертируемой. Из-за этой линейной зависимости используйте только переменные показателя c-1, чтобы представлять категориальную переменную с категориями c в регрессионной модели с термином точки пересечения.
