Детектор объектов (YOLO) v3 только один раз является многомасштабной сетью обнаружения объектов, которая использует сеть редукции данных и несколько глав обнаружения, чтобы делать предсказания в нескольких шкалах.
Модель обнаружения объектов YOLO v3 запускает сверточную нейронную сеть глубокого обучения (CNN) на входе изображении, чтобы создать сетевые предсказания из нескольких карт функции. Детектор объектов собирает и декодирует предсказания, чтобы сгенерировать ограничительные рамки.

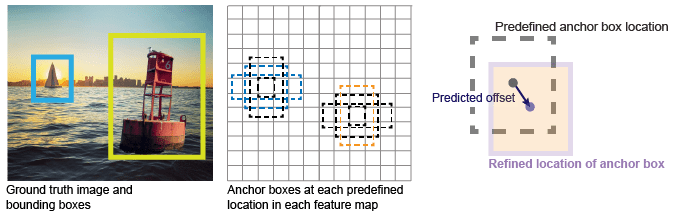
YOLO v3 использует якорные рамки для обнаружения классов объектов в изображении. Для получения дополнительной информации смотрите Якорные ящики для обнаружения объектов. YOLO v3 предсказывает эти три атрибута для каждого якорного ящика:
Пересечение над объединением (IoU) - предсказывает счет объективности каждого якорного ящика.
Смещения анкерного ящика - Уточнение положения анкерного ящика
Вероятность класса - Предсказывает метку класса, назначенную каждому якорю.
Рисунок показывает предопределенные якорные рамки (пунктирные линии) в каждом месте на карте функций и уточненном месте после применения смещений. Совпадающие поля с классом имеют цвет.
Чтобы спроектировать сеть обнаружения объектов YOLO v3, выполните следующие шаги.
Запустите модель с сетью редукции данных. Редукция данных сеть служит основе сетью для создания нейронной сети для глубокого обучения YOLO v3. Базовая сеть может быть предварительно обученной или необученной CNN. Если базовая сеть является предварительно обученной сетью, можно выполнить передача обучения.
Создайте подсети обнаружения с помощью свертки, нормализации партии . и слоев ReLu. Добавьте подсети обнаружения к любому из слоев в базовой сети. Слои выхода, которые соединяются как входы с подсетями обнаружения, являются источником сети обнаружения. Любой слой из сети редукции данных может использоваться в качестве источника сети обнаружения. Чтобы использовать многомасштабные функции для обнаружения объектов, выберите карты объектов разных размеров.
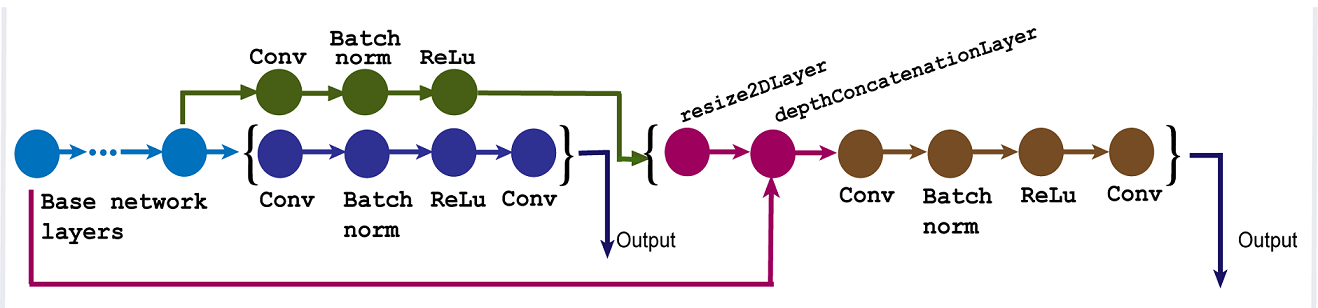
Чтобы вручную создать нейронную сеть для глубокого обучения YOLO v3, используйте Deep Network Designer (Deep Learning Toolbox) приложение. Чтобы программно создать нейронную сеть для глубокого обучения YOLO v3, используйте yolov3ObjectDetector объект.
Для выполнения передачи обучения можно использовать предварительно обученную нейронную сеть для глубокого обучения в качестве основы сети для нейронной сети для глубокого обучения YOLO v3. Настройте глубокое обучение YOLO v3 для обучения на новом наборе данных путем определения якорей и новых классов объектов. Используйте yolov3ObjectDetector объект для создания сети обнаружения YOLO v3 из любого предварительно обученного CNN, например SqueezeNet и выполните передачу обучения. Список предварительно обученных CNN см. в Pretrained Deep Neural Networks (Deep Learning Toolbox).
Чтобы узнать, как создать пользовательский детектор объектов YOLO v3 с помощью нейронной сети для глубокого обучения в качестве базовой сети и обучить обнаружению объектов, смотрите пример обнаружения объектов с использованием глубокого обучения YOLO v3.
Можно использовать Image Labeler, Video Labeler или Ground Truth Labeler (Automated Driving Toolbox) приложения для интерактивной маркировки пикселей и экспорта данных о метках для обучения. Приложения могут также использоваться для маркировки прямоугольных видимых областей (ROIs) для обнаружения объектов, меток сцен для классификации изображений и пикселей для семантической сегментации. Чтобы создать обучающие данные из любого из маркеров, экспортированных основной истиной, можно использовать objectDetectorTrainingData или pixelLabelTrainingData функций. Для получения дополнительной информации смотрите Обучающие данные для обнаружения объектов и семантической сегментации.
[1] Редмон, Джозеф и Али Фархади. «YOLO9000: Лучше, Быстрее, Сильнее». В 2017 году IEEE Conference on Компьютерное Зрение and Pattern Recognition (CVPR), 6517-25. Гонолулу, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690.
[2] Редмон, Джозеф, Сантош Диввала, Росс Гиршик и Али Фархади. «Вы смотрите только один раз: унифицированное обнаружение объектов в реальном времени». Материалы Конференции IEEE по компьютерному зрению и распознаванию шаблонов (CVPR), 779-788. Лас-Вегас, NV: CVPR, 2016.
detect | forward | predict | preprocess