Можно использовать приложение для маркировки и объекты и функции Computer Vision Toolbox™, чтобы обучить алгоритмы от достоверных данных. Используйте приложение для маркировки, чтобы в интерактивном режиме пометить достоверные данные в видео, последовательности изображений, коллекции изображений или пользовательском источнике данных. Затем используйте маркированные данные для создания обучающих данных для обучения детектора объектов или для обучения семантической сети сегментации.
Этот рабочий процесс применяется только к Image Labeler и Video Labeler приложениям. Чтобы создать обучающие данные для приложения Ground Truth Labeler (Automated Driving Toolbox) в Automated Driving Toolbox™, используйте gatherLabelData (Automated Driving Toolbox) функция.
Загрузка данных для маркировки
Image Labeler - Загрузка коллекции изображений из файла или ImageDatastore объект в приложение.
Video Labeler - Загрузка видео, последовательности изображений или пользовательского источника данных в приложение.
Пометьте данные и выберите алгоритм автоматизации: Создайте информация только для чтения и метки сцены в приложении. Для получения дополнительной информации смотрите:
Image Labeler - Запуск с Image Labeler
Video Labeler - Запуск с Video Labeler
Вы можете выбрать из одного из встроенных алгоритмов или создать свой собственный пользовательский алгоритм, чтобы пометить объекты в ваших данных. Чтобы узнать, как создать свой собственный алгоритм автоматизации, смотрите, Создают Алгоритм Автоматизации для Маркировки.
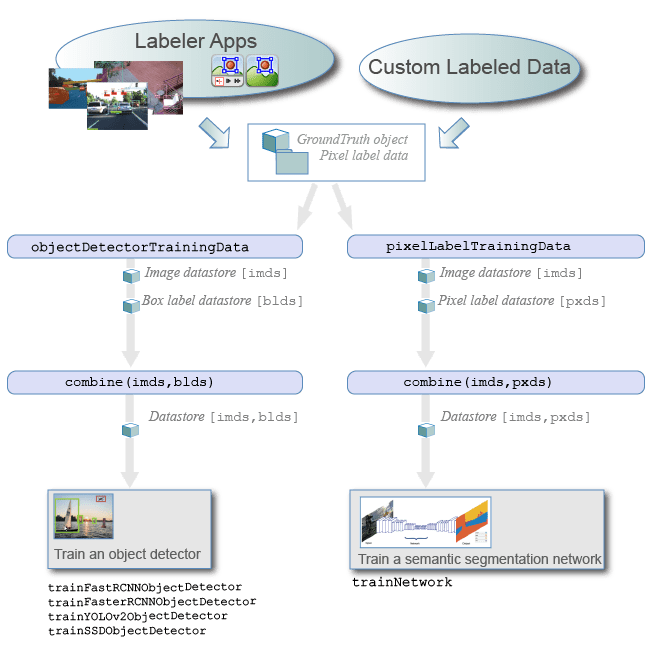
Экспорт меток: После маркировки данных можно экспортировать метки в рабочую область или сохранить их в файл. Метки экспортируются как groundTruth объект. Если источник данных состоит из нескольких коллекций изображений, пометьте весь набор коллекций изображений, чтобы получить массив groundTruth объекты. Для получения дополнительной информации об совместном использовании groundTruth объекты, см. Раздел «Совместное использование и хранение маркированные достоверные данные».
Создание обучающих данных: Чтобы создать обучающие данные из groundTruth объект, используйте одну из следующих функций:
Обучающие данные для детекторов объектов - Используйте objectDetectorTrainingData функция.
Обучающие данные для семантических сетей сегментации - Используйте pixelLabelTrainingData функция.
Для объектов, созданных с использованием видео файла или пользовательского источника данных, objectDetectorTrainingData и pixelLabelTrainingData функции записывают изображения на диск для groundTruth. Дискретизируйте достоверные данные путем определения коэффициента дискретизации. Выборка уменьшает переобучение детектора объектов на аналогичных выборках.
Алгоритм train:
Детекторы объектов - Используйте один из нескольких детекторов объектов Computer Vision Toolbox. Список детекторов см. в разделе «Обнаружение объектов». Для детекторов объектов, характерных для автоматического вождения, смотрите детекторы объектов Automated Driving Toolbox, перечисленные в Visual Perception (Automated Driving Toolbox).
Семантическая сеть сегментации - Для получения дополнительной информации о обучении семантической сети сегментации, смотрите Начало работы с семантической сегментацией с использованием глубокого обучения.
objectDetectorTrainingData | pixelLabelTrainingData | semanticseg | trainACFObjectDetector | trainFasterRCNNObjectDetector | trainRCNNObjectDetector | trainRCNNObjectDetector | trainSSDObjectDetector | trainYOLOv2ObjectDetector