Симуляция, более сглаженная из Байесовой векторной модели (VAR) авторегрессии
simsmooth хорошо подходит для усовершенствованных приложений, таких как условное прогнозирование из выборки от следующего прогнозирующего распределения модели Bayesian VAR (p), прогнозирование модели VARX(p), обвинение отсутствующего значения и оценка параметра в присутствии отсутствующих значений. Кроме того, simsmooth позволяет вам настроить сэмплер Гиббса для прогнозирования из выборки. Чтобы оценить прогнозы из выборки из модели Bayesian VAR (p), смотрите forecast.
[ возвращает 1 000 случайных ничьих векторов коэффициентов λ
CoeffDraws,SigmaDraws] = simsmooth(PriorMdl,Y)Coeff и инновационные ковариационные матрицы Σ Sigma, чертивший от апостериорного распределения, сформированного путем объединения предшествующей модели Bayesian VAR (p)
PriorMdl и данные об ответе Y.
Процедура выборки включает Байесов шаг увеличения данных, который использует Фильтр Калмана (см. Алгоритмы). Во время выборки, simsmooth непреддемонстрационные отсутствующие значения замен в Y, обозначенный NaN значения, с оценочными значениями.
[ дополнительные опции использования заданы одним или несколькими аргументами пары "имя-значение". Например, можно определить номер случайных ничьих от распределения или задать преддемонстрационные данные об ответе.CoeffDraws,SigmaDraws] = simsmooth(PriorMdl,Y,Name,Value)
[ также возвращается, оценочные значения отклика каждого чертят CoeffDraws,SigmaDraws,NaNDraws]
= simsmooth(___)NaNDraws использование любой из комбинаций входных аргументов в предыдущих синтаксисах.
[ также возвращает средний CoeffDraws,SigmaDraws,NaNDraws,YMean,YStd]
= simsmooth(___)YMean и стандартное отклонение YStd из следующего прогнозирующего распределения увеличенных данных.
Когда simulate оценивает апостериорное распределение, от которого можно чертить параметры, оно удаляет все строки в данных, которые содержат по крайней мере одно отсутствующее значение (NaN). Однако simsmooth использует Байесово увеличение данных, чтобы приписать непреддемонстрационные отсутствующие значения во время следующей оценки.
Рассмотрите 3-D модель VAR (4) для инфляции США (INFL), безработица (UNRATE), и федеральные фонды (FEDFUNDS) уровни.
\forall , серия независимых 3-D нормальных инноваций со средним значением 0 и ковариация . Примите слабое сопряженное предшествующее распределение для параметров .
Загрузите и предварительно обработайте данные
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции и стабилизируйте показатели безработицы и ставки по федеральным фондам.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3);
Несколько рядов имеют ведущий NaN значения, потому что их измерения не были доступны в то же время, что и другие измерения. Поскольку продвижение NaN значения могут вмешаться в преддемонстрационную спецификацию, удалить все строки, содержащие по крайней мере одно ведущее отсутствующее значение.
rmldDataTable = rmmissing(DataTable(:,seriesnames));
Создайте предшествующую модель
Создайте слабую сопряженную предшествующую модель путем определения большого коэффициента предшествующие отклонения. Задайте серийные имена ответа.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Случайным образом поместите отсутствующие значения в данные
Чтобы проиллюстрировать симуляцию в присутствии отсутствующих значений, случайным образом поместите отсутствующие значения в данные после преддемонстрационного периода.
rng(1) % For reproducibility T = size(rmldDataTable,1); idxpre = 1:PriorMdl.P; % Presample period idxest = (PriorMdl.P + 1):T; % Estimation period nmissing = 20; % Simulate at most nmissing missing values sidx = [randsample(idxest,nmissing,true); randsample(1:numseries,nmissing,true)]; lsidx = sub2ind([T,numseries],sidx(1,:),sidx(2,:)); MissData = table2array(rmldDataTable); MissData(lsidx) = NaN; MissDataTable = rmldDataTable; MissDataTable{:,:} = MissData;
Симулируйте параметры от следующего
Чертите 1 000 наборов параметров от апостериорного распределения путем вызова simsmooth, который оценивает апостериорное распределение параметров, и затем формирует следующее прогнозирующее распределение.
[Coeff,Sigma] = simsmooth(PriorMdl,MissDataTable.Variables);
Coeff 39 1000 матрица случайным образом чертивших векторов коэффициентов от следующего. Sigma 3 3 1 000 массивов случайным образом чертивших инновационных ковариационных матриц.
По умолчанию, simsmooth инициализирует модель VAR при помощи первых четырех наблюдений в данных.
Сопоставлять строки Coeff к коэффициентам получите сводные данные предшествующего распределения при помощи summarize. В таблице отобразите первый набор случайным образом чертивших коэффициентов с соответствующими именами.
Summary = summarize(PriorMdl,'off'); table(Coeff(:,1),'RowNames',Summary.CoeffMap)
ans=39×1 table
Var1
__________
AR{1}(1,1) 0.22109
AR{1}(1,2) -0.24034
AR{1}(1,3) 0.093315
AR{2}(1,1) 0.18329
AR{2}(1,2) -0.23178
AR{2}(1,3) -0.026301
AR{3}(1,1) 0.39991
AR{3}(1,2) 0.41141
AR{3}(1,3) 0.054702
AR{4}(1,1) 0.024944
AR{4}(1,2) -0.37372
AR{4}(1,3) -0.0095642
Constant(1) 0.21499
AR{1}(2,1) -0.073776
AR{1}(2,2) 0.36086
AR{1}(2,3) 0.071088
⋮
В качестве альтернативы можно создать эмпирическую модель из ничьих и использовать summarize отобразить модель путем определения любого параметра отображения.
Отобразите сводные данные следующих ничьих как уравнение.
EmpMdl = empiricalbvarm(numseries,numlags,'SeriesNames',seriesnames,... 'CoeffDraws',Coeff,'SigmaDraws',Sigma); summarize(EmpMdl,'equation')
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1447 -0.3685 0.1013 0.2974 -0.0959 0.0360 0.4115 0.2244 0.0474 0.0265 -0.2321 0.0030 0.1095
| (0.0744) (0.1314) (0.0370) (0.0833) (0.1509) (0.0398) (0.0833) (0.1440) (0.0403) (0.0879) (0.1301) (0.0370) (0.0744)
DUNRATE | -0.0187 0.4445 0.0314 0.0836 0.2372 0.0489 -0.0407 -0.0548 -0.0064 0.0483 -0.1753 0.0027 -0.0597
| (0.0447) (0.0808) (0.0234) (0.0514) (0.0863) (0.0230) (0.0507) (0.0906) (0.0243) (0.0514) (0.0779) (0.0225) (0.0466)
DFEDFUNDS | -0.2046 -1.1927 -0.2524 0.2864 -0.2282 -0.2657 0.2709 -0.6231 0.0289 -0.0404 0.1043 -0.1236 -0.2952
| (0.1530) (0.2931) (0.0816) (0.1832) (0.3123) (0.0857) (0.1736) (0.3105) (0.0900) (0.1866) (0.2880) (0.0758) (0.1684)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.2842 -0.0098 0.1346
| (0.0286) (0.0122) (0.0464)
DUNRATE | -0.0098 0.1062 -0.1496
| (0.0122) (0.0106) (0.0296)
DFEDFUNDS | 0.1346 -0.1496 1.3187
| (0.0464) (0.0296) (0.1422)
Полагайте, что 3-D модель VAR (4) Симулирует Параметры от Апостериорного распределения при наличии Отсутствующих значений.
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции и стабилизируйте показатели безработицы и ставки по федеральным фондам.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3);
Удалите все строки, которые содержат ведущие отсутствующие значения.
rmldDataTable = rmmissing(DataTable(:,seriesnames));
Создайте слабую сопряженную предшествующую модель. Задайте серийные имена ответа.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Случайным образом поместите отсутствующие значения в данные после преддемонстрационного периода.
rng(1) % For reproducibility T = size(rmldDataTable,1); idxpre = 1:PriorMdl.P; % Presample period idxest = (PriorMdl.P + 1):T; % Estimation period nmissing = 20; % Simulate at most nmissing missing values sidx = [randsample(idxest,nmissing,true); randsample(1:numseries,nmissing,true)]; lsidx = sub2ind([T,numseries],sidx(1,:),sidx(2,:)); MissData = table2array(rmldDataTable); MissData(lsidx) = NaN; MissDataTable = rmldDataTable; MissDataTable{:,:} = MissData;
Чертите 1 000 наборов параметров от апостериорного распределения путем вызова simsmooth. Возвратите значения, которые более сглаженная симуляция приписывает для недостающих наблюдений.
[~,~,NaNDraws] = simsmooth(PriorMdl,MissDataTable.Variables);
NaNDraws 19 1000 матрица случайным образом чертивших векторов отклика от следующего прогнозирующего распределения. Элементы соответствуют отсутствующим значениям в данных, упорядоченных постолбцовым поиском. Например, NaNDraws(3,1) первый случайным образом чертивший оценочный ответ третьего отсутствующего значения в данных. Найдите соответствующее значение в данных.
[idxi,idxj] = find(ismissing(MissDataTable),3); responsename = seriesnames(idxj(end))
responsename = "INFL"
observationtime = MissDataTable.Time(idxi(end))
observationtime = datetime
Q3-65
Постройте эмпирическое распределение оценочных значений уровня инфляции во время Q3-65.
histogram(NaNDraws(3,:))
title('Q3-65 Inflation Rate Empirical Distribution')
Полагайте, что 3-D модель VAR (4) Симулирует Параметры от Апостериорного распределения при наличии Отсутствующих значений.
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте слабую сопряженную предшествующую модель. Задайте серийные имена ответа.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Симулируйте 5 000 коэффициентов и инновационных ковариационных матриц от апостериорного распределения. Задайте электротермотренировку 1 000 и утончающийся фактор 5.
rng(1); % For reproducibility [Coeff,Sigma] = simsmooth(PriorMdl,rmDataTable{:,seriesnames},... 'NumDraws',5000,'BurnIn',1000,'Thin',5);
Coeff 39 5000 матрица коэффициентов и Sigma 3 3 5 000 массивов инновационных ковариационных матриц. Оба Coeff и Sigma случайным образом чертятся от апостериорного распределения.
Полагайте, что 3-D модель VAR (4) Симулирует Параметры от Апостериорного распределения при наличии Отсутствующих значений. В этом случае примите, что предшествующая модель полусопряжена.
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте полусопряженную предшествующую модель. Задайте серийные имена ответа.
numseries = numel(seriesnames); numlags = 4; PriorMdl = bayesvarm(numseries,numlags,'ModelType','semiconjugate',... 'SeriesNames',seriesnames);
Чтобы получить начальные значения для коэффициентов, считайте коэффициенты из модели VAR адаптированными к первым 30 наблюдениям.
Задайте наборы индекса тот раздел данные в четыре набора:
Длина p = 4 периода инициализации для динамического компонента модели
= 30 наблюдений, чтобы оценить VAR для содействующих начальных значений
Длина p = 4 периода инициализации для динамического компонента модели Bayesian VAR
Оставление наблюдения, чтобы оценить следующее
T = size(rmDataTable); n0 = 30; idxpre0 = 1:PriorMdl.P; idxest0 = (idxpre0(end) + 1):(idxpre0(end) + 1 + n0); idxpre1 = (idxest0(end) + 1 - PriorMdl.P):idxest0(end); idxest1 = (idxest0(end) + 1):T; n1 = numel(idxest1);
Получите начальные содействующие значения, подбирая модель VAR к первым 34 наблюдениям. Используйте первые четыре наблюдения в качестве предварительной выборки.
Mdl0 = varm(PriorMdl.NumSeries,PriorMdl.P);
EstMdl0 = estimate(Mdl0,rmDataTable{idxest0,seriesnames},'Y0',rmDataTable{idxpre0,seriesnames});estimate возвращает объект модели, содержащий содействующие оценки AR в матричной форме и константы в векторе. Байесовы функции VAR требуют начальных содействующих значений в векторе. Отформатируйте начальные содействующие значения.
Coeff0 = [EstMdl0.AR{:} EstMdl0.Constant].';
Coeff0 = Coeff0(:);Симулируйте 1 000 коэффициентов и инновационных ковариационных матриц от апостериорного распределения. Задайте остающиеся наблюдения, от которых можно оценить следующее. Инициализируйте модель VAR путем определения последних четырех наблюдений в предыдущей выборке оценки как предварительная выборка и задайте начальный вектор коэффициентов, чтобы инициализировать следующую выборку.
rng(1); % For reproducibility [Coeff,Sigma] = simsmooth(PriorMdl,rmDataTable{idxest1,seriesnames},... 'Y0',rmDataTable{idxpre1,seriesnames},'Coeff0',Coeff0);
Coeff 39 1000 матрица коэффициентов и Sigma 3 3 1 000 массивов инновационных ковариационных матриц. Оба Coeff и Sigma случайным образом чертятся от апостериорного распределения.
Полагайте, что 3-D модель VAR (4) Симулирует Параметры от Апостериорного распределения при наличии Отсутствующих значений.
Загрузите и предварительно обработайте данные
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте предшествующую модель
Создайте слабую сопряженную предшествующую модель. Задайте серийные имена ответа.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Предскажите ответы Используя forecast
Непосредственно предскажите два года (восемь четвертей) наблюдений от следующего прогнозирующего распределения. forecast оценивает апостериорное распределение параметров, и затем формирует следующее прогнозирующее распределение.
rng(1); % For reproducibility
numperiods = 8;
YF = forecast(PriorMdl,numperiods,rmDataTable{:,seriesnames});YF 8 3 матрица предсказанных ответов.
Постройте предсказанные ответы.
fh = rmDataTable.Time(end) + calquarters(1:8); for j = 1:PriorMdl.NumSeries subplot(3,1,j) plot(rmDataTable.Time(end - 20:end),rmDataTable{end - 20:end,seriesnames(j)},'r',... [rmDataTable.Time(end) fh],[rmDataTable{end,seriesnames(j)}; YF(:,j)],'b'); legend("Observed","Forecasted",'Location','NorthWest') title(seriesnames(j)) end

Предскажите ответы Используя simsmooth
Сконфигурируйте набор данных для получения прогнозов от simsmooth путем конкатенации numperiods- numseries расписание отсутствующих значений в конец набора.
fTT = array2timetable(NaN(numperiods,numseries),'RowTimes',fh,... 'VariableNames',seriesnames); frmDataTable = [rmDataTable(:,seriesnames); fTT]; tail(frmDataTable)
ans=8×3 timetable
Time INFL DUNRATE DFEDFUNDS
_____ ____ _______ _________
Q2-09 NaN NaN NaN
Q3-09 NaN NaN NaN
Q4-09 NaN NaN NaN
Q1-10 NaN NaN NaN
Q2-10 NaN NaN NaN
Q3-10 NaN NaN NaN
Q4-10 NaN NaN NaN
Q1-11 NaN NaN NaN
Предскажите модель VAR с помощью simsmooth. Как forecast, simsmooth оценивает апостериорное распределение, таким образом, оно требует предшествующей модели и данных. Задайте данные, содержащие запаздывающий NaNs.
[~,~,~,YMean] = simsmooth(PriorMdl,frmDataTable.Variables);
YMean почти равно frmDataTable, за этими исключениями:
YMean исключает строки, соответствующие преддемонстрационному периоду frmDataTable(1:4,:).
Если frmDataTable(j,k) isnan, YMean(j,k) среднее значение следующего прогнозирующего распределения ответа k во время j.
Создайте расписание из YMean.
YMeanTT = array2timetable(YMean,'RowTimes',frmDataTable.Time((PriorMdl.P + 1):end),... 'VariableNames',seriesnames);
Постройте предсказанные ответы.
for j = 1:PriorMdl.NumSeries subplot(3,1,j) plot(YMeanTT.Time((end - 20 - numperiods):(end - numperiods)),YMeanTT{(end - 20 - numperiods):(end - numperiods),j},'r',... YMeanTT.Time((end - numperiods):end),YMeanTT{(end - numperiods):end,j},'b'); legend("Observed","Forecasted",'Location','NorthWest') title(seriesnames(j)) end

Полагайте, что 3-D модель VAR (4) Симулирует Параметры от Апостериорного распределения при наличии Отсутствующих значений.
Загрузите США макроэкономический набор данных. Вычислите уровень инфляции, стабилизируйте показатели безработицы и ставки по федеральным фондам, и удалите отсутствующие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте слабую сопряженную предшествующую модель. Задайте серийные имена ответа.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Условное прогнозирование происходит, когда значения отклика известны или выдвинули гипотезу в горизонте прогноза, и неизвестные значения предсказаны обусловленные на известных значениях. Предположим что изменение уровня безработицы (DUNRATE) остается на уровне одного процентного пункта через горизонт прогноза 2D года.
Сконфигурируйте набор данных для получения прогнозов от simsmooth путем конкатенации numperiods- numseries расписание отсутствующих значений в конец набора. Для изменения уровня безработицы замените отсутствующие значения на вектор из единиц.
rng(1); % For reproducibility numperiods = 8; fh = rmDataTable.Time(end) + calquarters(1:8); fTT = array2timetable(NaN(numperiods,numseries),'RowTimes',fh,... 'VariableNames',seriesnames); frmDataTable = [rmDataTable(:,seriesnames); fTT]; frmDataTable.DUNRATE((end - numperiods + 1):end) = ones(numperiods,1); tail(frmDataTable)
ans=8×3 timetable
Time INFL DUNRATE DFEDFUNDS
_____ ____ _______ _________
Q2-09 NaN 1 NaN
Q3-09 NaN 1 NaN
Q4-09 NaN 1 NaN
Q1-10 NaN 1 NaN
Q2-10 NaN 1 NaN
Q3-10 NaN 1 NaN
Q4-10 NaN 1 NaN
Q1-11 NaN 1 NaN
Получите прогнозы для уровня инфляции и ряда изменения ставки по федеральным фондам, учитывая, что изменение уровня безработицы один для целого горизонта.
[~,~,~,YMean] = simsmooth(PriorMdl,frmDataTable.Variables);
YMean почти равно frmDataTable, за этими исключениями:
YMean исключает строки, соответствующие преддемонстрационному периоду frmDataTable(1:4,:).
Если frmDataTable(j,k) isnan, YMean(j,k) среднее значение следующего прогнозирующего распределения ответа k во время j.
Создайте расписание из YMean.
YMeanTT = array2timetable(YMean,'RowTimes',frmDataTable.Time((PriorMdl.P + 1):end),... 'VariableNames',seriesnames);
Постройте предсказанные ответы.
for j = 1:PriorMdl.NumSeries subplot(3,1,j) plot(YMeanTT.Time((end - 20 - numperiods):(end - numperiods)),YMeanTT{(end - 20 - numperiods):(end - numperiods),j},'r',... YMeanTT.Time((end - numperiods):end),YMeanTT{(end - numperiods):end,j},'b'); legend("Observed","Forecasted",'Location','NorthWest') title(seriesnames(j)) end

Считайте 2D модель VARX(1) для США действительным GDP (RGDP) и инвестиции (GCE) уровни, который обрабатывает персональное потребление (PCEC) уровень как внешний:
\forall , серия независимых 2D нормальных инноваций со средним значением 0 и ковариация . Примите следующие предшествующие распределения:
, где M 4 2 матрица средних значений и матрица шкалы среди коэффициента 4 на 4. Эквивалентно, .
где Ω является матрицей шкалы 2 на 2 и степени свободы.
Загрузите США макроэкономический набор данных. Вычислите действительный GDP, инвестиции и персональный ряд нормы потребления. Удалите все отсутствующие значения из получившегося ряда.
load Data_USEconModel DataTable.RGDP = DataTable.GDP./DataTable.GDPDEF; seriesnames = ["PCEC"; "RGDP"; "GCE"]; rates = varfun(@price2ret,DataTable,'InputVariables',seriesnames); rates = rmmissing(rates); rates.Properties.VariableNames = seriesnames;
Создайте сопряженную предшествующую модель для 2D VARX (1) параметры модели.
numseries = 2; numlags = 1; numpredictors = 1; PriorMdl = conjugatebvarm(numseries,numlags,'NumPredictors',numpredictors,... 'SeriesNames',seriesnames(2:end));
Создайте наборы индекса тот раздел данные в выборки прогноза и оценку. Задайте горизонт прогноза двух лет.
T = size(rates,1);
numperiods = 8;
idxest = 1:(T - numperiods); % Includes presample
idxf = (T - numperiods + 1):T;
idxtot = [idxest idxf];Симуляция более сглаженные прогнозы путем приписывания отсутствующих значений. Поэтому создайте набор данных, который содержит отсутствующие значения для ответов в горизонте прогноза.
missingrates = rates;
missingrates{idxf,PriorMdl.SeriesNames} = nan(numperiods,PriorMdl.NumSeries);Предскажите ответы в горизонте прогноза. Задайте преддемонстрационные наблюдения и внешние данные о предикторе. Возвратите стандартные отклонения следующего прогнозирующего распределения.
rng(1) % For reproducibility [~,~,~,YMean,YStd] = simsmooth(PriorMdl,missingrates{:,PriorMdl.SeriesNames},... 'X',missingrates{:,seriesnames(1)});
Создайте расписание из YMean.
YMeanTT = array2timetable(YMean,'RowTimes',rates.Time((PriorMdl.P + 1):end),... 'VariableNames',PriorMdl.SeriesNames);
Постройте предсказанные ответы.
for j = 1:PriorMdl.NumSeries subplot(PriorMdl.NumSeries,1,j) plot(rates.Time((end - 20):end),rates{(end - 20):end,PriorMdl.SeriesNames(j)},'r',... YMeanTT.Time((end - numperiods):end),YMeanTT{(end - numperiods):end,PriorMdl.SeriesNames(j)},'b'); legend("Observed","Forecasted",'Location','NorthWest') title(PriorMdl.SeriesNames(j)) end

Симуляция Монте-Карло подвергается изменению. Если simsmooth симуляция Монте-Карло использования, затем оценивает, и выводы могут варьироваться, когда вы вызываете simsmooth многократно при на вид эквивалентных условиях. Чтобы воспроизвести результаты оценки, установите seed случайных чисел при помощи rng перед вызовом simsmooth.
Этот рисунок показывает как simsmooth уменьшает выборку при помощи значений NumDraws, Thin, и BurnIn. Прямоугольники представляют последовательные ничьи от распределения. simsmooth удаляет белые прямоугольники из выборки. Остающийся NumDraws черные прямоугольники составляют выборку.
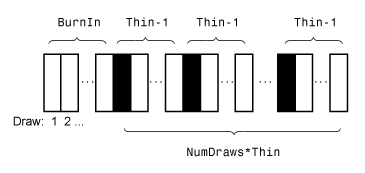
simsmooth не возвращает начальные значения по умолчанию, которые это генерирует.
[1] Литтермен, Роберт Б., "Предсказывающий с Байесовыми Векторными Авторегрессиями: Пять Лет опыта". Журнал Бизнес-и Экономической статистики 4, № 1 (январь 1986): 25–38. https://doi.org/10.2307/1391384.
