Цель моделей регрессии состоит в том, чтобы описать переменную отклика в зависимости от независимых переменных. Модели многофакторной линейной регрессии описывают ответ как линейную комбинацию коэффициентов и функции независимых переменных. Нелинейность может быть смоделирована с помощью нелинейных функций независимых переменных. Однако коэффициенты всегда вводят модель в линейный вид.
Нелинейные модели регрессии являются большим количеством механистических моделей нелинейных отношений между переменными отклика и независимыми переменными. Параметры могут ввести модель как экспоненциальную, тригонометрическую, степень или любая другая нелинейная функция. Неизвестные параметры в модели оцениваются путем минимизации статистического критерия, такого как отрицательная логарифмическая вероятность или сумма отклонений в квадрате между наблюдаемыми и ожидаемыми значениями.
В случае фармакокинетического (PK) учатся, данные об ответе обычно представляют некоторые измеренные концентрации препарата, и независимые переменные часто являются дозой и время. Нелинейная функция, часто используемая для таких данных, является показательной функцией, поскольку много наркотиков, однажды распределенных в пациенте, устраняются экспоненциальным способом. Один параметр PK, чтобы оценить в этом случае является уровнем, на котором препарат устраняется из тела, учитывая данные концентрация-время.
Например, считайте данные о концентрации плазмы препарата от одного индивидуума после внутривенной дозы шарика измеренными в различных моментах времени с некоторыми ошибками. Примите, что измеренная концентрация препарата следует за моноэкспоненциальным снижением: .
Эта модель описывает ход времени концентрации препарата в теле (Ct), в зависимости от концентрации препарата после внутривенной дозы шарика в t = 0 (C0), время (t) и параметр уровня устранения (ke). ε является средним нулем и переменной модульного отклонения, то есть, представление погрешности измерения и a является ошибочным параметром модели (здесь, стандартное отклонение).
Более в общем можно записать модель как
где yi является i th ответ (такой как концентрация препарата), f является функцией времени t и параметры модели p (такие как ke), и ошибочная модель .
Эта таблица суммирует нелинейные опции регрессии, доступные в SimBiology®.
| Подбор кривой опции | Пример |
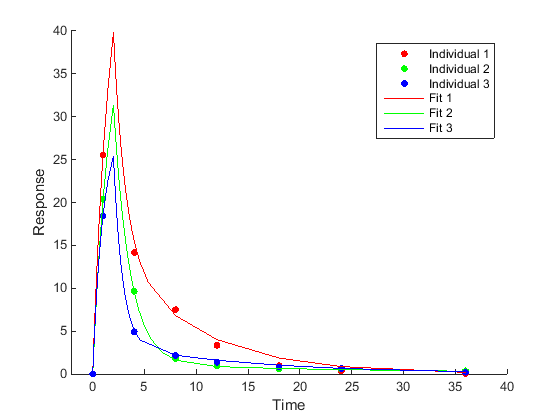
Отдельно-специфичная оценка параметра (Необъединенный подбор кривой) Соответствуйте каждому индивидууму отдельно, приводя к одному набору оценок параметра для каждого индивидуума. |
|
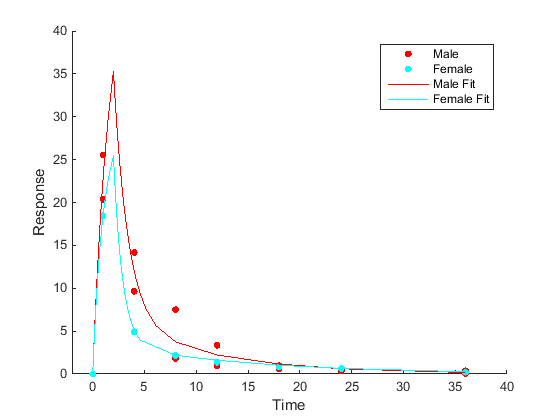
Категория - или специфичная для группы оценка параметра Соответствуйте каждой категории или группе отдельно, приводя к одному набору оценок параметра для каждой категории. |
|
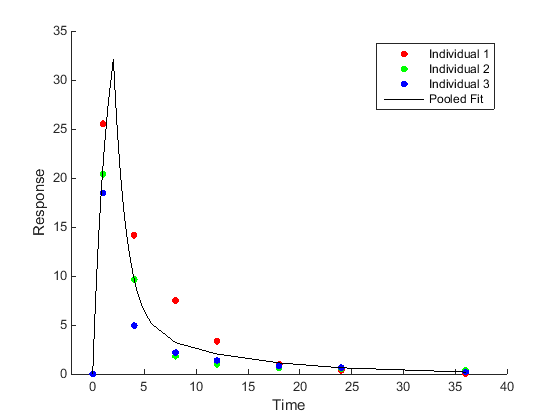
Оценка параметра всего населения (Объединенный подбор кривой) Соответствуйте всем данным, объединенным вместе, приводя ко всего одному набору оценок параметра. |
|
Кроме того, SimBiology поддерживает четыре вида ошибочных моделей для измеренных или наблюдаемых ответов, а именно, постоянный (значение по умолчанию), пропорциональное, объединенное, и экспоненциал. Для получения дополнительной информации см. Ошибочные Модели. В зависимости от метода оптимизации можно задать ошибочную модель для каждого ответа или всех ответов. Для получения дополнительной информации см. Поддерживаемые Методы для Оценки Параметра SimBiology.
SimBiology поддерживает три преобразования параметра. Эти преобразования параметра могут быть полезными, чтобы улучшить подходящую сходимость или осуществить границы параметра.
Общая модель, объясненная ранее, , где p является параметрами модели, которые можно преобразовать. Рассмотрите следующие два уравнения.
Здесь, представляет преобразованные параметры модели, p представляет непреобразованные параметры модели, T преобразование и T-1 обратное преобразование.
SimBiology выполняет оценку параметра с помощью преобразованных параметров β, что означает что преобразованная модель используется, где F функция модели с помощью преобразованных параметров. Эквивалентно, функция модели может быть переписана как .
Другими словами, оптимизатор SimBiology использует преобразованные значения во время оценки наибольшего правдоподобия, но результат подгонки, о котором сообщают, вернулся назад на пробел модели (непреобразованные значения). Например, если вы оцениваете параметр разрешения Cl, который преобразовывается в журнал, у вас есть Clβ = журнал (Cl), где Clβ - то, что использование оптимизатора и Cl то, что видит модель.
Определение преобразований параметра налагает неявные границы на непреобразованные значения параметров. log преобразование сохраняет значение параметров, чтобы быть всегда положительным, и logit и probit преобразования сохраняют значение параметров к между 0 и 1. В качестве альтернативы можно задать дальнейшие ограничения на значения параметров путем обеспечения явных границ для непреобразованных параметров p или для преобразованных параметров β.
| Преобразование | Преобразованный параметр и область значений † | Непреобразованный параметр и область значений ‡ | Описание |
|---|---|---|---|
| Во многих случаях, Применение | ||
logit |
| ||
probit | Подобно
|
† Используйте InitialTransformedValue и TransformedBounds свойства EstimatedInfo object устанавливать начальную букву преобразовало значение и преобразовало границы к желаемому подмножеству области значений.
‡ используют InitialValue и Bounds свойства EstimatedInfo object устанавливать начальную букву непреобразованное значение и непреобразованные границы к желаемому подмножеству области значений.
SimBiology оценивает параметры методом наибольшего правдоподобия. Вместо того, чтобы непосредственно максимизировать функцию правдоподобия, SimBiology создает эквивалентную проблему минимизации. Каждый раз, когда возможно, оценка формулируется как оптимизация метода взвешенных наименьших квадратов (WLS), которая минимизирует сумму квадратов взвешенных остаточных значений. В противном случае оценка формулируется как минимизация отрицания логарифма вероятности (NLL). Формулировка WLS часто сходится лучше, чем формулировка NLL, и SimBiology может использовать в своих интересах специализированные алгоритмы WLS, такие как алгоритм Levenberg-Marquardt, реализованный в lsqnonlin и lsqcurvefit. SimBiology использует WLS, когда существует одна ошибочная модель, которая является постоянной, пропорциональной, или экспоненциальной. SimBiology использует NLL, если у вас есть объединенная ошибочная модель или модель нескольких-ошибок, то есть, модель, имеющая ошибочную модель для каждого ответа.
sbiofit поддерживает различные методы оптимизации и передает в сформулированном WLS или выражении NLL к методу оптимизации, который минимизирует его. Для простоты каждое выражение, показанное ниже, принимает только одну ошибочную модель и один ответ. Если существуют множественные ответы, SimBiology берет сумму выражений, которые соответствуют ошибочным моделям данных ответов.
| Выражение, которое минимизируется | |
|---|---|
| Метод взвешенных наименьших квадратов (WLS) | Для постоянной ошибочной модели, |
| Для пропорциональной ошибочной модели, | |
| Для экспоненциальной ошибочной модели, | |
| Для числовых весов, | |
| Отрицательная логарифмическая правдоподобность (NLL) | Для объединенной ошибочной модели и модели нескольких-ошибок, |
Переменные определяются следующим образом.
N | Количество экспериментальных наблюдений |
yi | i th экспериментальное наблюдение |
Ожидаемое значение i th наблюдение | |
Стандартное отклонение i th наблюдение.
| |
Вес i th ожидаемое значение | |
Когда вы используете числовые веса или функцию веса, веса приняты, чтобы быть обратно пропорциональными отклонению ошибки, то есть, где a является постоянным параметром ошибок. Если вы используете веса, вы не можете задать ошибочную модель кроме постоянной ошибочной модели.
Различные методы оптимизации имеют различные требования к функции, которая минимизируется. Для некоторых методов оценка параметров модели выполняется независимо от оценки ошибочных параметров модели. Следующая таблица обобщает ошибочные модели и любые отдельные формулы, используемые для оценки ошибочных параметров модели, где a и b являются ошибочными параметрами модели, и e является стандартным средним нулем и переменной (Gaussian) модульного отклонения.
| Ошибочная модель | Функция оценки параметра ошибок |
|---|---|
'constant': | |
'exponential': | |
'proportional': | |
'combined': | Параметры ошибок включены в минимизацию. |
| Веса |
Примечание
nlinfit только поддержите одну ошибочные модели, не модели нескольких-ошибок, то есть, специфичные для ответа ошибочные модели. Для объединенной ошибочной модели это использует итеративный алгоритм WLS. Для других ошибочных моделей это использует алгоритм WLS, аналогичный описанному ранее. Для получения дополнительной информации смотрите nlinfit (Statistics and Machine Learning Toolbox).
Следующие шаги показывают один из рабочих процессов, которые можно использовать в командной строке, чтобы подбирать модель PK.
Преобразуйте данные в groupedData формат.
Задайте данные о дозировании. Для получения дополнительной информации смотрите Дозы в Моделях SimBiology.
Создайте структурную модель (одна - 2D, или модель мультиотсека). Для получения дополнительной информации смотрите, Создают Фармакокинетические Модели.
Сопоставьте переменную отклика от данных до компонента модели. Например, если вы имеете измеренные данные о концентрации препарата для центрального отсека, затем сопоставляете его с разновидностями препарата в центральном отсеке (обычно Drug_Central разновидности).
Задайте параметры, чтобы оценить использование EstimatedInfo object. Опционально, можно задать преобразования параметра, начальные значения и границы параметра.
Выполните использование оценки параметра sbiofit или fitproblem.
Для проиллюстрированных примеров смотрите следующее.
sbiofit | groupedData | EstimatedInfo object | sbiofitmixed