

Программное обеспечение Reinforcement Learning Toolbox™ обеспечивает несколько предопределенных сред системы управления, для которых уже заданы действия, наблюдения, вознаграждения и динамика. Можно использовать эти среды для:
Изучите концепции изучения укрепления
Получите знакомство с программными функциями Reinforcement Learning Toolbox
Протестируйте свои собственные агенты изучения укрепления
Можно загрузить следующие предопределенные среды системы управления MATLAB® с помощью функции rlPredefinedEnv.
| Среда | Задача агента |
|---|---|
| Полюсный корзиной | Сбалансируйте полюс на движущейся корзине, прикладывая силы к корзине с помощью или дискретного или непрерывного пробела действия. |
| Двойной интегратор | Управляйте динамической системой второго порядка с помощью или дискретного или непрерывного пробела действия. |
| Математический маятник с наблюдением изображений | Swing и баланс математический маятник с помощью или дискретного или непрерывного пробела действия. |
Можно также загрузить, предопределил среды мира сетки MATLAB. Для получения дополнительной информации смотрите Загрузку Предопределенные Среды Мира Сетки.
Цель агента в предопределенных полюсных корзиной средах состоит в том, чтобы сбалансировать полюс на движущейся корзине, прикладывая горизонтальные силы к корзине. Полюс рассматривается успешно сбалансированным, если оба из следующих условий удовлетворены:
Угол полюса остается в данном пороге вертикального положения, где вертикальное положение является нулевыми радианами.
Значение положения корзины остается ниже данного порога.
Существует два полюсных корзиной варианта среды, которые отличаются пробелом действия агента.
Дискретный — Агент может прикладывать силу или Fmax или-Fmax к корзине, где Fmax является свойством MaxForce среды.
Непрерывный — Агент может прикладывать любую силу в области значений [-Fmax, Fmax].
Чтобы создать полюсную корзиной среду, используйте функцию rlPredefinecdEnv.
Дискретный пробел действия
env = rlPredefinedEnv('CartPole-Discrete');Непрерывный пробел действия
env = rlPredefinedEnv('CartPole-Continuous');Можно визуализировать полюсную корзиной среду с помощью функции plot. График отображает корзину как синий квадрат и полюс как красный прямоугольник.
plot(env)
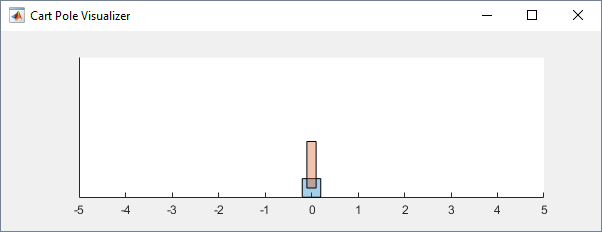
Чтобы визуализировать среду во время обучения, вызовите plot перед обучением и следите за открытой фигурой визуализации.
Для примеров, которые обучают агенты в полюсных корзиной средах, см.:
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
Gravity | Ускорение из-за силы тяжести в метрах в секунду | 9.8 |
MassCart | Масса корзины в килограммах | 1 |
MassPole | Масса полюса в килограммах | 0.1 |
Length | Половина длины полюса в метрах | 0.5 |
MaxForce | Максимальная горизонталь обеспечивает значение в ньютонах | 10 |
Ts | Шаг расчета в секундах | 0.02 |
ThetaThresholdRadians | Угловой порог полюса в радианах | 0.2094 |
XThreshold | Порог положения корзины в метрах | 2.4 |
RewardForNotFalling | Вознаградите за каждый временной шаг, полюс сбалансирован | 1 |
PenaltyForFalling | Вознаградите штраф за то, чтобы не удаваться сбалансировать полюс | Дискретный: Непрерывный: |
State | Состояние среды, заданное как вектор-столбец со следующими переменными состояния:
| [0 0 0 0]' |
В полюсных корзиной средах агент взаимодействует со средой с помощью одного сигнала действия, горизонтальная сила применилась к корзине. Среда содержит объект спецификации для этого сигнала действия. Для среды с a:
Дискретный пробел действия, спецификация является объектом rlFiniteSetSpec.
Непрерывный пробел действия, спецификация является объектом rlNumericSpec.
Для получения дополнительной информации о получении спецификаций действия от среды смотрите getActionInfo.
В полюсной корзиной системе агент может наблюдать все переменные состояния среды в env.State. Для каждой переменной состояния среда содержит спецификацию наблюдения rlNumericSpec. Все состояния непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдений от среды смотрите getObservationInfo.
Премиальный сигнал для этой среды состоит из двух компонентов:
Положительное вознаграждение за каждый временной шаг, что полюс сбалансирован; то есть, корзина и полюс оба остаются в их заданных пороговых областях значений. Это вознаграждение накапливается по целому учебному эпизоду. Чтобы управлять размером этого вознаграждения, используйте свойство RewardForNotFalling среды.
Однократный отрицательный штраф, если или полюс или корзина перемещаются за пределами их пороговых областей значений. На данном этапе учебные остановки эпизода. Чтобы управлять размером этого штрафа, используйте свойство PenaltyForFalling среды.
Цель агента в предопределенных двойных средах интегратора состоит в том, чтобы управлять положением массы в системе второго порядка путем применения входа силы. А именно, система второго порядка является двойным интегратором с усилением.
Учебные эпизоды для этих сред заканчиваются, когда любое из следующих событий имеет место:
Масса перемещается вне данного порога от источника.
Норма вектора состояния является меньше, чем данный порог.
Существует два двойных варианта среды интегратора, которые отличаются пробелом действия агента.
Дискретный — Агент может прикладывать силу или Fmax или-Fmax к корзине, где Fmax является свойством MaxForce среды.
Непрерывный — Агент может прикладывать любую силу в области значений [-Fmax, Fmax].
Чтобы создать двойную среду интегратора, используйте функцию rlPredefinedEnv.
Дискретный пробел действия
env = rlPredefinedEnv('DoubleIntegrator-Discrete');Непрерывный пробел действия
env = rlPredefinedEnv('DoubleIntegrator-Continuous');Можно визуализировать двойную среду интегратора с помощью функции plot. График отображает массу как красный прямоугольник.
plot(env)
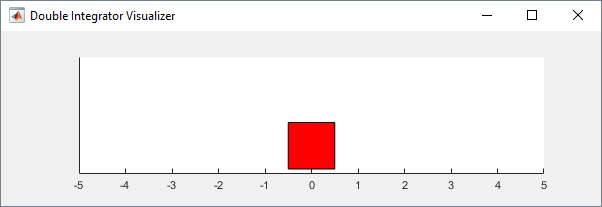
Чтобы визуализировать среду во время обучения, вызовите plot перед обучением и следите за открытой фигурой визуализации.
Для примеров, которые обучают агенты в двойных средах интегратора, см.:
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
Gain | Получите для двойного интегратора | 1 |
Ts | Шаг расчета в секундах | 0.1 |
MaxDistance | Порог значения расстояния в метрах | 5 |
GoalThreshold | Порог нормы состояния | 0.01 |
Q | Матрица веса для компонента наблюдения премиального сигнала | [10 0; 0 1] |
R | Матрица веса для компонента действия премиального сигнала | 0.01 |
MaxForce | Максимальная входная сила в ньютонах | Дискретный: Непрерывный: |
State | Состояние среды, заданное как вектор-столбец со следующими переменными состояния:
| [0 0]' |
В двойных средах интегратора агент взаимодействует со средой с помощью одного сигнала действия, сила применилась к массе. Среда содержит объект спецификации для этого сигнала действия. Для среды с a:
Дискретный пробел действия, спецификация является объектом rlFiniteSetSpec.
Непрерывный пробел действия, спецификация является объектом rlNumericSpec.
Для получения дополнительной информации о получении спецификаций действия от среды смотрите getActionInfo.
В двойной системе интегратора агент может наблюдать обе из переменных состояния среды в env.State. Для каждой переменной состояния среда содержит спецификацию наблюдения rlNumericSpec. Оба состояния непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдения от среды смотрите getObservationInfo.
Премиальный сигнал для этой среды является дискретным временем, эквивалентным из следующего непрерывно-разового вознаграждения, которое походит на функцию стоимости контроллера LQR.
Здесь:
Q и R являются свойствами среды.
x является вектором состояния среды.
u является входной силой.
Это вознаграждение является эпизодическим вознаграждением; то есть, совокупное вознаграждение через целый учебный эпизод.
Эта среда является простым лишенным трения маятником, который первоначально зависает в нисходящем положении. Учебная цель состоит в том, чтобы заставить маятник стоять вертикально, не запинаясь за использование и падая минимального усилия по управлению.
Существует два варианта среды математического маятника, которые отличаются пробелом действия агента.
Дискретный — Агент может применить крутящий момент -2, -1, 0, 1 или 2 к маятнику.
Непрерывный — Агент может применить любой крутящий момент в области значений [-2, 2].
Чтобы создать среду математического маятника, используйте функцию rlPredefinedEnv.
Дискретный пробел действия
env = rlPredefinedEnv('SimplePendulumWithImage-Discrete');Непрерывный пробел действия
env = rlPredefinedEnv('SimplePendulumModelWithImage-Continuous');Для примеров, которые обучают агент в этой среде, см.:
| Свойство | Описание | Значение по умолчанию |
|---|---|---|
Mass | Масса маятника | 1 |
RodLength | Длина маятника | 1 |
RodInertia | Момент маятника инерции | 0 |
Gravity | Ускорение из-за силы тяжести в метрах в секунду | 9.81 |
DampingRatio | Затухание на движении маятника | 0 |
MaximumTorque | Максимальный входной крутящий момент в Ньютонах | 2 |
Ts | Шаг расчета в секундах | 0.05 |
State | Состояние среды, заданное как вектор-столбец со следующими переменными состояния:
| [0 0 ]' |
Q | Матрица веса для компонента наблюдения премиального сигнала | [1 0;0 0.1] |
R | Матрица веса для компонента действия премиального сигнала | 1e-3 |
В средах математического маятника агент взаимодействует со средой с помощью одного сигнала действия, крутящий момент, примененный в основе маятника. Среда содержит объект спецификации для этого сигнала действия. Для среды с a:
Дискретный пробел действия, спецификация является объектом rlFiniteSetSpec.
Непрерывный пробел действия, спецификация является объектом rlNumericSpec.
Для получения дополнительной информации о получении спецификаций действия от среды смотрите getActionInfo.
В среде математического маятника агент получает следующие сигналы наблюдения
50 50 полутоновое изображение положения маятника
Производная угла маятника
Для каждого сигнала наблюдения среда содержит спецификацию наблюдения rlNumericSpec. Все наблюдения непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдения от среды смотрите getObservationInfo.
Премиальный сигнал для этой среды:
Здесь:
θt является углом маятника смещения от вертикального положения.
производная угла маятника.
ut-1 является усилием по управлению от предыдущего временного шага.