статистика::Функция вероятности конечного выборочного пространства
Блокноты MuPAD® будут демонтированы в будущем релизе. Используйте live скрипты MATLAB® вместо этого.
Live скрипты MATLAB поддерживают большую часть функциональности MuPAD, хотя существуют некоторые различия. Для получения дополнительной информации смотрите, Преобразовывают Notebook MuPAD в Live скрипты MATLAB.
stats::finitePF([x1, x2, …], [p1, p2, …]) stats::finitePF([[x1, p1], [x2, p2], …]) stats::finitePF(n, <c1, c2>) stats::finitePF(n, <[c1, c2]>)
stats::finitePF([x1, x2, …, xn], [p1, p2, …, pn]) возвращает процедуру, представляющую функцию вероятности
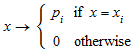
из выборочного пространства, данного по условию x1, x2, … с вероятностями p1, p2, ….
Процедура f := stats::finitePF([x1, x2, …], [p1, p2, …]) может быть названа в форме f(x) с арифметическим выражением x или наборами списков таких выражений.
Если x является выражением, которое содержится в данных x1, x2, …, то соответствующее значение вероятности возвращено.
Если x является выражением, которое не содержится в данных x1, x2, …, то 0 возвращен.
Если x является набором, сумма значений вероятности ее элементов возвращена.
Если x является списком, он обработан как набор (т.е. дублирующиеся записи в x устраняются). Сумма значений вероятности элементов в x возвращена.
Если все значения вероятности, p1, p2, … является числовым, они должны составить в целом 1. В противном случае ошибка повышена. Cf. Пример 4.
Дублирующиеся элементы данных автоматически объединены к одному элементу данных, сложение соответствующих значений вероятности. Cf. Пример 5.
stats::finitePF обобщает stats::empiricalPF, который принимает равновероятные данные. Для числовых данных x1, x2, … вызов stats::finitePF([x_1, dots, x_n], [1/n, dots, 1/n]) соответствует stats::empiricalPF([x1, …, xn]).
Мы демонстрируем основное использование этой функции:
f := stats::finitePF([1, x, y, PI], [1/4, px, py, 0.25]): f(0), f(1), f(1.0), f(x), f(y), f(PI), f(float(PI)), f(10)
![]()
Также данные могут быть переданы как список:
f := stats::finitePF([[1, 1/4], [x, px], [y, py], [PI, 0.25]]): f(0), f(1), f(1.0), f(x), f(y), f(PI), f(float(PI)), f(10)
![]()
delete f:
Мы создаем выборку типа stats::sample, состоящий из одного столбца строки и двух столбцов нестроки:
s := stats::sample( [["1996", 1242, 2/5], ["1997", 1353, 0.1], ["1998", 1142, 0.2], ["1999", 1201, 0.2], ["2001", 1201, 0.1]])
"1996" 1242 2/5 "1997" 1353 0.1 "1998" 1142 0.2 "1999" 1201 0.2 "2001" 1201 0.1
Мы используем данные в первом и третьем столбце:
f := stats::finitePF(s, 1, 3):
f("1995"), f("1998"), f("2000"), f("2001")![]()
delete s, f:
Мы полагаем, что загруженное умирает:
f:= stats::finitePF([1, 2, 3, 4, 5, 6],
[0.1, 0.1, 0.1, 0.2, 0.2, 0.3]):Какова вероятность, что бросающий умирание производит счет, больше чем или равный 4?
f({4, 5, 6})![]()
delete f:
Значения вероятности должны составить в целом 1:
stats::finitePF([Head, TAIL], [0.45, 0.54]):
Error: Probabilities do not add up to 1. [stats::finitePF]
Дублирующиеся элементы данных автоматически объединены к одному элементу данных, сложение соответствующих значений вероятности:
f:= stats::finitePF([x1, x2, x1, x2], [0.1, 0.2, 0.3, 0.4]): f(x1), f(x2)
![]()
delete f:
|
Статистические данные: произвольные объекты MuPAD® |
|
Значения вероятности: арифметические выражения |
|
Выборка доменного типа |
|
Индексы столбца демонстрационного |
