статистика::Тест качества подгонки Кольмогорова-Смирнова
Блокноты MuPAD® будут демонтированы в будущем релизе. Используйте live скрипты MATLAB® вместо этого.
Live скрипты MATLAB поддерживают большую часть функциональности MuPAD, хотя существуют некоторые различия. Для получения дополнительной информации смотрите, Преобразовывают Notebook MuPAD в Live скрипты MATLAB.
stats::ksGOFT(x1, x2, …,CDF = f) stats::ksGOFT([x1, x2, …],CDF = f) stats::ksGOFT(s, <c>,CDF = f)
stats::ksGOFT ([x 1, x 2, …], CDF = f) применяет тест качества подгонки Кольмогорова-Смирнова для нулевой гипотезы: “x 1, x 2, … является f - распределенная выборка”.
Внешние статистические данные, сохраненные в ASCII-файле, могут быть импортированы в сеанс MuPAD® через import::readdata. В частности, смотрите Пример 1 из соответствующей страницы справки.
Ошибка повышена, если какие-либо из данных не могут быть преобразованы в действительное число с плавающей запятой.
Позвольте y 1, …, y n быть входными данными x 1, …, x n, расположенный в порядке возрастания. stats::ksGOFT возвращает список
![]()
содержа следующую информацию:
K1 является статистической величиной Кольмогорова-Смирнова![]() .
.
p1 является наблюдаемым уровнем значения![]() статистического
статистического K1.
K2 является статистической величиной Кольмогорова-Смирнова![]() .
.
p2 является наблюдаемым уровнем значения![]() статистического
статистического K2.
Для статистической величины Кольмогорова-Смирнова K, соответствующий K1 или K2, соответственно, наблюдаемым уровням значения p1, p2 вычисляется асимптотическим приближением точной вероятности
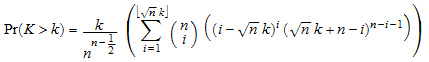 .
.
Для большого n эти вероятности аппроксимированы
![]() .
.
Таким образом наблюдаемые уровни значения, возвращенные stats::ksGOFT, аппроксимируют точные вероятности для большого n. Примерно разговор, для n = 10, 3 ведущих цифры p1, p2 соответствует точным вероятностям. Для n = 100, 4 ведущих цифры p1, p2 соответствует точным вероятностям. Для n = 1000, 6 ведущих цифр p1, p2 соответствует точным вероятностям.
Наблюдаемый уровень значения PValue1 = p1, возвращенный stats::ksGOFT, должен быть интерпретирован следующим образом:
По нулевой гипотезе вероятность p1 = Pr (K> K1) не должен быть маленьким. А именно, p1 = Pr (K> K1) ≥ α должен содержать для данного уровня значения![]() . Если это условие нарушено, гипотеза может быть отклонена на уровне α.
. Если это условие нарушено, гипотеза может быть отклонена на уровне α.
Таким образом, если наблюдаемый уровень значения p1 = Pr (K> K1) удовлетворяет p1 <α, демонстрационное продвижение к значению, K1 статистического K представляет маловероятное событие, и нулевые гипотезы могут быть отклонены на уровне α.
Соответствующая интерпретация содержит для PValue2 = p2: если p2 = Pr(K > K2) удовлетворяет p2 <α, нулевые гипотезы могут быть отклонены на уровне α.
Обратите внимание на то, что оба наблюдаемых уровня значения p1, p2 должен быть достаточно большим, чтобы заставить данные пройти тест. Нулевая гипотеза может быть отклонена на уровне α, если какое-либо из этих двух значений меньше, чем α.
Если p1 и p2 оба близко к 1, это должно вызвать подозрение о случайности данных: они указывают на подгонку, которая слишком хороша.
Дистрибутивы, которые не обеспечиваются stats - пакет, могут быть реализованы легко пользователем. Определяемая пользователем процедура f может реализовать любую кумулятивную функцию распределения; stats::ksGOFT вызывает f (x) с действительными аргументами с плавающей точкой от выборки данных. Функциональный f должен возвратить числовое действительное значение между 0 и 1. Cf. Пример 3.
Функция чувствительна к переменной окружения DIGITS, который определяет числовую рабочую точность.
Мы создаем выборку 1 000 нормально распределенных случайных чисел:
r := stats::normalRandom(0, 1, Seed = 123): data := [r() $ i = 1 .. 1000]:
Мы тестируем, нормально распределены ли эти данные действительно со средним значением 0 und отклонений 1. Мы передаем соответствующую кумулятивную функцию распределения stats::normalCDF(0, 1) stats::ksGOFT:
stats::ksGOFT(data, CDF = stats::normalCDF(0, 1))
![]()
Результат показывает, что данные могут быть приняты как выборка нормально распределенных чисел: оба наблюдаемых уровня значения![]() и
и![]() не являются небольшими.
не являются небольшими.
Затем, мы вводим некоторые дальнейшие данные в выборку:
data := data . [frandom() $ i = 1..100]: stats::ksGOFT(data, CDF = stats::normalCDF(0, 1))
![]()
Теперь, данные не должны быть приняты как выборка нормальных отклонений со средним значением 0 и отклонением 1, потому что второй наблюдаемый уровень значения PValue2 является очень небольшим.
delete r, data:
Мы создаем выборку, состоящую из одного столбца строки и двух столбцов нестроки:
s := stats::sample( [["1996", 1242, PI - 1/2], ["1997", 1353, PI + 0.3], ["1998", 1142, PI + 0.5], ["1999", 1201, PI - 1], ["2001", 1201, PI]])
"1996" 1242 PI - 1/2 "1997" 1353 PI + 0.3 "1998" 1142 PI + 0.5 "1999" 1201 PI - 1 "2001" 1201 PI
Мы рассматриваем данные в третьем столбце. Среднее значение и отклонение этих данных вычисляются:
[m, v] := [stats::mean(s, 3), stats::variance(s, 3)]
![]()
Мы проверяем, нормально распределены ли данные 3-го столбца со средним значением и отклонением, вычисленным выше:
stats::ksGOFT(s, 3, CDF = stats::normalCDF(m, v))
![]()
Оба наблюдаемых уровня значения![]() и
и![]() возвратились тестом, не являются маленькими. Нет никакой причины отклонить нулевую гипотезу, что данные нормально распределены.
возвратились тестом, не являются маленькими. Нет никакой причины отклонить нулевую гипотезу, что данные нормально распределены.
delete s, m, v:
Мы демонстрируем, как могут использоваться пользовательские функции распределения. Следующая функция представляет кумулятивную функцию распределения Pr (X ≤ x) = x 2 из переменной X, поддержанной на интервале [0, 1]. Это будет вызвано аргументами x с плавающей точкой и должно возвратить численные значения между 0 и 1:
f := proc(x)
begin
if x <= 0 then return(0)
elif x < 1 then return(x^2)
else return(1)
end_if
end_proc:Мы тестируем гипотезу, что следующими данными является f - распределенный:
data := [sqrt(frandom()) $ k = 1..10^2]: stats::ksGOFT(data, CDF = f)
![]()
На данном уровне значения 0,1, скажем, не должна быть отклонена гипотеза: оба наблюдаемых уровня значения p1 =![]() и
и p2 =![]() превышают 0.1.
превышают 0.1.
delete f, data:
|
Статистические данные: действительные численные значения |
|
Процедура, представляющая кумулятивную функцию распределения. Как правило, одна из функций распределения |
|
Выборка доменного типа |
|
Целое число, представляющее индекс столбца демонстрационного |
Перечислите с четырьмя уравнениями [PValue1 = p1, StatValue1 = K1, PValue2 = p2, StatValue2 = K2], со значениями с плавающей точкой p1, K1, p2, K2. Смотрите раздел “Details” ниже для интерпретации этих значений.
Д. Э. Нут, Искусство Программирования, Vol 2: получисловые Алгоритмы, стр 48. Аддисон-Уэсли (1998).
