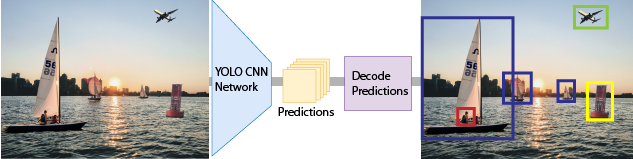
Вы только смотрите однажды (YOLO) v2 объектный детектор использует одноступенчатую сеть обнаружения объектов. YOLO v2 быстрее, чем другие детекторы объекта глубокого обучения 2D этапа, таков как области со сверточными нейронными сетями (Быстрее R-CNNs).
Модель YOLO v2 запускает CNN глубокого обучения на входном изображении, чтобы произвести сетевые прогнозы. Объектный детектор декодирует прогнозы и генерирует ограничительные рамки.
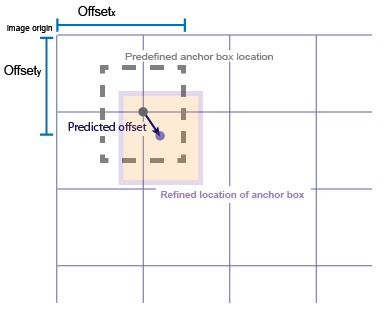
YOLO v2 использует поля привязки, чтобы обнаружить классы объектов в изображении. Для получения дополнительной информации смотрите Поля Привязки для Обнаружения объектов. YOLO v2 предсказывает эти три атрибута для каждого поля привязки:
Пересечение по объединению (IoU) — Предсказывает счет объектности каждого поля привязки.
Смещения поля привязки — Совершенствовали положение поля привязки
Вероятность класса — Предсказывает метку класса, присвоенную каждому полю привязки.
Данные показывают предопределенное поле привязки (пунктирная линия) и усовершенствованное местоположение после того, как смещения будут применены.
С изучением передачи можно использовать предварительно обученный CNN в качестве экстрактора функции в сети обнаружения YOLO v2. Используйте функцию yolov2Layers, чтобы создать сеть обнаружения YOLO v2 из любого предварительно обученного CNN, например, MobileNet v2. Для списка предварительно обученного CNNs смотрите Предварительно обученные Глубокие нейронные сети (Deep Learning Toolbox)
Можно также разработать пользовательское основанное на модели на предварительно обученном CNN классификации изображений. Для получения дополнительной информации см. Проект Сеть обнаружения YOLO v2.
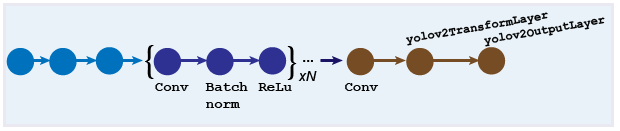
Можно разработать пользовательский слой модели YOLO v2 слоем. Модель запускается с сети экстрактора функции, которая может быть инициализирована от предварительно обученного CNN или обучена с нуля. Подсеть обнаружения содержит серию Conv, Batch norm и слоев ReLu, сопровождаемых преобразованием и выходными слоями, yolov2TransformLayer и объектами yolov2OutputLayer, соответственно. yolov2TransformLayer преобразовывает необработанный CNN вывод в форму, требуемую произвести обнаружения объектов. yolov2OutputLayer задает параметры поля привязки и реализует функцию потерь, используемую, чтобы обучить детектор.
Можно также использовать приложение Deep Network Designer, чтобы вручную создать сеть. Разработчик включает функции Computer Vision Toolbox™ YOLO v2.
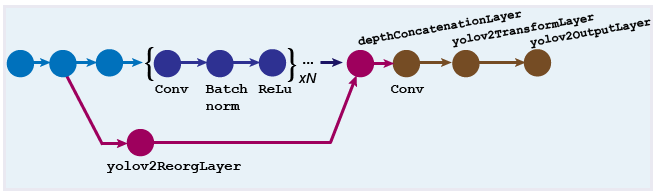
Слой перестройки (созданное использование объекта yolov2ReorgLayer) и слой конкатенации глубины (созданное использование объекта depthConcatenationLayer) используются, чтобы сочетать низкоуровневые и высокоуровневые функции. Эти слои улучшают обнаружение путем добавления низкоуровневых данных изображения и улучшения точности обнаружения для меньших объектов. Как правило, слой перестройки присоединен к слою в сети выделения признаков, выходная карта функции которой больше, чем слой выделения признаков вывод.
Настройте свойство 'Stride' объекта yolov2ReorgLayer, таким образом, что его выходной размер совпадает с входным размером объекта depthConcatenationLayer.
Чтобы упростить разработку сети, используйте интерактивное приложение Deep Network Designer и функцию analyzeNetwork.
Для получения дополнительной информации о том, как создать этот вид сети, смотрите, Создают Сеть обнаружения объектов YOLO v2.
Чтобы изучить, как обучить объектный детектор при помощи метода глубокого обучения YOLO с CNN, смотрите, что Обнаружение объектов Использует пример YOLO v2 Глубокого обучения.
Чтобы изучить, как сгенерировать код CUDA® с помощью детектора объекта YOLO v2 (созданное использование объекта yolov2ObjectDetector), смотрите Генерацию кода для Обнаружения объектов Используя YOLO v2.
Можно использовать Image Labeler, Video Labeler или Ground Truth Labeler (доступный в Automated Driving Toolbox™) приложения, чтобы в интерактивном режиме маркировать пиксели и экспортировать данные о метке для обучения. Приложения могут также использоваться, чтобы маркировать прямоугольные видимые области (КОРОЛИ) для обнаружения объектов, метки сцены для классификации изображений и пиксели для семантической сегментации.
[1] Redmon, J. и А. Фархади. "YOLO9000: лучше, быстрее, более сильный". Конференция по IEEE по компьютерному зрению и распознаванию образов (CVPR), 6517–6525. Гонолулу, HI: CVPR 2017.
[2] Redmon, J., С. Диввэла, Р. Джиршик и А. Фархади. "Вы только смотрите однажды: Объединенное, обнаружение объектов в реальном времени". Продолжения Конференции по IEEE по Компьютерному зрению и Распознаванию образов (CVPR), 779–788. Лас-Вегас, NV: CVPR, 2016.
depthConcatenationLayer | yolov2ObjectDetector | yolov2OutputLayer | yolov2ReorgLayer | yolov2TransformLayer