

Predictive Maintenance Toolbox™ включает некоторые специализированные модели, спроектированные для вычисления RUL от различных типов измеренных системных данных. Эти модели полезны, когда у вас есть исторические данные и информация, такие как:
Истории запуска к отказу машин, похожих на ту, вы хотите диагностировать
Известное пороговое значение некоторого индикатора состояния, который указывает на отказ
Данные, о сколько времени или сколько использования потребовалось для подобных машин, чтобы достигнуть отказа (время жизни)
Модели оценки RUL предоставляют методы для обучения модель с помощью исторических данных и с помощью него для выполнения предсказания остающегося срока полезного использования. Термин lifetime здесь относится к жизни машины, заданной в терминах любого количества, которое вы используете, чтобы измерить системную жизнь. Так же time evolution может означать эволюцию значения с использованием, расстояние переместилось, количество циклов или другое количество, которое описывает время жизни.
Общий рабочий процесс для использования моделей оценки RUL:
Выберите лучший тип модели оценки RUL для данных и системного знания, которое вы имеете. Создайте и сконфигурируйте соответствующий объект модели.
Обучите модель оценки использование исторических данных, которые вы имеете. Для этого используйте fit команда.
Используя тестовые данные того же типа как ваши исторические данные, оцените RUL тестового компонента. Для этого используйте predictRUL команда. Можно также использовать тестовые данные рекурсивно, чтобы обновить некоторые типы модели, такие как модели ухудшения, помочь сохранить предсказания точными. Для этого используйте update команда.
Для основного примера, иллюстрирующего эти шаги, смотрите Обновление Предсказание RUL, когда Данные Прибывают.
Существует три семейства моделей оценки RUL. Выберите, какое семейство и какую модель использовать на основе данных и информации о системе вы имеете в наличии, как показано на следующем рисунке.
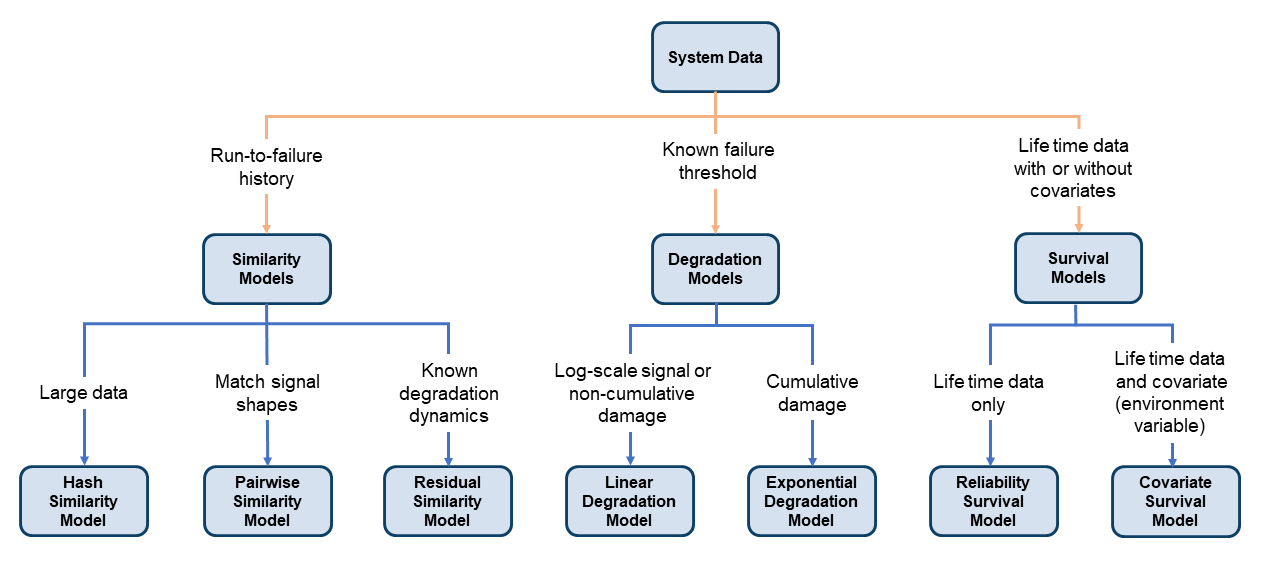
Модели подобия основывают предсказание RUL тестовой машины на известном поведении подобных машин от исторической базы данных. Такие модели сравнивают тренд в тестовых данных или значениях индикатора состояния к той же информации, извлеченной из другого, аналогичных систем.
Модели подобия полезны когда:
У вас есть данные запуска к отказу из аналогичных систем (components). Данные запуска к отказу являются данными, которые запускаются во время здоровой операции и заканчиваются, когда машина находится в состоянии близко к отказу или обслуживанию.
Данные запуска к отказу показывают подобные поведения ухудшения. Таким образом, изменения данных некоторым характеристическим способом как система ухудшаются.
Таким образом можно использовать модели подобия, когда можно получить degradation profiles из ансамбля данных. Профили ухудшения представляют эволюцию одного или нескольких индикаторов состояния для каждой машины в ансамбле (каждый компонент) как переходы машины от здорового состояния до дефектного состояния.
Predictive Maintenance Toolbox включает три типа моделей подобия. Все три типа оценивают RUL путем определения подобия между историей ухудшения набора тестовых данных и историей ухудшения наборов данных в ансамбле. Для моделей подобия, predictRUL оценивает RUL тестового компонента как средняя продолжительность жизни большинства подобных компонентов минус текущее пожизненное значение тестового компонента. Эти три модели отличаются по способам, которыми они задают и определяют количество понятия подобия.
Модель подобия хешированной функции (hashSimilarityModel) — Эта модель преобразовывает исторические данные об ухудшении от каждого члена вашего ансамбля в фиксированный размер, сжатый, информация, такая как среднее значение, общая степень, максимальные или минимальные значения или другие количества.
Когда вы вызываете fit на a hashSimilarityModel объект, программное обеспечение вычисляет их hashed features и хранит их в модели подобия. Когда вы вызываете predictRUL с данными из тестового компонента программное обеспечение вычисляет хешированные функции и сравнивает результат со значениями в таблице исторических хешированных функций.
Модель подобия хешированной функции полезна, когда у вас есть большие суммы данных об ухудшении, потому что это уменьшает устройство хранения данных объема данных, необходимое для предсказания. Однако его точность зависит от точности хеш-функции, которую использует модель. Если вы идентифицировали индикаторы хорошего состояния в своих данных, можно использовать Method свойство hashSimilarityModel объект задать хеш-функцию, чтобы использовать те функции.
Попарная модель подобия (pairwiseSimilarityModel) — Попарная оценка подобия определяет RUL путем нахождения компонентов, исторические пути к ухудшению которых больше всего коррелируются к тому из тестового компонента. Другими словами, это вычисляет расстояние между различными временными рядами, где расстояние задано как корреляция, динамическая трансформация временной шкалы (dtw), или пользовательская метрика, которую вы обеспечиваете. Путем принятия во внимание профиля ухудшения в процессе изменения, попарная оценка подобия может дать лучшие результаты, чем модель подобия хеша.
Остаточная модель подобия (residualSimilarityModel) — Основанная на невязке оценка соответствует предшествующим данным к модели, такой как модель ARMA или модель, которая линейна или экспоненциальна во время использования. Это затем вычисляет остаточные значения между данными, предсказанными из моделей ансамбля и данными из тестового компонента. Можно просмотреть остаточную модель подобия как изменение на попарной модели подобия, где величины остаточных значений являются метрикой расстояния. Остаточный подход подобия полезен, когда ваше знание системы включает форму для модели ухудшения.
Для примера, который использует модель подобия для оценки RUL, смотрите Основанную на подобии Остающуюся Оценку Срока полезного использования.
Модели ухудшения экстраполируют прошлое поведение, чтобы предсказать будущее условие. Этот тип вычисления RUL подбирает линейную или экспоненциальную модель к профилю ухудшения индикатора состояния, учитывая профили ухудшения в вашем ансамбле. Это затем использует профиль ухудшения тестового компонента, чтобы статистически вычислить остающееся время, пока индикатор не достигает некоторого предписанного порога. Эти модели являются самыми полезными, когда существует известное значение вашего индикатора состояния, который указывает на отказ. Два доступных типа модели ухудшения:
Линейная модель ухудшения (linearDegradationModel) — Описывает поведение ухудшения как линейный стохастический процесс со сроком смещения. Линейные модели ухудшения полезны, когда ваша система не испытывает совокупное ухудшение.
Экспоненциальная модель ухудшения (exponentialDegradationModel — Описывает поведение ухудшения как экспоненциальный стохастический процесс со сроком смещения. Экспоненциальные модели ухудшения полезны, когда тестовый компонент испытывает совокупное ухудшение.
После того, как вы создаете объект модели ухудшения, инициализируете модель с помощью исторических данных относительно здоровья ансамбля подобных компонентов, таких как несколько машин, произведенных к тем же техническим требованиям. Для этого используйте fit. Можно затем предсказать остающийся срок полезного использования подобного использования компонентов predictRUL.
Модели ухудшения только работают с одним индикатором состояния. Однако можно использовать анализ главных компонентов или другие методы сплава, чтобы сгенерировать сплавленный индикатор состояния, который включает информацию больше чем от одного индикатора состояния. Используете ли вы один индикатор или сплавленный индикатор, ищете индикатор, который показывает ясное увеличение или уменьшение тренда, так, чтобы моделирование и экстраполяция были надежны.
Для примера, который проявляет этот подход и оценивает RUL использование модели ухудшения, смотрите Прогнозирование высокоскоростного подшипника ветрогенератора.
Анализ выживания является статистическим методом, используемым, чтобы смоделировать время к данным о событиях. Полезно, когда вы не имеете полных историй запуска к отказу, но вместо этого имеете:
Только данные о продолжительности жизни подобных компонентов. Например, вы можете знать, сколько миль каждый механизм в вашем ансамбле запустился прежде, чем нуждаться в обслуживании, или сколько часов работы каждая машина в вашем ансамбле запустилась перед отказом. В этом случае вы используете reliabilitySurvivalModel. Учитывая историческую информацию о временах отказа флота подобных компонентов, эта модель оценивает вероятностное распределение времен отказа. Распределение используется, чтобы оценить RUL тестового компонента.
Обе продолжительности жизни и некоторые другие переменные данные (covariates), который коррелирует с RUL. Коварианты, также названные environmental variables или explanatory variables, включают информацию, такую как провайдер компонента, режимы, в которых компонент использовался, или производящий пакет. В этом случае использовать covariateSurvivalModel. Эта модель является пропорциональной моделью выживания опасности, которая использует продолжительности жизни и коварианты, чтобы вычислить вероятность выживания тестового компонента.
covariateSurvivalModel | exponentialDegradationModel | fit | hashSimilarityModel | linearDegradationModel | pairwiseSimilarityModel | predictRUL | reliabilitySurvivalModel | residualSimilarityModel