Информация о производительности классификатора
Чтобы просмотреть информацию о производительности классификатора, создайте classperformance с помощью classperf функция. Использование точечной нотации для доступа к свойствам объекта, таким как CorrectRate, ErrorRate, Sensitivity, и Specificity.
Label - Наименование объекта-классификатора'' (по умолчанию) | символьный векторИмя объекта-классификатора, указанное как символьный вектор. Используйте точечную нотацию для установки этого свойства.
Пример:
'cp_kfold'
Типы данных: char
Description - Описание объекта'' (по умолчанию) | символьный векторОписание объекта, указанное как символьный вектор. Используйте точечную нотацию для установки этого свойства.
Пример:
'performance_data_kfold'
Типы данных: char
ClassLabels - Уникальный набор истинных метокЭто свойство доступно только для чтения.
Уникальный набор истинных меток из groundTruth, указанный как вектор положительных целых чисел или клеточный массив символьных векторов. Это свойство эквивалентно выводу при запуске unique(.groundTruth)
Пример:
{'ovarian','liver','normal'}
Типы данных: double | cell
GroundTruth - Подлинные метки для всех наблюденийЭто свойство доступно только для чтения.
Истинные метки для всех наблюдений в наборе данных, указанные как вектор положительных целых чисел или клеточный массив символьных векторов.
Пример:
{'ovarian','liver','normal','ovarian','ovarian','liver'}
Типы данных: double | cell
NumberOfObservations - Количество наблюденийЭто свойство доступно только для чтения.
Количество наблюдений в наборе данных, указанное как положительное целое число.
Пример:
200
Типы данных: double
ControlClasses - Индексы для управления классами из истинных метокИндексы к классам управления из истинных меток (ClassLabels), указанный как вектор положительных целых чисел. Это свойство указывает контрольные (или отрицательные) классы в диагностическом тесте. По умолчанию ControlClasses содержит все классы, отличные от первого класса, возвращенного grp2idx(.groundTruth)
Это свойство можно задать с помощью точечной нотации или 'Negative' аргумент пары имя-значение с classperf функция.
Пример:
[3]
Типы данных: double
TargetClasses - Индексы для целевых классов из истинных меток Индексы к целевым классам из истинных меток (ClassLabels), указанный как вектор положительных целых чисел. Это свойство указывает целевые (или положительные) классы в диагностическом тесте. По умолчанию TargetClasses содержит первый класс, возвращенный grp2idx(.groundTruth)
Это свойство можно задать с помощью точечной нотации или 'Positive' аргумент пары имя-значение с classperf функция.
Пример:
[1 2]
Типы данных: double
SampleDistribution - Количество оценок по каждой выборкеЭто свойство доступно только для чтения.
Количество оценок для каждого образца во время проверки, указанное как числовой вектор. Например, если используется повторное замещение, SampleDistribution является вектором единиц и ValidationCounter = 1. Если у вас 10-кратная перекрестная проверка, SampleDistribution также является вектором единиц, но ValidationCounter = 10.
SampleDistribution полезен при выполнении разделов Monte Carlo тестовых наборов, и он может помочь определить, был ли каждый образец протестирован одинаковое количество раз.
Пример:
[0 0 2 0]
Типы данных: double
ErrorDistribution - Частота неправильной классификации каждого образцаЭто свойство доступно только для чтения.
Частота неправильной классификации каждого образца, указанная как числовой вектор.
Пример:
[0 0 1 0]
Типы данных: double
SampleDistributionByClass - Частота истинных классов во время проверкиЭто свойство доступно только для чтения.
Частота истинных классов во время проверки, указанная как числовой вектор.
Пример:
[10 10 0]
Типы данных: double
ErrorDistributionByClass - Частота ошибок для каждого классаЭто свойство доступно только для чтения.
Частота ошибок для каждого класса во время проверки, указанная как числовой вектор.
Пример:
[0 0 0]
Типы данных: double
ValidationCounter - Количество проверокЭто свойство доступно только для чтения.
Число проверок, указанное как положительное целое число.
Пример:
10
Типы данных: double
CountingMatrix - Матрица путаницы классификацииЭто свойство доступно только для чтения.
Матрица путаницы классификации, заданная как числовой массив. Порядок строк и столбцов в матрице такой же, как в grp2idx(groundTruth). Столбцы представляют истинные классы, а строки представляют предсказание классификатора. Последняя строка в CountingMatrix зарезервирован для подсчета неубедительных результатов.
Пример:
[10 0 0;0 10 0; 0 0 0; 0 0 0]
Типы данных: double
CorrectRate - Правильная скорость классификатораЭто свойство доступно только для чтения.
Правильная скорость классификатора, заданная как положительный скаляр. CorrectRate определяется как количество правильно классифицированных проб, деленное на количество классифицированных проб. Неубедительные результаты не учитываются.
Пример: 1
Типы данных: double
ErrorRate - Частота ошибок классификатораЭто свойство доступно только для чтения.
Частота ошибок классификатора, заданная как положительный скаляр. ErrorRate определяется как количество неправильно классифицированных проб, деленное на количество классифицированных проб. Неубедительные результаты не учитываются.
Пример: 0
Типы данных: double
LastCorrectRate - Правильная скорость классификатора во время последнего прогонаЭто свойство доступно только для чтения.
Правильная скорость классификатора во время последнего прогона проверки, заданная как положительный скаляр. В отличие от CorrectRate, LastCorrectRate применяется только к оцененным выборкам из последнего прогона проверки объекта производительности классификатора.
Пример:
1
Типы данных: double
LastErrorRate - Частота ошибок классификатора во время последней проверкиЭто свойство доступно только для чтения.
Частота ошибок классификатора во время последнего прогона проверки, заданная как положительный скаляр. В отличие от ErrorRate, LastErrorRate применяется только к оцененным выборкам из последнего прогона проверки объекта производительности классификатора.
Пример:
0
Типы данных: double
InconclusiveRate - Неубедительная скорость классификатораЭто свойство доступно только для чтения.
Неубедительная скорость классификатора, заданная как положительный скаляр. InconclusiveRate определяется как количество неклассифицированных (неубедительных) образцов, деленное на общее количество образцов.
Пример:
0
Типы данных: double
ClassifiedRate - Классифицированная норма классификатораЭто свойство доступно только для чтения.
Классифицированная скорость классификатора, заданная как положительный скаляр. ClassifiedRate определяется как количество классифицированных проб, деленное на общее количество проб.
Пример:
1
Типы данных: double
Sensitivity - Чувствительность классификатораЭто свойство доступно только для чтения.
Чувствительность классификатора, заданная как положительный скаляр. Sensitivity определяется как количество правильно классифицированных положительных выборок, деленное на количество истинных положительных выборок.
Неубедительные результаты, являющиеся истинно положительными, считаются ошибками при вычислении Sensitivity. Другими словами, неубедительные результаты могут снизить диагностическое значение теста.
Пример:
1
Типы данных: double
Specificity - Специфика классификатораЭто свойство доступно только для чтения.
Специфичность классификатора, определяемая как положительный скаляр. Specificity определяется как количество правильно классифицированных отрицательных выборок, деленное на количество истинных отрицательных выборок.
Неубедительные результаты, являющиеся истинными негативами, считаются ошибками при вычислении Specificity. Другими словами, неубедительные результаты могут снизить диагностическое значение теста.
Пример:
0.8
Типы данных: double
PositivePredictiveValue - Положительная прогностическая ценность классификатораЭто свойство доступно только для чтения.
Положительное прогностическое значение классификатора, определяемое как положительный скаляр. PositivePredictiveValue определяется как количество правильно классифицированных положительных выборок, деленное на количество положительных классифицированных выборок.
Неубедительные результаты классифицируются как отрицательные при вычислениях PositivePredictiveValue.
Пример:
1
Типы данных: double
NegativePredictiveValue - Отрицательная прогностическая ценность классификатораЭто свойство доступно только для чтения.
Отрицательное прогностическое значение классификатора, определяемое как положительный скаляр. NegativePredictiveValue определяется как количество правильно классифицированных отрицательных выборок, деленное на количество отрицательных классифицированных выборок.
Неубедительные результаты классифицируются как положительные при вычислениях NegativePredictiveValue.
Пример:
1
Типы данных: double
PositiveLikelihood - Положительная вероятность использования классификатораЭто свойство доступно только для чтения.
Положительная вероятность классификатора, заданная как положительный скаляр. PositiveLikelihood определяется как Sensitivity / (1 - Specificity)
Пример: 5
Типы данных: double
NegativeLikelihood - Отрицательная вероятность использования классификатораЭто свойство доступно только для чтения.
Отрицательная вероятность классификатора, заданная как положительный скаляр. NegativeLikelihood определяется как (1 - .Sensitivity)/Specificity
Пример: 0
Типы данных: double
Prevalence - Распространенность классификатораЭто свойство доступно только для чтения.
Распространенность классификатора, указанная как положительный скаляр. Prevalence определяется как число истинных положительных выборок, деленное на общее число выборок.
Пример:
1
Типы данных: double
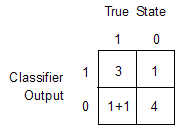
DiagnosticTable - Диагностическая таблицаЭто свойство доступно только для чтения.
Диагностическая таблица, заданная в виде числового массива «два на два». Первая строка указывает число выборок, классифицированных как положительные, с числом истинных положительных результатов в первом столбце и числом ложных положительных результатов во втором столбце. Вторая строка указывает количество образцов, классифицированных как отрицательные, с числом ложных негативов в первом столбце и числом истинных негативов во втором столбце.
В диагональных элементах появляются правильные классификации, а в внеканальных - ошибки. Неубедительные результаты считаются ошибками и учитываются в внедиагональных элементах. Пример см. в разделе Пример диагностической таблицы.
Пример:
[20 0;0 0]
Типы данных: double
Предположим, что исследование рака 10 пациентов дает эти результаты.
| Пациент | Выход классификатора | Имеет рак |
|---|---|---|
| 1 | Положительный | Да |
| 2 | Положительный | Да |
| 3 | Положительный | Да |
| 4 | Положительный | Нет |
| 5 | Отрицательный | Да |
| 6 | Отрицательный | Нет |
| 7 | Отрицательный | Нет |
| 8 | Отрицательный | Нет |
| 9 | Отрицательный | Нет |
| 10 | Неокончательный | Да |
Используя эти результаты, функция вычисляет DiagnosticTable следующим образом:
classify | classperf | crossvalind | grp2idx
1. Если смысл перевода понятен, то лучше оставьте как есть и не придирайтесь к словам, синонимам и тому подобному. О вкусах не спорим.
2. Не дополняйте перевод комментариями “от себя”. В исправлении не должно появляться дополнительных смыслов и комментариев, отсутствующих в оригинале. Такие правки не получится интегрировать в алгоритме автоматического перевода.
3. Сохраняйте структуру оригинального текста - например, не разбивайте одно предложение на два.
4. Не имеет смысла однотипное исправление перевода какого-то термина во всех предложениях. Исправляйте только в одном месте. Когда Вашу правку одобрят, это исправление будет алгоритмически распространено и на другие части документации.
5. По иным вопросам, например если надо исправить заблокированное для перевода слово, обратитесь к редакторам через форму технической поддержки.
