Обучение усилению - это целевой вычислительный подход, при котором компьютер учится выполнять задачу, взаимодействуя с неизвестной динамической средой. Этот подход обучения позволяет компьютеру принимать ряд решений, чтобы максимизировать совокупное вознаграждение за задачу без вмешательства человека и без явного программирования для выполнения задачи. На следующей диаграмме показано общее представление сценария обучения армированию.

Целью обучения усилению является обучение политике агента выполнению задачи в неизвестной среде. Агент получает наблюдения и вознаграждение от окружающей среды и отправляет действия в окружающую среду. Награда - это показатель того, насколько успешным является действие в отношении выполнения задачи.
Для создания и обучения агентов обучения усилению можно использовать программное обеспечение Toolbox™ обучения усилению. Обычно агентские политики реализуются с помощью глубоких нейронных сетей, которые можно создать с помощью программного обеспечения Deep Learning Toolbox™.
Обучение усилению полезно для многих приложений управления и планирования. Следующие примеры показывают, как обучить агентов по обучению усилению для робототехники и автоматизированных задач вождения.
Общий поток операций для обучения агента с использованием обучения усилению включает в себя следующие шаги.
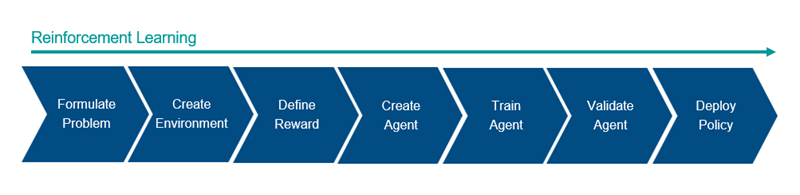
Сформулировать проблему - определите задачу для агента, чтобы узнать, как агент взаимодействует с окружающей средой и любые первичные и вторичные цели, которые агент должен достичь.
Создать среду - определение среды, в которой работает агент, включая интерфейс между агентом и средой и динамическую модель среды.
Определить вознаграждение (Define reward) - укажите сигнал вознаграждения, который агент использует для измерения его производительности в соответствии с целями задачи и способом вычисления этого сигнала из среды.
Создать агента - создание агента, которое включает определение представления политики и настройку алгоритма обучения агента.
Train agent - подготовка представления политики агента с использованием определенной среды, вознаграждения и алгоритма обучения агента.
Проверка агента - оценка производительности обученного агента путем совместного моделирования агента и среды.
Развернуть политику - развернуть подготовленное представление политики, используя, например, созданный код графического процессора.
Обучение агента с помощью обучения усилению является итеративным процессом. Для принятия решений и получения результатов на более поздних этапах может потребоваться вернуться на более ранний этап процесса обучения. Например, если процесс обучения не сходится к оптимальной политике в течение разумного периода времени, перед переподготовкой агента может потребоваться обновить любое из следующего:
Настройки обучения
Конфигурация алгоритма обучения
Политическое представительство
Определение сигнала вознаграждения
Сигналы действий и наблюдения
Динамика окружающей среды
В сценарии обучения усилению, в котором агент обучается выполнению задачи, среда моделирует динамику взаимодействия агента. Окружающая среда:
Получает действия от агента.
Выводит замечания в ответ на действия.
Генерирует вознаграждение, измеряющее, насколько хорошо действие способствует выполнению задачи.
Создание модели среды включает в себя определение следующего:
Сигналы действий и наблюдения, которые агент использует для взаимодействия с окружающей средой.
Сигнал вознаграждения, который агент использует для измерения своего успеха. Дополнительные сведения см. в разделе Определение сигналов вознаграждения (инструментарий обучения усилению).
Динамическое поведение среды.
Среду можно создать в MATLAB ® или Simulink ®. Дополнительные сведения см. в разделах Создание учебных сред для усиления MATLAB (панель обучения для усиления) и Создание учебных сред для усиления Simulink (панель обучения для усиления).
Усиливающий обучающий агент содержит два компонента: политику и алгоритм обучения.
Политика представляет собой сопоставление, которое выбирает действия на основе наблюдений из среды. Обычно политика является аппроксиматором функции с настраиваемыми параметрами, такими как глубокая нейронная сеть.
Алгоритм обучения постоянно обновляет параметры политики на основе действий, наблюдений и вознаграждения. Целью алгоритма обучения является поиск оптимальной политики, которая максимизирует совокупное вознаграждение, полученное во время выполнения задачи.
Агенты отличаются алгоритмами обучения и представлениями политики. Агенты могут работать в пространствах дискретных действий, пространствах непрерывных действий или в обоих пространствах. В пространстве дискретных действий агент выбирает действия из конечного набора возможных действий. В пространстве непрерывного действия агент выбирает действие из непрерывного диапазона возможных значений действия. Программа «Набор обучающих средств для усиления» поддерживает следующие типы агентов.
| Агент | Пространство действий |
|---|---|
| Q-Learning Agents (инструментарий обучения для усиления) | Дискретный |
| Агенты Deep Q-Network (инструментарий обучения усилению) | Дискретный |
| Агенты SARSA (инструментарий обучения усилению) | Дискретный |
| Агенты градиента политики (инструментарий обучения для усиления) | Дискретный или непрерывный |
| Актерско-критические агенты (инструментарий для обучения усилению) | Дискретный или непрерывный |
| Агенты оптимизации проксимальной политики (инструментарий для обучения усилению) | Дискретный или непрерывный |
| Агенты градиента глубокой детерминированной политики (инструментарий обучения усилению) | Непрерывный |
| Агенты градиента глубокой детерминированной политики с двойной задержкой (инструментарий для обучения усилению) | Непрерывный |
| Soft Actor-Critic Agents (инструментарий для обучения усилению) | Непрерывный |
Дополнительные сведения см. в разделе Агенты обучения усилению (панель инструментов обучения усилению).
В зависимости от типа используемого агента, его политика и алгоритм обучения требуют одного или нескольких представлений политик и функций значений, которые можно реализовать с помощью глубоких нейронных сетей.
Инструментарий обучения для усиления поддерживает следующие типы функций значений и представлений политик.
V (S 'startV) - критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение (стоимостную функцию) на основе данного наблюдения S .
Q (S, A 'startQ) - критики, которые оценивают функцию значения для данного дискретного действия А и данного наблюдения S.
Qi (S, Ai 'startQ) - Многоотходные критики, которые оценивают функцию значения для всех возможных дискретных действий Ai и данного наблюдения S.
λ (S 'startλ) - акторы, которые выбирают действие на основе данного наблюдения S. Актеры могут выбирать действия, используя детерминированные или стохастические методы.
Во время тренировок агент обновляет параметры этих представлений (startV, startQ и (В)).
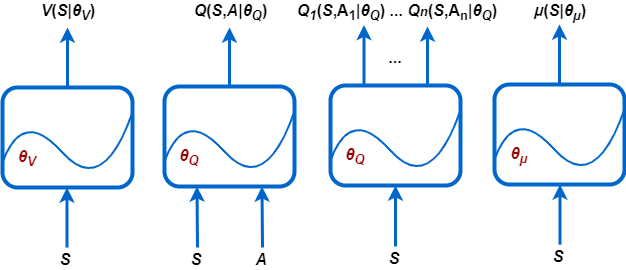
Можно создать большинство агентов панели инструментов обучения для усиления с представлениями политик и функций значений по умолчанию. Агенты определяют входной и выходной уровни этих глубоких нейронных сетей на основе характеристик действия и наблюдения из окружающей среды.
Кроме того, можно создать представления актера и критика для агента, используя функциональные возможности Deep Learning Toolbox, такие как приложение Deep Network Designer. В этом случае убедитесь, что входные и выходные измерения представления актера и критика соответствуют соответствующим спецификациям действий и наблюдений среды. Пример создания критического представления с помощью Deep Network Designer см. в разделах Создание агента с помощью Deep Network Designer и Обучение с помощью наблюдений за изображениями.
Глубокие нейронные сети состоят из ряда взаимосвязанных слоев. Полный список доступных слоев см. в разделе Список слоев глубокого обучения.
Все агенты, за исключением агентов Q-learning и SARSA, поддерживают рецидивирующие нейронные сети (RNN). Эти сети имеют вход sequenceInputLayer и, по меньшей мере, один слой, который имеет скрытую информацию о состоянии, такую как lstmLayer. Эти сети могут быть особенно полезны, когда среда имеет состояния, которые не находятся в векторе наблюдения.
Дополнительные сведения о создании агентов и связанных с ними представлениях функций и политик см. на соответствующих страницах агента в предыдущей таблице.
В программном обеспечении Accammentation Learning Toolbox предусмотрены дополнительные слои, которые можно использовать при создании глубоких нейронных сетевых представлений.
| Слой | Описание |
|---|---|
scalingLayer(инструментарий для обучения по усилению) | Применяет линейный масштаб и смещение к входному массиву. Этот слой полезен для масштабирования и сдвига выходных сигналов нелинейных слоев, таких как tanhLayer и sigmoidLayer. |
quadraticLayer(инструментарий для обучения по усилению) | Создает вектор квадратичных мономеров, построенный из элементов входного массива. Этот уровень полезен, когда необходим выход, представляющий собой некую квадратичную функцию его входов, например, для контроллера LQR. |
softplusLayer(инструментарий для обучения по усилению) | Реализует активацию softplus Y = log (1 + eX), которая гарантирует, что выходной сигнал всегда будет положительным. Это сглаженный вариант выпрямленного линейного блока (ReLU). |
Дополнительные сведения о создании представлений политик и функций-значений см. в разделе Создание представлений политик и функций-значений (панель обучения по усилению).
С помощью функции импорта сети Deep Learning Toolbox можно также импортировать предварительно подготовленные нейронные сети или архитектуры уровня глубокой нейронной сети. Дополнительные сведения см. в разделе Импорт представлений политик и ценностных функций (инструментарий обучения усилению).
После создания среды и усиления агента обучения можно обучить агента в среде с помощью train(Панель инструментов обучения для усиления). Для настройки обучения используйте rlTrainingOptions(Панель обучающих инструментов «Усиление»). Дополнительные сведения см. в разделе Обучение агентов обучения усилению (панель инструментов обучения усилению).
Если у вас есть программное обеспечение Parallel Computing Toolbox™, вы можете ускорить обучение и моделирование с помощью многоядерных процессоров или графических процессоров. Дополнительные сведения см. в разделе Обучение агентов с помощью параллельных вычислений и графических процессоров (инструментарий для обучения усилению).
После обучения агента обучения усилению можно создать код для развертывания оптимальной политики. Можно создать:
Код CUDA ® с использованием графического процессора Coder™
Код C/C + + с использованием MATLAB Coder™
Чтобы создать функцию оценки политики, которая выбирает действие на основе данного наблюдения, используйте generatePolicyFunction(Панель инструментов обучения по усилению). Эта команда создает сценарий MATLAB, содержащий функцию оценки политики, и MAT-файл, содержащий оптимальные данные политики.
Для развертывания этой функции политики можно создать код с помощью кодера графического процессора или кодера MATLAB.
Дополнительные сведения см. в разделе Развертывание обученных политик обучения усилению (панель инструментов обучения усилению).
