Моделирование коэффициентов регрессии и дисперсии возмущений байесовской модели линейной регрессии
[ возвращает случайный вектор коэффициентов регрессии (BetaSim,sigma2Sim] = simulate(Mdl)BetaSim) и случайную дисперсию возмущений (sigma2Sim) из байесовской модели линейной регрессии
Mdl из β и start2.
[ извлекает из краевых задних распределений, полученных или обновленных путем включения данных предиктора BetaSim,sigma2Sim] = simulate(Mdl,X,y)X и соответствующие данные ответа y.
Если Mdl является совместной предшествующей моделью, то simulate создает краевые апостериорные распределения путем обновления предшествующей модели информацией о параметрах, которые она получает из данных.
Если Mdl является краевой задней моделью, то simulate обновляет апостериоры информацией о параметрах, которые они получают из дополнительных данных. Полная вероятность данных состоит из дополнительных данных. X и yи данные, которые были созданы Mdl.
NaNs в данных указывают отсутствующие значения, которые simulate удаляет, используя удаление по списку.
[ использует любую из комбинаций входных аргументов в предыдущих синтаксисах и дополнительных параметрах, заданных одним или несколькими аргументами пары имя-значение. Например, для моделирования из условного апостериорного распределения одного параметра можно задать значение β или start2, учитывая заданное значение другого параметра.BetaSim,sigma2Sim] = simulate(___,Name,Value)
[ также возвращает данные из распределения скрытого режима, если BetaSim,sigma2Sim,RegimeSim] = simulate(___)Mdl - байесовская модель линейной регрессии для стохастического выбора переменных поиска (SSVS), то есть, если Mdl является mixconjugateblm или mixsemiconjugateblm объект модели.
Рассмотрим модель множественной линейной регрессии, которая предсказывает реальный валовой национальный продукт США (GNPR) с использованием линейной комбинации индекса промышленного производства (IPI), общая занятость (E) и реальная заработная плата (WR).
β3WRt + αt.
Для всех - это ряд независимых гауссовых возмущений со средним значением 0 и дисперсией .
Предположим, что эти предыдущие распределения:
λ 2В M является вектором средства 4 на 1, V является масштабированной матрицей положительной определенной ковариации 4 на 4.
B А В - форма и масштаб, соответственно, обратного гамма-распределения.
Эти допущения и правдоподобие данных подразумевают нормально-обратно-гамма-сопряженную модель.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для последовательности ответа и предиктора.
load Data_NelsonPlosser varNames = {'IPI' 'E' 'WR'}; X = DataTable{:,varNames}; y = DataTable{:,'GNPR'};
Создайте нормально-обратно-гамма-сопряженную предыдущую модель для параметров линейной регрессии. Укажите количество предикторов p и имена переменных.
p = 3; PriorMdl = bayeslm(p,'ModelType','conjugate','VarNames',varNames);
PriorMdl является conjugateblm Объект байесовской модели линейной регрессии, представляющий предварительное распределение коэффициентов регрессии и дисперсии возмущений.
Моделирование набора коэффициентов регрессии и значения дисперсии возмущений из предыдущего распределения.
rng(1); % For reproducibility
[betaSimPrior,sigma2SimPrior] = simulate(PriorMdl)betaSimPrior = 4×1
-33.5917
-49.1445
-37.4492
-25.3632
sigma2SimPrior = 0.1962
betaSimPrior является случайно нарисованным 4 на 1 вектором коэффициентов регрессии, соответствующих именам в PriorMdl.VarNames. sigma2SimPrior выходной сигнал представляет собой случайную проводимую дисперсию скалярных возмущений.
Оцените апостериорное распределение.
PosteriorMdl = estimate(PriorMdl,X,y);
Method: Analytic posterior distributions
Number of observations: 62
Number of predictors: 4
Log marginal likelihood: -259.348
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | -24.2494 8.7821 [-41.514, -6.985] 0.003 t (-24.25, 8.65^2, 68)
IPI | 4.3913 0.1414 [ 4.113, 4.669] 1.000 t (4.39, 0.14^2, 68)
E | 0.0011 0.0003 [ 0.000, 0.002] 1.000 t (0.00, 0.00^2, 68)
WR | 2.4683 0.3490 [ 1.782, 3.154] 1.000 t (2.47, 0.34^2, 68)
Sigma2 | 44.1347 7.8020 [31.427, 61.855] 1.000 IG(34.00, 0.00069)
PosteriorMdl является conjugateblm Объект байесовской модели линейной регрессии, представляющий апостериорное распределение коэффициентов регрессии и дисперсию возмущений.
Смоделировать набор коэффициентов регрессии и значение дисперсии возмущений из заднего распределения.
[betaSimPost,sigma2SimPost] = simulate(PosteriorMdl)
betaSimPost = 4×1
-25.9351
4.4379
0.0012
2.4072
sigma2SimPost = 41.9575
betaSimPost и sigma2SimPost имеют те же размеры, что и betaSimPrior и sigma2SimPrior, соответственно, но выводятся из задней части.
Рассмотрим регрессионную модель в разделе Моделирование значения параметра из предыдущих и последующих распределений.
Загрузите данные и создайте сопряженную предыдущую модель для коэффициентов регрессии и дисперсии возмущений. Затем оцените апостериорное распределение и верните сводную таблицу оценки.
load Data_NelsonPlosser varNames = {'IPI' 'E' 'WR'}; X = DataTable{:,varNames}; y = DataTable{:,'GNPR'}; p = 3; PriorMdl = bayeslm(p,'ModelType','conjugate','VarNames',varNames); [PosteriorMdl,Summary] = estimate(PriorMdl,X,y);
Method: Analytic posterior distributions
Number of observations: 62
Number of predictors: 4
Log marginal likelihood: -259.348
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | -24.2494 8.7821 [-41.514, -6.985] 0.003 t (-24.25, 8.65^2, 68)
IPI | 4.3913 0.1414 [ 4.113, 4.669] 1.000 t (4.39, 0.14^2, 68)
E | 0.0011 0.0003 [ 0.000, 0.002] 1.000 t (0.00, 0.00^2, 68)
WR | 2.4683 0.3490 [ 1.782, 3.154] 1.000 t (2.47, 0.34^2, 68)
Sigma2 | 44.1347 7.8020 [31.427, 61.855] 1.000 IG(34.00, 0.00069)
Summary - таблица, содержащая статистику, которая estimate отображается в командной строке.
Хотя предельные и условные апостериорные распределения и аналитически прослеживаются, этот пример фокусируется на том, как реализовать пробоотборник Гиббса для воспроизведения известных результатов.
Оцените модель еще раз, но используйте образец Гиббса. Чередуют выборку из условных задних распределений параметров. Выполните выборку 10 000 раз и создайте переменные для предварительного распределения. Запустить пробоотборник с отсчетом от условного задника , приведенного 2.
m = 1e4; BetaDraws = zeros(p + 1,m); sigma2Draws = zeros(1,m + 1); sigma2Draws(1) = 2; rng(1); % For reproducibility for j = 1:m BetaDraws(:,j) = simulate(PriorMdl,X,y,'Sigma2',sigma2Draws(j)); [~,sigma2Draws(j + 1)] = simulate(PriorMdl,X,y,'Beta',BetaDraws(:,j)); end sigma2Draws = sigma2Draws(2:end); % Remove initial value from MCMC sample
График следовых графиков параметров.
figure; for j = 1:(p + 1); subplot(2,2,j); plot(BetaDraws(j,:)) ylabel('MCMC Draw') xlabel('Simulation Index') title(sprintf('Trace Plot — %s',PriorMdl.VarNames{j})); end

figure; plot(sigma2Draws) ylabel('MCMC Draw') xlabel('Simulation Index') title('Trace plot — Sigma2')

Образцы цепи Маркова Monte Carlo (MCMC), по-видимому, сходятся и хорошо перемешиваются.
Примените период горения в 1000 розыгрышей, а затем вычислите средние и стандартные отклонения образцов MCMC. Сравните их с оценками из estimate.
bp = 1000; postBetaMean = mean(BetaDraws(:,(bp + 1):end),2); postSigma2Mean = mean(sigma2Draws(:,(bp + 1):end)); postBetaStd = std(BetaDraws(:,(bp + 1):end),[],2); postSigma2Std = std(sigma2Draws((bp + 1):end)); [Summary(:,1:2),table([postBetaMean; postSigma2Mean],... [postBetaStd; postSigma2Std],'VariableNames',{'GibbsMean','GibbsStd'})]
ans=5×4 table
Mean Std GibbsMean GibbsStd
_________ __________ _________ __________
Intercept -24.249 8.7821 -24.293 8.748
IPI 4.3913 0.1414 4.3917 0.13941
E 0.0011202 0.00032931 0.0011229 0.00032875
WR 2.4683 0.34895 2.4654 0.34364
Sigma2 44.135 7.802 44.011 7.7816
Оценки очень близки. Различия учитываются в вариациях MCMC.
Рассмотрим регрессионную модель в разделе Моделирование значения параметра из предыдущих и последующих распределений.
Предположим, что эти предыдущие распределения для = 0,..., 3:
σVk2Z2, где и Z2 - независимые, стандартные нормальные случайные величины. Поэтому коэффициенты имеют гауссово распределение смеси. Предположим, что все коэффициенты условно независимы, априори, но они зависят от дисперсии возмущений.
B А В - форма и масштаб, соответственно, обратного гамма-распределения.
γk∈{0,1}and он представляет переменную режима включения со случайной переменной с дискретным равномерным распределением.
Создайте предыдущую модель для выполнения SSVS. Предположим, что и зависимы (модель сопряженной смеси). Укажите количество предикторов p и названия коэффициентов регрессии.
p = 3; PriorMdl = mixconjugateblm(p,'VarNames',["IPI" "E" "WR"]);
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для последовательности ответа и предиктора.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Вычислите количество возможных режимов, то есть количество комбинаций, которые являются результатом включения и исключения переменных в модели.
cardRegime = 2^(PriorMdl.Intercept + PriorMdl.NumPredictors)
cardRegime = 16
Смоделировать 10 000 режимов из заднего распределения.
rng(1);
[~,~,RegimeSim] = simulate(PriorMdl,X,y,'NumDraws',10000);RegimeSim является логической матрицей 4 на 1000. Строки соответствуют переменным в Mdl.VarNames, и столбцы соответствуют розыгрышам из заднего распределения.
Постройте гистограмму посещенных режимов. Перекодируйте режимы так, чтобы они были читаемыми. В частности, для каждого режима создайте строку, идентифицирующую переменные в модели, и разделите переменные точками.
cRegime = num2cell(RegimeSim,1); cRegime = categorical(cellfun(@(c)join(PriorMdl.VarNames(c),"."),cRegime)); cRegime(ismissing(cRegime)) = "NoCoefficients"; histogram(cRegime); title('Variables Included in Models') ylabel('Frequency');

Вычислите предельную заднюю вероятность включения переменных.
table(mean(RegimeSim,2),'RowNames',PriorMdl.VarNames,... 'VariableNames',"Regime")
ans=4×1 table
Regime
______
Intercept 0.8829
IPI 0.4547
E 0.098
WR 0.1692
Рассмотрим байесовскую модель линейной регрессии, содержащую один предиктор, и t-распределенную дисперсию возмущений с профилированным параметром степеней свободы
).
λ jstart2)
∝1σ2
Эти допущения подразумевают:
,
(
- вектор параметров скрытого масштаба, который приписывает низкую точность наблюдениям, далеким от линии регрессии. - гиперпараметр, контролирующий влияние на наблюдения.
Для этой задачи семплер Гиббса хорошо подходит для оценки коэффициентов, поскольку можно смоделировать параметры байесовской модели линейной регрессии, обусловленной , а затем смоделировать из её условного распределения.
Генерировать 100 отклики 2xt + et (0,0,52).
rng('default');
n = 100;
x = linspace(0,2,n)';
b0 = 1;
b1 = 2;
sigma = 0.5;
e = randn(n,1);
y = b0 + b1*x + sigma*e;Ввести внешние ответы путем раздувания всех ответов ниже 0,25 в 3 раза.
y(x < 0.25) = y(x < 0.25)*3;
Подгонка линейной модели к данным. Постройте график данных и соответствующей линии регрессии.
Mdl = fitlm(x,y)
Mdl =
Linear regression model:
y ~ 1 + x1
Estimated Coefficients:
Estimate SE tStat pValue
________ _______ ______ __________
(Intercept) 2.6814 0.28433 9.4304 2.0859e-15
x1 0.78974 0.24562 3.2153 0.0017653
Number of observations: 100, Error degrees of freedom: 98
Root Mean Squared Error: 1.43
R-squared: 0.0954, Adjusted R-Squared: 0.0862
F-statistic vs. constant model: 10.3, p-value = 0.00177
figure;
plot(Mdl);
hl = legend;
hold on;
Смоделированные отклонения, по-видимому, влияют на подогнанную линию регрессии.
Реализовать этот образец Гиббса:
Нарисуйте параметры из заднего распределения x, λ. Сдуйте на λ, создайте диффузную предыдущую модель с двумя коэффициентами регрессии и нарисуйте набор параметров из заднего. Первый коэффициент регрессии соответствует перехвату, поэтому укажите, чтоbayeslm не включают перехват.
Вычислить остатки.
Вычертите значения из условного задника .
Запустите образец Гиббса для 20000 итераций и примените период горения 5000. Укажите, 1, предварительно распределите для задних розыгрышей и λ для вектора единиц.
m = 20000; nu = 1; burnin = 5000; lambda = ones(n,m + 1); estBeta = zeros(2,m + 1); estSigma2 = zeros(1,m + 1); for j = 1:m yDef = y./sqrt(lambda(:,j)); xDef = [ones(n,1) x]./sqrt(lambda(:,j)); PriorMdl = bayeslm(2,'Model','diffuse','Intercept',false); [estBeta(:,j + 1),estSigma2(1,j + 1)] = simulate(PriorMdl,xDef,yDef); ep = y - [ones(n,1) x]*estBeta(:,j + 1); sp = (nu + 1)/2; sc = 2./(nu + ep.^2/estSigma2(1,j + 1)); lambda(:,j + 1) = 1./gamrnd(sp,sc); end
Хорошей практикой является диагностика образца MCMC путем изучения графиков трассировки. Для краткости этот пример пропускает эту задачу.
Вычислите среднее значение розыгрышей по заднему значению коэффициентов регрессии. Удаление розыгрышей периода горения.
postEstBeta = mean(estBeta(:,(burnin + 1):end),2)
postEstBeta = 2×1
1.3971
1.7051
Оценка перехвата ниже, и наклон выше, чем оценки, возвращаемые fitlm.
Постройте график надежной линии регрессии с линией регрессии, снабженной наименьшими квадратами.
h = gca; xlim = h.XLim'; plotY = [ones(2,1) xlim]*postEstBeta; plot(xlim,plotY,'LineWidth',2); hl.String{4} = 'Robust Bayes';

Линия регрессии подходит с использованием надежной байесовской регрессии, по-видимому, лучше подходит.
Максимальная оценка апостериорной вероятности (MAP) является задним режимом, то есть значением параметра, которое дает максимум заднего pdf. Если задний является аналитически труднореализуемым, то можно использовать выборку Монте-Карло для оценки MAP.
Рассмотрим модель линейной регрессии в разделе Моделирование значения параметра из предыдущих и последующих распределений.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для последовательности ответа и предиктора.
load Data_NelsonPlosser varNames = {'IPI' 'E' 'WR'}; X = DataTable{:,varNames}; y = DataTable{:,'GNPR'};
Создайте нормально-обратно-гамма-сопряженную предыдущую модель для параметров линейной регрессии. Укажите количество предикторов p и имена переменных.
p = 3; PriorMdl = bayeslm(p,'ModelType','conjugate','VarNames',varNames)
PriorMdl =
conjugateblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4x1 cell}
Mu: [4x1 double]
V: [4x4 double]
A: 3
B: 1
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
IPI | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
E | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
WR | 0 70.7107 [-141.273, 141.273] 0.500 t (0.00, 57.74^2, 6)
Sigma2 | 0.5000 0.5000 [ 0.138, 1.616] 1.000 IG(3.00, 1)
Оцените краевые апостериорные распределения и .
rng(1); % For reproducibility
PosteriorMdl = estimate(PriorMdl,X,y);Method: Analytic posterior distributions
Number of observations: 62
Number of predictors: 4
Log marginal likelihood: -259.348
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------------
Intercept | -24.2494 8.7821 [-41.514, -6.985] 0.003 t (-24.25, 8.65^2, 68)
IPI | 4.3913 0.1414 [ 4.113, 4.669] 1.000 t (4.39, 0.14^2, 68)
E | 0.0011 0.0003 [ 0.000, 0.002] 1.000 t (0.00, 0.00^2, 68)
WR | 2.4683 0.3490 [ 1.782, 3.154] 1.000 t (2.47, 0.34^2, 68)
Sigma2 | 44.1347 7.8020 [31.427, 61.855] 1.000 IG(34.00, 0.00069)
Дисплей включает в себя статистику крайнего заднего распределения.
Извлеките заднее среднее из задней модели и извлеките заднюю ковариацию из сводки оценки, возвращенной summarize.
estBetaMean = PosteriorMdl.Mu;
Summary = summarize(PosteriorMdl);
EstBetaCov = Summary.Covariances{1:(end - 1),1:(end - 1)};estBetaMean является вектором 4 на 1, представляющим среднее краевого заднего β. EstBetaCov является матрицей 4 на 4, представляющей ковариационную матрицу задней из .
Нарисуйте 10000 значений параметров из заднего распределения.
rng(1); % For reproducibility [BetaSim,sigma2Sim] = simulate(PosteriorMdl,'NumDraws',1e5);
BetaSim является матрицей 4 на 10000 произвольно нарисованных коэффициентов регрессии. sigma2Sim является 1 на 10000 вектором случайного распределения возмущений.
Транспонируйте и стандартизируйте матрицу коэффициентов регрессии. Вычислите корреляционную матрицу коэффициентов регрессии.
estBetaStd = sqrt(diag(EstBetaCov)');
BetaSim = BetaSim';
BetaSimStd = (BetaSim - estBetaMean')./estBetaStd;
BetaCorr = corrcov(EstBetaCov);
BetaCorr = (BetaCorr + BetaCorr')/2; % Enforce symmetryПоскольку краевые задние распределения известны, оцените задний pdf при всех смоделированных значениях.
betaPDF = mvtpdf(BetaSimStd,BetaCorr,68); a = 34; b = 0.00069; igPDF = @(x,ap,bp)1./(gamma(ap).*bp.^ap).*x.^(-ap-1).*exp(-1./(x.*bp));... % Inverse gamma pdf sigma2PDF = igPDF(sigma2Sim,a,b);
Найдите смоделированные значения, которые максимизируют соответствующие pdfs, то есть задние режимы.
[~,idxMAPBeta] = max(betaPDF); [~,idxMAPSigma2] = max(sigma2PDF); betaMAP = BetaSim(idxMAPBeta,:); sigma2MAP = sigma2Sim(idxMAPSigma2);
betaMAP и sigma2MAP являются оценками MAP.
Поскольку задняя часть является симметричной и унимодальной, задняя средняя и MAP должны быть одинаковыми. Сравните оценку MAP с его задним средним значением.
table(betaMAP',PosteriorMdl.Mu,'VariableNames',{'MAP','Mean'},... 'RowNames',PriorMdl.VarNames)
ans=4×2 table
MAP Mean
_________ _________
Intercept -24.559 -24.249
IPI 4.3964 4.3913
E 0.0011389 0.0011202
WR 2.4473 2.4683
Оценки довольно близки друг к другу.
Оцените аналитическую моду заднегруди, относящейся . Сравните его с расчётной МАП
igMode = 1/(b*(a+1))
igMode = 41.4079
sigma2MAP
sigma2MAP = 41.4075
Эти оценки также довольно близки.
simulate не может извлекать значения из неправильного распределения, то есть распределения, плотность которого не интегрируется в 1.
Если Mdl является empiricalblm объект модели, то вы не можете указать Beta или Sigma2. Нельзя моделировать из условных задних распределений с помощью эмпирического распределения.
Каждый раз, когда simulate должен оценить апостериорное распределение (например, когда Mdl представляет собой предыдущее распределение, и вы поставляете X и y) и задняя является аналитически отслеживаемой, simulate моделируется непосредственно с задней стороны. В противном случае simulate прибегает к моделированию Монте-Карло для оценки заднего. Дополнительные сведения см. в разделе Апостериорная оценка и вывод.
Если Mdl является задней моделью сустава, то simulate моделирует данные из него по-разному по сравнению с Mdl является совместной предыдущей моделью, и вы поставляете X и y. Таким образом, если задать одно и то же случайное начальное число и создать случайные значения обоими способами, то могут не быть получены одинаковые значения. Однако соответствующие эмпирические распределения, основанные на достаточном количестве розыгрышей, фактически эквивалентны.
На этом рисунке показано, как simulate уменьшает выборку, используя значения NumDraws, Thin, и BurnIn.
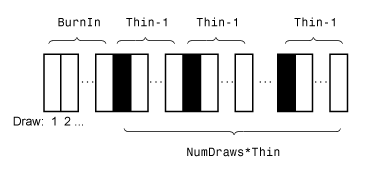
Прямоугольники представляют последовательные розыгрыши из распределения. simulate удаляет белые прямоугольники из образца. Остающееся NumDraws образец составляют черные прямоугольники.
Если Mdl является semiconjugateblm объект модели, затем simulate образцы из заднего распределения путем применения образца Гиббса.
simulate использует значение по умолчанию Sigma2Start для start2 и рисует значение β из λ (β 'start2, X, y).
simulate рисует значение, равное λ 2, из δ2 | β, X, y), используя ранее сгенерированное значение β.
Функция повторяет шаги 1 и 2 до сходимости. Чтобы оценить сходимость, нарисуйте график трассировки образца.
При указании BetaStart, то simulate вычерчивает значение, равное start2, из δ (start2 | β, X, y), чтобы запустить пробоотборник Гиббса.simulate не возвращает это генерируемое значение, равное
Если Mdl является empiricalblm объект модели и вы не поставляете X и y, то simulate рисует из Mdl.BetaDraws и Mdl.Sigma2Draws. Если NumDraws меньше или равно numel(Mdl.Sigma2Draws), то simulate возвращает первое NumDraws элементы Mdl.BetaDraws и Mdl.Sigma2Draws в виде случайных розыгрышей для соответствующего параметра. В противном случае simulate случайные повторные выборки NumDraws элементы из Mdl.BetaDraws и Mdl.Sigma2Draws.
Если Mdl является customblm объект модели, затем simulate использует пробоотборник MCMC для извлечения из заднего распределения. При каждой итерации программное обеспечение объединяет текущие значения коэффициентов регрессии и дисперсии возмущений в (Mdl.Intercept + Mdl.NumPredictors + 1) -by-1 вектор и передает его вMdl.LogPDF. Значение дисперсии возмущений является последним элементом этого вектора.
Пробоотборник HMC требует как логарифмической плотности, так и его градиента. Градиент должен быть (NumPredictors+Intercept+1)вектор -by-1. Если производные определенных параметров трудно вычислить, то в соответствующих местах градиента подать NaN вместо этого значения. simulate заменяет NaN значения с числовыми производными.
Если Mdl является lassoblm, mixconjugateblm, или mixsemiconjugateblm объект модели и поставка X и y, то simulate образцы из заднего распределения путем применения образца Гиббса. Если данные не предоставляются, то simulate образцы из аналитических, безусловных предыдущих распределений.
simulate не возвращает созданные по умолчанию начальные значения.
Если Mdl является mixconjugateblm или mixsemiconjugateblm, то simulate сначала извлекает из распределения режима, учитывая текущее состояние цепочки (значения RegimeStart, BetaStart, и Sigma2Start). Если нарисовать один образец и не указывать значения для RegimeStart, BetaStart, и Sigma2Start, то simulate использует значения по умолчанию и выдает предупреждение.
conjugateblm | customblm | diffuseblm | empiricalblm | lassoblm | mixconjugateblm | mixsemiconjugateblm | semiconjugateblm