Поиск групп и возврат номеров групп
G = findgroups(A)G, вектор номеров групп, созданный из переменной группирования A. Выходной аргумент G содержит целочисленные значения от 1 до N, с указанием N отдельные группы для N уникальные значения в A. Например, если A является {'b','a','a','b'}, то findgroups прибыль G как [2 1 1 2]. Вы можете использовать G для разделения групп данных из других переменных. Использовать G в качестве входного аргумента для splitapply в рабочем процессе Split-Apply-Combine.
findgroups обрабатывает пустые векторы символов и NaN, NaTи неопределенные категориальные значения в A как отсутствующие значения и возвраты NaN в качестве соответствующих элементов G.
G = findgroups(A1,...,AN)A1,...,AN. findgroups функция определяет группы как уникальные комбинации значений A1,...,AN. Например, если A1 является {'a','a','b','b'} и A2 является [0 1 0 0], то findgroups(A1,A2) прибыль G как [1 2 3 3], потому что комбинация 'b' 0 происходит дважды.
[ также возвращает уникальные значения для каждой группы G,ID1,...,IDN] = findgroups(A1,...,AN)ID1,...,IDN. Значения по всему ID1,...,IDN определите группы. Например, если A1 является {'a','a','b','b'} и A2 является [0 1 0 0], то findgroups(A1,A2) прибыль G как [1 2 3 3], и ID1 и ID2 как {'a','a','b'} и [0 1 0].
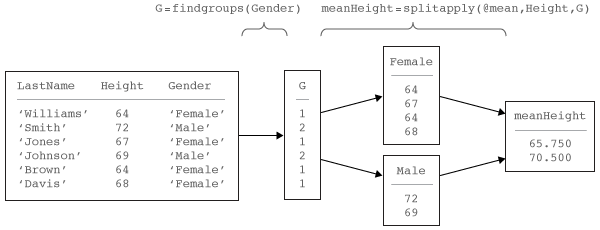
Рабочий процесс Split-Apply-Combine является обычным в анализе данных. В этом потоке операций аналитик разбивает данные на группы, применяет функцию к каждой группе и объединяет результаты. На диаграмме показан типичный пример рабочего процесса и его части, реализованные findgroups и splitapply.
accumarray | arrayfun | convertvars | discretize | groupsummary | histcounts | ismember | rowfun | splitapply | unique | varfun | vartype
