Разбить данные на группы и применить функцию
Y = splitapply( разделения func,X,G)X в группы, указанные G и применяет функцию func к каждой группе. splitapply прибыль Y как массив, который содержит конкатенированные выходы из func для групп, разделенных из X. Входной аргумент G - вектор положительных целых чисел, указывающий группы, к которым относятся соответствующие элементы X принадлежат. Если G содержит NaN значения, splitapply пропускает соответствующие значения в X при разделении X на группы. Создать G, вы можете использовать findgroups функция.
splitapply объединяет два шага в рабочем процессе Split-Apply-Combine.
[Y1,...,YM] = splitapply(___) разбивает переменные на группы и применяет func к каждой группе. func возвращает несколько выходных аргументов. Y1,...,YM содержит конкатенированные выходы из func для групп, разделенных на переменные входных данных. func может возвращать выходные аргументы, принадлежащие различным классам, но класс каждого вывода должен быть одинаковым каждый раз func вызывается. Этот синтаксис можно использовать с любым из входных аргументов предыдущих синтаксисов.
Число выходных аргументов из func не обязательно должно совпадать с числом входных аргументов, указанных X1,...,XN.
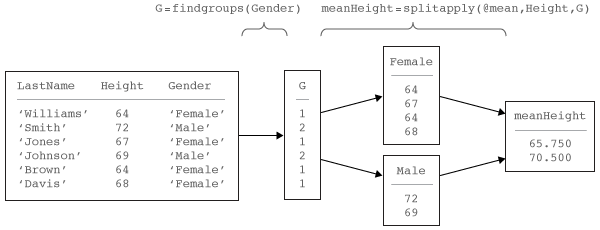
Рабочий процесс Split-Apply-Combine является обычным в анализе данных. В этом потоке операций аналитик разбивает данные на группы, применяет функцию к каждой группе и объединяет результаты. На диаграмме показан типичный пример рабочего процесса и его части, реализованные findgroups и splitapply.
accumarray | arrayfun | convertvars | discretize | findgroups | groupsummary | histcounts | rowfun | unique | varfun | vartype
