Функция эффективна при четком разделении групп данных с различными метками переменных условий. Diagnostic Feature Designer предоставляет различные опции функций, но наиболее эффективные функции зависят от данных, систем и условий, которые представляют данные.
Для выполнения предварительной оценки эффективности функции можно оценить гистограмму функции. График гистограммы визуализирует разделение между помеченными группами. Для этого гистограмма сохраняет распределение данных и использует цвет для идентификации групп меток в каждой ячейке. Гистограмму можно настроить для улучшения визуализации и выделения информации в интересующих элементах. Можно также просмотреть числовую информацию о разделении между распределениями групп.
Гистограммы позволяют получить раннее ощущение эффективности функции. Чтобы выполнить более строгую количественную оценку с использованием специализированных статистических методов, используйте ранжирование, как описано в разделе Ранжирование функций в исследовании данных ансамбля и сравнение функций с помощью конструктора диагностических функций. Вычисления ранжирования элементов не зависят от выбора визуализации, сделанного во время анализа гистограммы.
На следующем рисунке показана визуализация разделения. Эти примеры имеют относительно небольшой размер выборки, что преувеличивает различия.
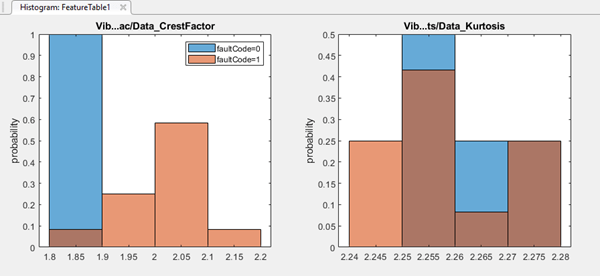
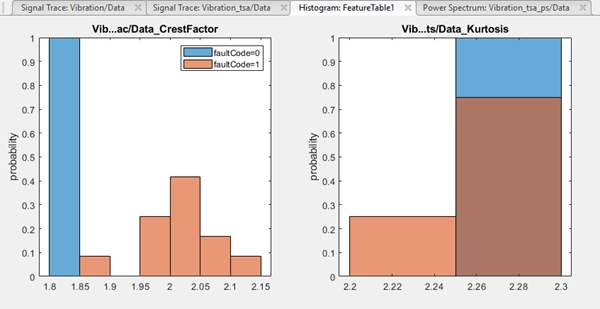
На обоих участках код состояния двух состояний faultCode. Значение 0 (синий) указывает на исправную систему, а значение 1 (оранжевый) - на неисправную систему. Гистограммы представляют фактор гребня и куртоз Vibration сигнал.
Гистограмма коэффициента гребня показывает, что:
Все значения исправной системной функции находятся в пределах диапазона первой ячейки.
Большая часть неисправных системных значений попадает в оставшиеся три ячейки.
Первая ячейка также содержит некоторые данные из неисправной системы, но их количество невелико по сравнению с данными исправной системы.
Для этого случая гистограмма показывает, что признак коэффициента гребня различает здоровое и неисправное поведение хорошо, но не полностью.
Напротив, гистограмма куртоза показывает, что:
Данные со значениями в диапазоне первой ячейки всегда неисправны.
Данные в пределах диапазона других ячеек поступают как от здоровых, так и от неисправных групп. Состояние неисправности неоднозначно в этих регионах.
Из этих двух гистограмм можно сделать вывод, что функция фактора гребня более эффективна, чем функция куртоза.
Приложение предоставляет интерактивные инструменты для настройки гистограммы. Например, можно увеличить разрешение гистограммы, изменив ширину ячейки, переменную условия, определяющую группы, или изменив нормализацию, применяемую гистограммой. Дополнительные сведения о настройке гистограмм в приложении см. в разделе Создание и настройка гистограмм функций.
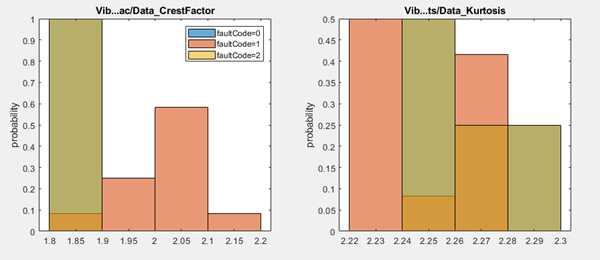
Если переменная условия имеет более двух состояний или классов, полученные гистограммы может быть труднее интерпретировать самостоятельно из-за дополнительных комбинаций цветов. Например, предположим, что код отказа может представлять два независимых состояния отказа в дополнение к состоянию работоспособности, fault1 и fault2. На следующем рисунке показаны гистограммы, аналогичные предыдущим гистограммам, но соответствующие такой трехклассной переменной условия.
Дополнительные сведения об эффективности функции можно получить, просмотрев числовые групповые расстояния. Опция Show Group Distance предоставляет значение KS statistic для каждой комбинации классов переменных условий. Используя тест Колмогорова-Смирнова с двумя выборками, статистика КС показывает, насколько хорошо разделены кумулятивные функции распределения распределений двух классов.
В следующей таблице показаны групповые расстояния, соответствующие предыдущим гистограммам.
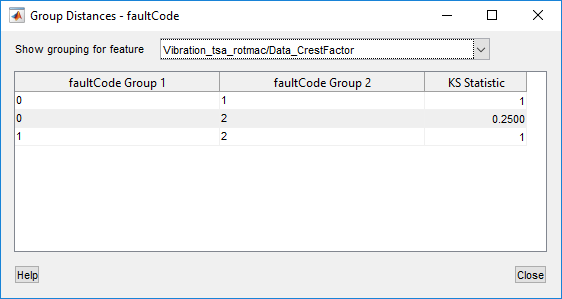
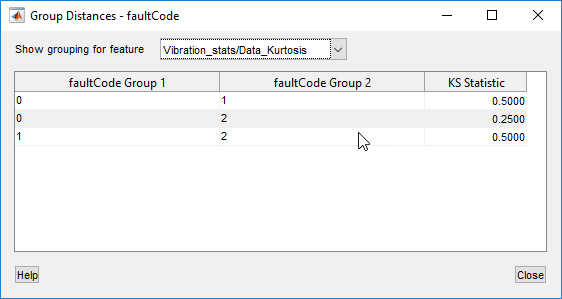
Статистика KS показывает разделение между каждым спариванием faultCode значения. Статистическое значение находится в диапазоне от 0 до 1, где 0 - отсутствие разделения между распределениями, а 1 - полное разделение.
Для элемента коэффициента гребня, как для двухклассного faultCode, дифференциация между здоровыми fault0 и неисправен fault1 данные сильны, со статистикой KS 1. Дифференциация также сильна между fault1 и fault2 данные. Однако различие между fault0 и fault2 данные относительно скудны.
Для признака куртоза дифференциация между парами во всех парах является относительно плохой.
Для получения дополнительной информации о статистике KS см. kstest2.
Чтобы создать набор гистограмм элементов из таблицы элементов, выполните следующие действия.
Выберите таблицу элементов в разделе «Таблицы элементов» браузера данных.
Щелкните значок «Гистограмма» в галерее печати.
Чтобы оптимизировать визуализацию разделения, настройте гистограммы. На вкладке Гистограмма (Histogram) представлены параметры, позволяющие изменить гистограмму для улучшения интерпретации.

По умолчанию приложение строит гистограммы для всех ваших функций и отображает их в обратном алфавитном порядке. Чтобы сосредоточиться на меньшем наборе элементов, щелкните Выбрать элементы (Select Features).
Можно сгруппировать данные в наборе гистограмм для любой импортированной переменной условия. Эта переменная условия может указывать на работоспособность системы. Переменная также может быть рабочим состоянием, таким как температура или режим работы машины. Чтобы выбрать переменную условия для группирования по цветовому коду, выберите переменную из списка Группировать по.
Чтобы отобразить расстояние разделения группы (KS Statistic), которое обсуждалось в разделе Интерпретация гистограмм элементов для многоклассных переменных условий, щелкните Показать расстояние группы (Show Group Distance). Эта опция используется для вывода таблицы, содержащей значение разделения групп для каждой пары значений переменных условий. В окне выберите функцию, которую требуется изучить.
По умолчанию размер ячейки определяется автоматически. Переопределите автоматизацию, введя другое значение ширины ячейки или выбрав альтернативный метод смешивания. Настройки ячейки применяются ко всем гистограммам таблицы элементов.

Настройки ячейки для ширины ячейки, метода вставки и количества ячеек не являются независимыми. Алгоритм использует порядок приоритетности, чтобы определить, что использовать:
Метод Binning является драйвером по умолчанию для ширины ячейки.
Спецификация Bin Width переопределяет метод Binning.
Ширина ячейки и независимые пределы ячейки определяют количество ячеек. Спецификация «Количество ячеек» действует только при отсутствии группировки данных.
По умолчанию Diagnostic Feature Designer использует алгоритм автоматического объединения, который возвращает ячейки с равномерной шириной ячеек. Алгоритм выбирает настройки ячейки, чтобы охватить диапазон данных и показать основную форму распределения. Чтобы изменить алгоритм binning, выберите в меню Binning Method.
Для получения информации о алгоритмах связывания см. ‘BinMethod’ описание в histogram.
Увеличьте разрешение данных, указав ширину, которая меньше ширины ‘auto’ Параметр определяет рассматриваемую функцию. Например, на следующем рисунке повторяются более ранние гистограммы, показывающие разделение данных для двух значений кода отказа и двух функций. Для коэффициента гребня первый бункер смешал здоровые и ухудшенные данные.
Ширина ячейки для элемента «Коэффициент гребня» равна 0,1. Если уменьшить ширину ячейки до 0,05, гистограмма изменится, как показано здесь.
Теперь здоровые данные коэффициента гребня изолированы от первого бункера, а остальные бункеры содержат только нездоровые данные. Однако разрешение на гистограмме куртоза потеряно, поскольку указанная ширина ячейки применяется ко всем элементам.
Если вы заинтересованы только в части распределения элементов, используйте «Пределы ячейки» для исключения данных за пределы интересующей области. Введите требуемые лимиты в форме [lower upper]. Этот выбор не влияет на расчет статистики KS в таблице расстояний группы.
Гистограммы по умолчанию используют вероятность для оси y с соответствующим диапазоном от 0 до 1 для всех элементов. Просмотр нескольких гистограмм в одном масштабе упрощает визуальное сравнение. Выберите другие настройки оси в меню Нормализация (Normalization). Эти методы включают в себя подсчет необработанных данных и статистические метрики, такие как CDF.
Конструктор диагностических функций | histogram | kstest2
