Приложение Diagnostic Feature Designer позволяет выполнять часть процесса предиктивного технического обслуживания с помощью многофункционального графического интерфейса. Элементы проектируются и сравниваются в интерактивном режиме. Затем определите, какие функции лучше всего различать между данными из различных групп, такими как данные из номинальных систем и из неисправных систем. При наличии данных о сбое можно также оценить, какие функции лучше всего подходят для определения остаточного срока службы (RUL). Наиболее эффективные функции в конечном итоге становятся вашими показателями состояния для диагностики неисправностей и прогностики.
На следующем рисунке показана взаимосвязь между рабочим процессом предиктивного обслуживания и функциями конструктора диагностических функций.
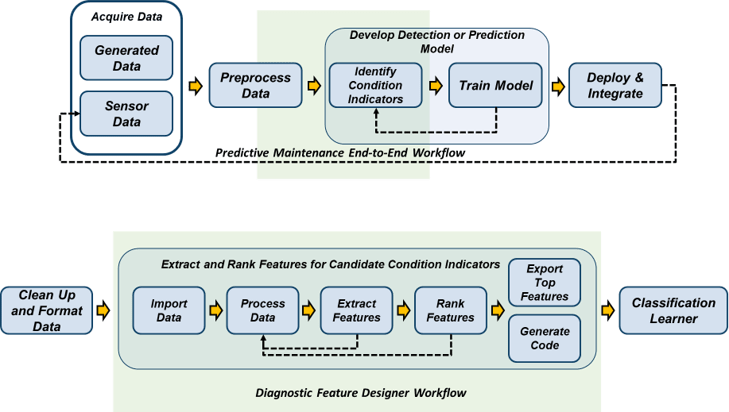
Приложение работает с данными ансамбля. Данные ансамбля содержат измерения данных от нескольких членов, таких как несколько аналогичных машин, или одной машины, данные которой сегментированы по интервалу времени, такому как дни или годы. Данные могут также включать переменные условия, которые описывают состояние отказа или рабочее состояние члена ансамбля. Часто переменные условия имеют определенные значения, известные как метки. Дополнительные сведения об ансамблях данных см. в разделе Ансамбли данных для мониторинга состояния и предиктивного обслуживания.
Рабочий процесс внутри приложения запускается в точке импорта данных с уже имеющимися данными:
Предварительно обработано с помощью функций очистки
Организованы в отдельные файлы данных или в один файл данных ансамбля, содержащий или ссылающийся на всех участников ансамбля
В Diagnostic Feature Designer рабочий процесс включает шаги, необходимые для дальнейшей обработки данных, извлечения элементов из данных и ранжирования этих элементов по эффективности. Рабочий процесс завершается выбором наиболее эффективных функций и их экспортом в приложение Classification Learner для обучения модели.
Рабочий процесс включает дополнительный шаг создания кода MATLAB ®. При создании кода, фиксирующего вычисления для выбранных элементов, можно автоматизировать эти вычисления для большего набора данных измерений, включающего большее количество элементов, таких как аналогичные машины различных заводов. Результирующий набор функций предоставляет дополнительные обучающие данные для Classification Learner.
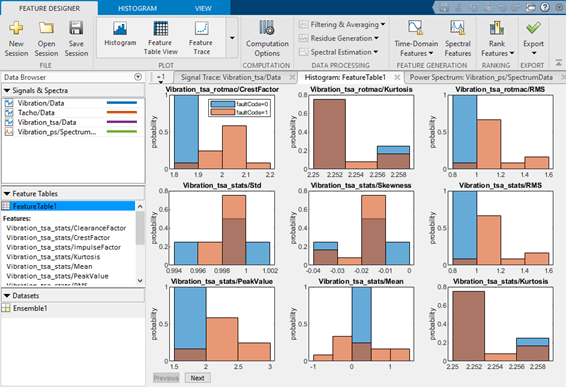
На следующем рисунке показаны основные функциональные возможности Diagnostic Feature Designer. Взаимодействуйте с данными и результатами с помощью элементов управления на вкладках, таких как вкладка Конструктор элементов (Feature Designer), показанная на рисунке. Просмотр импортированных и производных переменных, элементов и наборов данных в браузере данных. Визуализация результатов в области печати.
Первым шагом в использовании приложения является создание нового сеанса и импорт данных. Можно импортировать данные из таблиц, расписаний, массивов ячеек или матриц. Также можно импортировать хранилище данных ансамбля, содержащее информацию, позволяющую приложению взаимодействовать с внешними файлами данных. Файлы могут содержать фактические или смоделированные данные измерений во временной области, спектральные модели или данные, имена переменных, переменные условия и рабочие переменные, а также функции, созданные ранее. Diagnostic Feature Designer объединяет все данные участников в единый набор данных ансамбля. В этом наборе данных каждая переменная является сводным сигналом или моделью, которая содержит все индивидуальные значения элементов.
Чтобы использовать одни и те же данные в нескольких сессиях, можно сохранить начальную сессию в файле сессии. Данные сеанса включают как импортированные переменные, так и любые вычисленные дополнительные переменные и элементы. В следующем сеансе можно открыть файл сеанса и продолжить работу с импортированными и производными данными.
Сведения о подготовке и импорте данных см. в следующих разделах:
Сведения о самом процессе импорта см. в разделе Импорт и визуализация данных ансамбля в конструкторе диагностических функций.
Для построения графика сигналов или спектров, которые импортируются или генерируются с помощью инструментов обработки, выберите в галерее печати. На рисунке показана типичная сигнальная трассировка. Интерактивные инструменты печати позволяют выполнять панорамирование, зумирование, отображать расположение пиков и расстояния между пиками, а также показывать статистические изменения в пределах ансамбля. Группирование данных по меткам условий на графиках позволяет четко определить, поступают ли данные об элементах, например, из номинальных или неисправных систем.
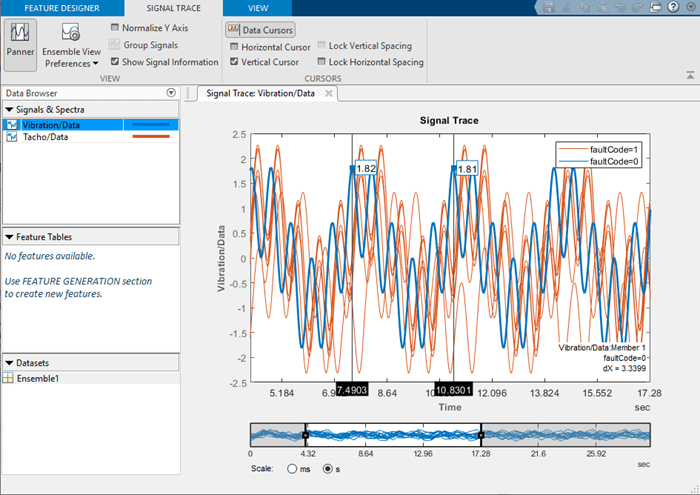
Сведения о печати в приложении см. в разделе Импорт и визуализация данных ансамбля в конструкторе диагностических функций.
Для изучения данных и подготовки данных к извлечению элементов используйте инструменты обработки данных. При каждом применении инструмента обработки приложение создает новую производную переменную с именем, которое содержит как исходную переменную, так и последний использованный шаг обработки. Например:
при применении обработки TSA к переменной Vibration/Data, новое производное имя переменной Vibration_tsa/Data.
Если затем вычислить спектр мощности из Vibration_tsa/Data, новое имя переменной Vibration_ps/SpectrumData. Это новое имя отражает как самую последнюю обработку ps и тот факт, что переменная является спектром, а не сигналом.
В подсказке для нового спектра отображаются источники, представляющие шаги обработки. Vibration/Data->Vibration_tsa/Data.
Варианты обработки данных для всех сигналов включают в себя статистику уровня ансамбля, остатки сигналов, фильтрацию и спектр мощности и порядка. Можно также выполнить интерполяцию данных в однородную сетку, если выборки элементов не выполняются с одинаковыми независимыми переменными интервалами.
Если ваши данные поступают от вращающегося оборудования, вы можете выполнять усреднение синхросигнала (TSA) на основе выходов тахометра или номинальной частоты вращения. Из сигнала TSA можно генерировать дополнительные сигналы, такие как остаточные и разностные сигналы TSA. Эти сигналы, полученные с помощью TSA, изолируют физические компоненты системы, сохраняя или отбрасывая гармоники и боковые полосы, и они являются основой для многих функций условий передачи.
Многие из опций обработки могут использоваться независимо. Некоторые опции могут или должны выполняться как последовательность. В дополнение к ранее рассмотренным сигналам вращающегося оборудования и TSA, другим примером является генерация остатка для любого сигнала. Вы можете:
Команда Ensemble Statistics используется для генерации отдельных статистических переменных, таких как среднее и максимальное значение, характеризующих весь ансамбль.
Команда Вычесть ссылку (Subtract Reference) используется для генерации остаточных сигналов для каждого элемента путем вычитания значений уровня ансамбля. Эти остатки представляют вариации между сигналами, и более четко обнаруживают сигналы, которые отклоняются от остальной части ансамбля.
Эти остаточные сигналы используются в качестве источника для дополнительных опций обработки или для создания элементов.
Сведения о параметрах обработки данных в приложении см. в разделах Обработка данных и изучение возможностей в конструкторе диагностических функций.
Приложение предоставляет возможности сегментации сигналов, локальной буферизации в приложении значений хранилища данных ансамбля и параллельной обработки.
По умолчанию приложение обрабатывает весь сигнал за одну операцию. Можно также сегментировать сигналы и обрабатывать отдельные кадры. Обработка кадров особенно полезна, если участники ансамбля проявляют нестационарное, изменяющееся во времени или периодическое поведение. Обработка на основе кадров также поддерживает прогностическое ранжирование, поскольку она обеспечивает временную историю значений признаков.
При импорте данных участника в приложение приложение создает локальный ансамбль и записывает в него новые переменные и функции. При импорте объекта хранилища данных ансамбля приложение по умолчанию взаимодействует с внешними файлами, перечисленными в объекте. Если вы не хотите, чтобы приложение записывало в ваши внешние файлы, вы можете выбрать, чтобы приложение создавало локальный ансамбль и записывало результаты там. После получения требуемых результатов можно экспортировать ансамбль в рабочую область MATLAB. Оттуда можно записать переменные и функции, которые требуется сохранить, в исходные файлы с помощью функций хранилища данных ансамбля командной строки. Дополнительные сведения о хранилищах данных ансамбля см. в разделе Ансамбли данных для мониторинга состояния и предиктивного обслуживания.
При наличии Toolbox™ параллельных вычислений можно использовать параллельную обработку. Поскольку приложение часто выполняет одну и ту же обработку независимо от всех участников, параллельная обработка может значительно увеличить время вычислений.
На основе исходных и производных сигналов и спектров можно вычислить характеристики и оценить их эффективность. Возможно, вы уже знаете, какие функции могут работать лучше всего, или хотите поэкспериментировать со всеми применимыми функциями. Доступные функции варьируются от общей статистики сигналов до специальных показателей состояния зубчатой передачи, которые могут идентифицировать точное местоположение неисправностей, и нелинейные функции, которые выделяют хаотичное поведение.
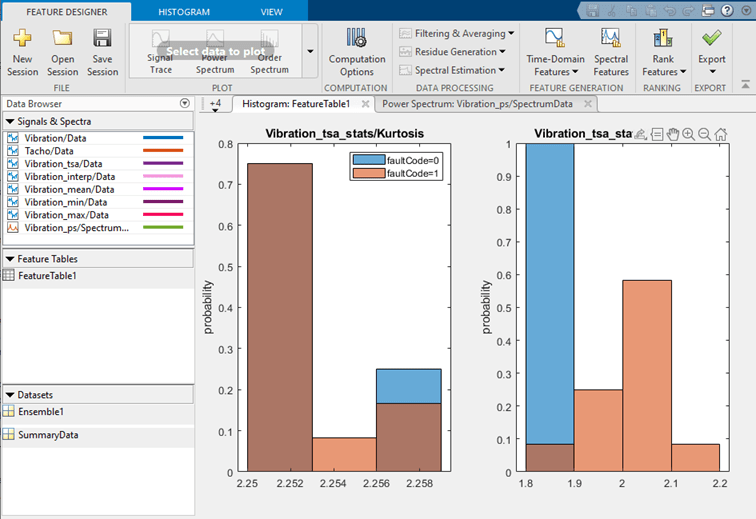
При каждом вычислении набора функций приложение добавляет их в таблицу функций и создает гистограмму распределения значений между участниками. На рисунке показаны гистограммы для двух признаков. Гистограммы показывают, насколько хорошо каждый элемент дифференцирует данные. Например, предположим, что переменная условия faultCode с состояниями 0 для номинальных системных данных и 1 для данных неисправной системы, как показано на рисунке. В гистограмме можно увидеть, приводит ли номинальная и неисправная группировки к различным или смешанным ячейкам гистограммы. Вы можете просмотреть все гистограммы функций одновременно или выбрать, какие функции включает приложение в набор графиков гистограмм.
Чтобы сравнить значения всех элементов вместе, используйте представление таблицы элементов и график трассировки элементов. В представлении таблицы элементов отображается таблица всех значений элементов всех участников ансамбля. Трассировка элемента отображает эти значения. Этот график визуализирует расхождение значений элементов в ансамбле и позволяет определить конкретный элемент, который представляет значение элемента.
Для получения информации о создании функций и интерпретации гистограмм в приложении см.:
Гистограммы позволяют выполнить начальную оценку эффективности функции. Чтобы выполнить более строгую относительную оценку, можно ранжировать свои функции с помощью специализированных статистических методов. Приложение предоставляет два типа ранжирования - классификационное ранжирование и прогностическое ранжирование.
Методы ранжирования классификации оценивают и ранжируют особенности по способности различать между группами данных, например между номинальным и ошибочным поведением. Классификационное ранжирование требует переменных условий, которые содержат метки, характеризующие группы данных.
Методы прогностического ранжирования оценивают и ранжируют характеристики, основанные на способности отслеживать деградацию, чтобы обеспечить возможность прогнозирования оставшегося срока полезного использования (RUL). Прогностическое ранжирование требует реальных или смоделированных данных о переходе к отказу или прогрессировании отказа и не использует переменные условия.
На рисунке показаны результаты ранжирования классификации. Можно попробовать несколько методов ранжирования и просмотреть результаты каждого метода вместе. Результаты ранжирования позволяют исключить неэффективные элементы и оценить эффекты ранжирования корректировок параметров при вычислении производных переменных или элементов.
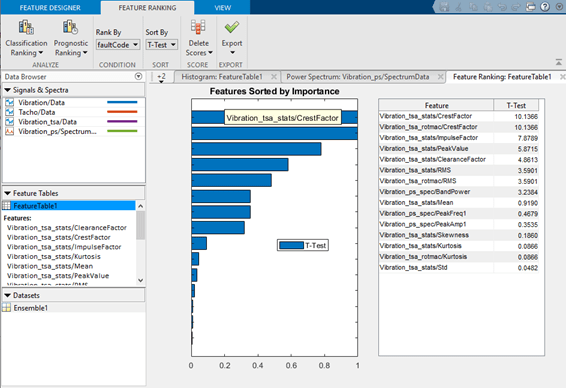
Для получения информации о ранжировании функций см.:
Ранг и экспорт функций в конструкторе диагностических функций
Разделы Diagnostic Feature Designer (Конструктор диагностических функций) для закладок Feature Ranking (Ранжирование
После определения набора потенциальных функций их можно экспортировать в приложение Classification Learner в Toolbox™ Статистика и машинное обучение. Classification Learner обучает модели классификации данных с помощью автоматических методов тестирования различных типов моделей с набором функций. При этом Classification Learner определяет лучшую модель и наиболее эффективные функции. Для прогностического обслуживания целью использования Classification Learner является выбор и обучение модели, которая различает данные из здоровых и неисправных систем. Эту модель можно включить в алгоритм обнаружения и прогнозирования неисправностей. Пример экспорта из приложения в Classification Learner см. в разделе Анализ и выбор функций диагностики насоса.
Можно также экспортировать элементы и наборы данных в рабочую область MATLAB. Это позволяет визуализировать и обрабатывать исходные и производные данные ансамбля с помощью функций командной строки или других приложений. В командной строке можно также сохранить выбранные элементы и переменные в файлы, включая файлы, на которые имеются ссылки в хранилище данных ансамбля.
Сведения об экспорте см. в разделе Ранг и экспорт функций в конструкторе диагностических функций.
Создайте код для выбранных элементов, чтобы можно было автоматизировать вычисления элементов с помощью функции MATLAB. Например, предположим, что у вас есть большой набор входных данных со многими членами, но для более быстрого ответа приложения вы хотите использовать подмножество этих данных при первом интерактивном изучении возможных функций. После определения наиболее эффективных функций с помощью приложения можно создать код, а затем применить те же вычисления для этих функций к набору данных всех элементов с помощью созданного кода. Более крупный набор участников позволяет предоставлять больше образцов в качестве учебных материалов для Classification Learner.
function [featureTable,outputTable] = diagnosticFeatures(inputData) %DIAGNOSTICFEATURES recreates results in Diagnostic Feature Designer. %
Конструктор диагностических функций
