Сравнение точности двух классификационных моделей с использованием новых данных
compareHoldout статистически оценивает точность двух классификационных моделей. Функция сначала сравнивает их предсказанные метки с истинными метками, а затем обнаруживает, является ли разница между показателями неправильной классификации статистически значимой.
Можно определить, отличается ли точность классификационных моделей или одна модель работает лучше другой. compareHoldout может проводить несколько вариаций теста МакНемара, включая асимптотический тест, точно-условный тест и тест среднего p-значения. Для оценки с учетом затрат доступные тесты включают тест хи-квадрат (требует Toolbox™ оптимизации) и тест отношения правдоподобия.
h = compareHoldout(C1,C2,T1,T2,ResponseVarName)C1 и C2 имеют одинаковую точность для прогнозирования меток истинного класса в ResponseVarName переменная. Альтернативная гипотеза заключается в том, что метки имеют неравную точность.
Первая классификационная модель C1 использует данные предиктора в T1и вторую классификационную модель C2 использует данные предиктора в T2. Столы T1 и T2 должен содержать одну и ту же переменную ответа, но может содержать различные наборы предикторов. По умолчанию программа проводит тест McNemar среднего значения p для сравнения точности.
h = 1 указывает на отклонение нулевой гипотезы на уровне значимости 5%. h = 0 указывает, что не отклоняет нулевую гипотезу на уровне 5%.
Ниже приведены примеры тестов, которые можно провести:
Сравните точность простой классификационной модели и модели, которая более сложна, передав один и тот же набор данных предиктора (то есть T1 = T2).
Сравните точность двух потенциально разных моделей, используя два потенциально разных набора предикторов.
Выполните выбор различных типов элементов. Например, можно сравнить точность модели, обученной с помощью набора предикторов, с точностью модели, обученной на подмножестве или другом наборе этих предикторов. Вы можете выбрать набор предикторов произвольно или использовать метод выбора функции, такой как PCA или последовательный выбор функции (см. pca и sequentialfs).
h = compareHoldout(C1,C2,T1,T2,Y)C1 и C2 имеют одинаковую точность для прогнозирования меток истинного класса Y. Альтернативная гипотеза заключается в том, что метки имеют неравную точность.
Первая классификационная модель C1 использует данные предиктора T1и вторую классификационную модель C2 использует данные предиктора T2. По умолчанию программа проводит тест McNemar среднего значения p для сравнения точности.
h = compareHoldout(C1,C2,X1,X2,Y)C1 и C2 имеют одинаковую точность для прогнозирования меток истинного класса Y. Альтернативная гипотеза заключается в том, что метки имеют неравную точность.
Первая классификационная модель C1 использует данные предиктора X1и вторую классификационную модель C2 использует данные предиктора X2. По умолчанию программа проводит тест McNemar среднего значения p для сравнения точности.
h = compareHoldout(___,Name,Value)
Обучайте два k-ближайших классификатора соседей, один из которых использует подмножество предикторов, используемых для другого. Проведение статистического теста, сравнивающего точность двух моделей на тестовом наборе.
Загрузить carsmall набор данных.
load carsmallСоздание двух таблиц входных данных, в которых вторая таблица исключает предиктор Acceleration. Определить Model_Year в качестве переменной ответа.
T1 = table(Acceleration,Displacement,Horsepower,MPG,Model_Year); T2 = T1(:,2:end);
Создайте раздел, разделяющий данные на обучающие и тестовые наборы. Храните 30% данных для тестирования.
rng(1) % For reproducibility CVP = cvpartition(Model_Year,'holdout',0.3); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP является объектом раздела перекрестной проверки, определяющим обучающие и тестовые наборы.
Обучение ClassificationKNN модели с использованием T1 и T2 данные.
C1 = fitcknn(T1(idxTrain,:),'Model_Year'); C2 = fitcknn(T2(idxTrain,:),'Model_Year');
C1 и C2 обучены ClassificationKNN модели.
Проверьте, имеют ли две модели одинаковую предиктивную точность в тестовом наборе.
h = compareHoldout(C1,C2,T1(idxTest,:),T2(idxTest,:),'Model_Year')h = logical
0
h = 0 указывает на то, что не отвергать нулевую гипотезу о том, что две модели имеют одинаковую прогностическую точность.
Обучение двух классификационных моделей с использованием различных алгоритмов. Выполните статистический тест, сравнивая коэффициенты неправильной классификации двух моделей на тестовом наборе.
Загрузить ionosphere набор данных.
load ionosphereСоздайте раздел, равномерно разделяющий данные на обучающие и тестовые наборы.
rng(1) % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP является объектом раздела перекрестной проверки, определяющим обучающие и тестовые наборы.
Обучение модели SVM и ансамбля из 100 фасованных классификационных деревьев. Для модели SVM укажите использование ядра радиальной базовой функции и эвристической процедуры для определения масштаба ядра.
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true, ... 'KernelFunction','RBF','KernelScale','auto'); t = templateTree('Reproducible',true); % For reproducibility of random predictor selections C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','Bag', ... 'Learners',t);
C1 является обученным ClassificationSVM модель. C2 является обученным ClassificationBaggedEnsemble модель.
Проверьте, имеют ли две модели одинаковую прогностическую точность. Используйте одни и те же данные предиктора набора тестов для каждой модели.
h = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest))
h = logical
0
h = 0 указывает на то, что не отвергать нулевую гипотезу о том, что две модели имеют одинаковую прогностическую точность.
Обучите две модели классификации, используя один и тот же алгоритм, но настройте гиперпараметр, чтобы сделать алгоритм более сложным. Провести статистический тест для оценки того, имеет ли более простая модель лучшую точность в тестовых данных, чем более сложная модель.
Загрузить ionosphere набор данных.
load ionosphere;Создайте раздел, равномерно разделяющий данные на обучающие и тестовые наборы.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP является объектом раздела перекрестной проверки, определяющим обучающие и тестовые наборы.
Обучайте две модели SVM: одну, использующую линейное ядро (по умолчанию для двоичной классификации), и одну, использующую ядро радиальной базовой функции. Используйте масштаб ядра по умолчанию 1.
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true); C2 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true,... 'KernelFunction','RBF');
C1 и C2 обучены ClassificationSVM модели.
Проверьте нулевую гипотезу о том, что более простая модель (C1) максимально точна, чем более сложная модель (C2). Поскольку размер тестового набора велик, проведите асимптотический тест McNemar и сравните результаты с тестом среднего p-значения (по умолчанию тестирование без учета затрат). Запрос на возврат значений p и коэффициентов неправильной классификации.
Asymp = zeros(4,1); % Preallocation MidP = zeros(4,1); [Asymp(1),Asymp(2),Asymp(3),Asymp(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater',... 'Test','asymptotic'); [MidP(1),MidP(2),MidP(3),MidP(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater'); table(Asymp,MidP,'RowNames',{'h' 'p' 'e1' 'e2'})
ans=4×2 table
Asymp MidP
__________ __________
h 1 1
p 7.2801e-09 2.7649e-10
e1 0.13714 0.13714
e2 0.33143 0.33143
P-значение близко к нулю для обоих тестов, предоставляя убедительные доказательства для отклонения нулевой гипотезы, что более простая модель менее точна, чем более сложная модель. Независимо от того, какой тест вы указываете, compareHoldout возвращает один и тот же тип меры неправильной классификации для обеих моделей.
Для наборов данных с несбалансированными представлениями классов или для наборов данных с несбалансированными ложноположительными и ложноотрицательными затратами можно статистически сравнить прогностическую производительность двух классификационных моделей, включив в анализ матрицу затрат.
Загрузить arrhythmia набор данных. Определите представления классов в данных.
load arrhythmia;
Y = categorical(Y);
tabulate(Y); Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
Существует 16 классов, однако некоторые из них не представлены в наборе данных (например, класс 13). Большинство наблюдений классифицируются как не имеющие аритмии (класс 1). Набор данных является сильно дискретным с несбалансированными классами.
Объединить все наблюдения с аритмией (классы 2-15) в один класс. Удалите эти наблюдения с неизвестным статусом аритмии (класс 16) из набора данных.
idx = (Y ~= '16'); Y = Y(idx); X = X(idx,:); Y(Y ~= '1') = 'WithArrhythmia'; Y(Y == '1') = 'NoArrhythmia'; Y = removecats(Y);
Создайте раздел, равномерно разделяющий данные на обучающие и тестовые наборы.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP является объектом раздела перекрестной проверки, определяющим обучающие и тестовые наборы.
Создайте матрицу затрат таким образом, что неправильная классификация пациента с аритмией в класс «без аритмии» в пять раз хуже, чем неправильная классификация пациента без аритмии в класс аритмии. Правильная классификация не влечет за собой никаких затрат. Строки указывают истинный класс, а столбцы - прогнозируемый класс. При выполнении анализа с учетом затрат рекомендуется указать порядок классов.
cost = [0 1;5 0];
ClassNames = {'NoArrhythmia','WithArrhythmia'};Обучите два повышающих ансамбля из 50 деревьев классификации, один из которых использует AdaBoostM1, а другой - LogitBoost. Поскольку набор данных содержит отсутствующие значения, укажите использование суррогатных разделений. Обучение моделей с использованием матрицы затрат.
t = templateTree('Surrogate','on'); numTrees = 50; C1 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames); C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','LogitBoost', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames);
C1 и C2 обучены ClassificationEnsemble модели.
Проверить наличие AdaBoostM1 ансамбля (C1и ансамбль LogitBoost (C2) имеют равную точность прогнозирования. Предоставьте матрицу затрат. Проведите асимптотический тест, тест отношения правдоподобия и тест с учетом затрат (по умолчанию при прохождении матрицы затрат). Запрос на возврат p-значений и затрат на неправильную классификацию.
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest),... 'Cost',cost)
h = logical
0
p = 0.3334
e1 = 0.5581
e2 = 0.4698
h = 0 указывает на то, что не отвергать нулевую гипотезу о том, что две модели имеют одинаковую прогностическую точность.
Уменьшите сложность классификационной модели, выбрав подмножество переменных предиктора (функций) из большего набора. Затем статистически сравните точность выборки между двумя моделями.
Загрузить ionosphere набор данных.
load ionosphere;Создайте раздел, равномерно разделяющий данные на обучающие и тестовые наборы.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP является объектом раздела перекрестной проверки, определяющим обучающие и тестовые наборы.
Обучение ансамбля из 100 усиленных деревьев классификации с использованием AdaBoostM1 и всего набора предикторов. Проверьте показатель важности для каждого предиктора.
t = templateTree('MaxNumSplits',1); % Weak-learner template tree object C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t); predImp = predictorImportance(C2); figure; bar(predImp); h = gca; h.XTick = 1:2:h.XLim(2)
h =
Axes with properties:
XLim: [-0.2000 35.2000]
YLim: [0 0.0090]
XScale: 'linear'
YScale: 'linear'
GridLineStyle: '-'
Position: [0.1300 0.1100 0.7750 0.8150]
Units: 'normalized'
Show all properties
title('Predictor Importance'); xlabel('Predictor'); ylabel('Importance measure');

Определите пять основных предикторов с точки зрения их важности.
[~,idxSort] = sort(predImp,'descend');
idx5 = idxSort(1:5);Обучите еще один ансамбль из 100 повышенных деревьев классификации, используя AdaBoostM1 и пять предикторов с наибольшей важностью.
C1 = fitcensemble(X(idxTrain,idx5),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t);
Проверьте, имеют ли две модели одинаковую прогностическую точность. Укажите уменьшенные данные предиктора набора тестов для C1 и данные предиктора полного набора тестов для C2.
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,idx5),X(idxTest,:),Y(idxTest))
h = logical
0
p = 0.7744
e1 = 0.0914
e2 = 0.0857
h = 0 указывает на то, что не отвергать нулевую гипотезу о том, что две модели имеют одинаковую прогностическую точность. Этот результат благоприятствует более простому ансамблю, C1.
compareHoldout не сравнивает модели ECOC, состоящие из линейных или классификационных моделей ядра (то есть ClassificationLinear или ClassificationKernel объекты модели). Выдерживать сравнение ClassificationECOC модели, состоящие из линейных или классификационных моделей ядра, использование testcholdout вместо этого.
Аналогично, compareHoldout не сравнивает ClassificationLinear или ClassificationKernel объекты модели. Чтобы сравнить эти модели, используйте testcholdout вместо этого.
Тесты Макнемара - это тесты гипотез, которые сравнивают две пропорции популяции, решая при этом проблемы, возникающие в результате двух зависимых, согласованных пар выборок.
Одним из способов сравнения прогностической точности двух классификационных моделей является:
Разбейте данные на обучающие и тестовые наборы.
Обучение обеих моделей классификации с использованием обучающего набора.
Спрогнозировать метки классов с помощью тестового набора.
Сведите результаты в таблицу «два на два», аналогичную этой диаграмме.
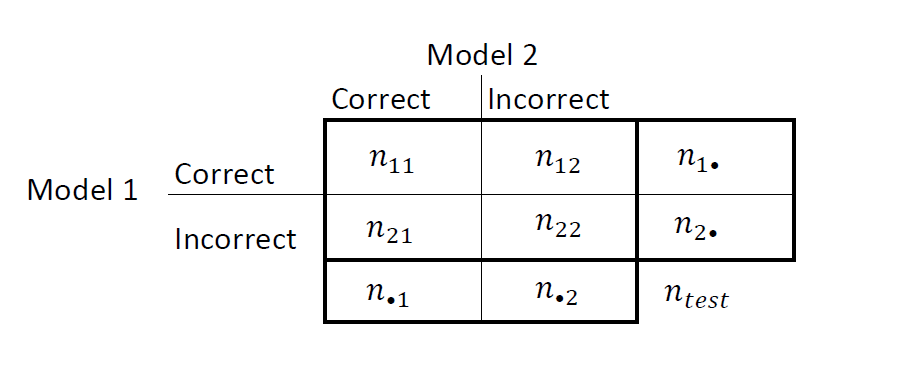
nii - количество совпадающих пар, то есть количество наблюдений, которые обе модели классифицируют одинаково (правильно или неправильно). nij, i ≠ j, - количество дискордантных пар, то есть количество наблюдений, которые модели классифицируют по-разному (правильно или неправильно).
Коэффициенты неправильной классификации для Моделей 1 и 2 составляют n2 •/2 = n • 2/n соответственно. Двусторонний тест для сравнения точности двух моделей
Нулевая гипотеза предполагает, что популяция проявляет маргинальную однородность, что сводит нулевую гипотезу к security21. Также при нулевой гипотезе N12 ~ Биномиал (n12 + n21,0,5) [1].
Эти факты являются основой для доступных вариантов теста Макнемара: асимптотических, точно-условных и среднезначных тестов Макнемара. Следующие определения суммируют доступные варианты.
Асимптотическая - асимптотическая статистика теста МакНемара и области отклонения (для уровня значимости α):
Для односторонних тестов статистика теста равна
Если < α, где Startявляется стандартным гауссовым cdf, то отклонить H0.
Для двусторонних тестов статистика теста равна
Если ) < α, (x; m) - cdf, вычисленный при x, то отклонить H0.
Асимптотический тест требует теории больших выборок, в частности, гауссова аппроксимации к биномиальному распределению.
Общее число несогласованных пар, n21, должно быть больше 10 ([1], Ch. 10,1,4).
В целом асимптотические тесты не гарантируют номинального покрытия. Наблюдаемая вероятность ложного отклонения нулевой гипотезы может превышать α, как предложено в имитационных исследованиях в [18]. Однако асимптотический тест Макнемара хорошо работает с точки зрения статистической мощности.
Точная - условная - точная условная статистика теста Макнемара и области отклонения (для уровня значимости α) являются ([36], [38]):
Для односторонних тестов статистика теста равна
Если < α, n, p) является биномиальным cdf с размером выборки n и вероятностью успеха p, оцененной при x, то отклонить H0.
Для двусторонних тестов статистика теста равна
).
Если α/2, то отклоните H0.
Точный условный тест всегда достигает номинального покрытия. Исследования моделирования в [18] показывают, что тест является консервативным, а затем показывают, что тест не обладает статистической мощностью по сравнению с другими вариантами. Для небольших или очень дискретных испытательных образцов рекомендуется использовать испытание среднего значения p ([1], гл. 3.6.3).
Тест среднего p-значения - статистика теста среднего p-значения McNemar и области отклонения (для уровня значимости α) являются ([32]):
Для односторонних тестов статистика теста равна
Если t1∗;n12+n21,0.5) < α, (x; nfBin (x; n, p) являются биномиальными cdf и pdf соответственно с размером выборки n и вероятностью успеха p, оцененной при x, то отклонить H0.
Для двусторонних тестов статистика теста равна
).
Если < α/2, то отбраковать H0.
Тест среднего p-значения обращается к чрезмерно консервативному поведению теста точного условия. Исследования моделирования в [18] показывают, что этот тест достигает номинального охвата и обладает хорошей статистической мощностью.
Одним из способов выбора функций без учета затрат является:
Обучить первую классификационную модель (C1) с использованием полного набора предикторов.
Обучить вторую классификационную модель (C2) с использованием уменьшенного набора предикторов.
Определить X1 в качестве данных предиктора полного набора тестов и X2 в качестве уменьшенных данных предиктора набора тестов.
Войти compareHoldout(C1,C2,X1,X2,Y,'Alternative','less'). Если compareHoldout прибыль 1, то есть достаточно доказательств, чтобы предположить, что модель классификации, в которой используется меньше предикторов, работает лучше, чем модель, в которой используется полный набор предикторов.
В качестве альтернативы можно оценить, существует ли существенная разница между точностью двух моделей. Чтобы выполнить эту оценку, удалите 'Alternative','less' спецификация на шаге 4. compareHoldout проводит двусторонний тест, и h = 0 указывает на то, что недостаточно доказательств, чтобы предположить разницу в точности двух моделей.
Чувствительные к затратам тесты выполняют численную оптимизацию, что требует дополнительных вычислительных ресурсов. Тест отношения правдоподобия проводит численную оптимизацию косвенно путем нахождения корня множителя Лагранжа в интервале. Для некоторых наборов данных, если корень лежит близко к границам интервала, то метод может завершиться ошибкой. Поэтому, если у вас есть лицензия Optimization Toolbox, рассмотрите возможность проведения теста хи-квадрат с учетом затрат. Дополнительные сведения см. в разделе CostTest и тестирование с учетом затрат.
Чтобы непосредственно сравнить точность двух наборов меток класса при прогнозировании набора истинных меток класса, используйте testcholdout.
[1] Agresti, A. Категориальный анализ данных, 2-й ред. Джон Уайли и сыновья, Inc.: Хобокен, Нью-Джерси, 2002.
[2] Фагерлан, М.В., С. Лидерсен и П. Лааке. «Тест McNemar для двоичных согласованных пар данных: Mid-p и асимптотические лучше, чем точные условные». Методология медицинских исследований BMC. Том 13, 2013, стр. 1-8.
[3] Ланкастер, H.O. «Тесты значимости в дискретных распределениях». JASA, том 56, номер 294, 1961, стр. 223-234.
[4] McNemar, Q. «Примечание об ошибке выборки разницы между коррелированными пропорциями или процентами». Психометрика, т. 12, № 2, 1947, с. 153-157.
[5] Мостеллер, Ф. «Некоторые статистические проблемы в измерении субъективной реакции на наркотики». Биометрия, т. 8, № 3, 1952, с. 220-226.
