Обнаружение наличия речи в аудиосигнале
Audio измерения

Блок Voice Activity Detector обнаруживает наличие речи в аудиосигнале. Можно также использовать блок Voice Activity Detector, чтобы вывести оценку отклонения шума на интервал частоты.
Типы данных |
|
Прямое сквозное соединение |
|
Многомерные сигналы |
|
Сигналы переменного размера |
|
Обнаружение пересечения нулем |
|
Этот Voice Activity Detector реализует алгоритм, описанный в [1].
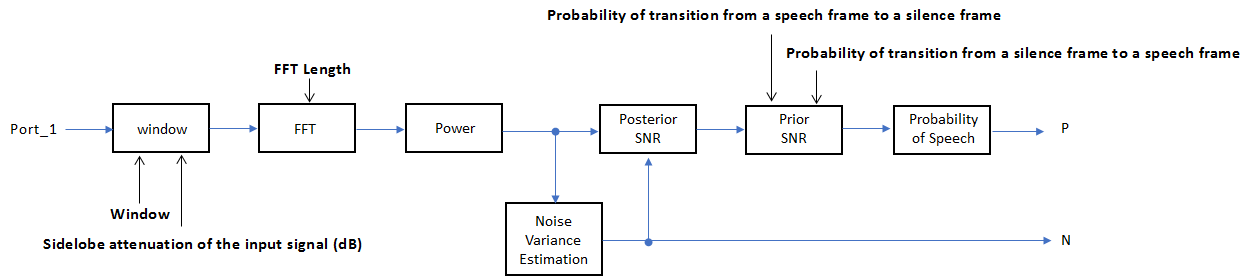
Если Domain of the input задано как Timeвходной сигнал окончается и затем преобразуется в частотный диапазон согласно параметрам Window, Sidelobe attenuation of the window (dB) и FFT length. Если Domain of the input задано как Frequency, вход принят как оконное дискретное время Фурье (DTFT) аудиосигнала. Затем сигнал преобразуется в область степени. Отклонение шума оценивается согласно [2]. Апостериорный и предшествующий ОСШ оцениваются согласно формуле минимальной среднеквадратичной ошибки (MMSE), описанной в [3]. В соответствии с [1] используется тест коэффициента журнала правдоподобия на основе скрытой модели Маркова (HMM).
[1] Сон, Джонсео., Нам Су Ким и Вонён Сон. «Обнаружение голосовой активности на основе статистической модели». Обработка сигналов Букв IEEE. Том 6, № 1, 1999.
[2] Мартин, Р. «Оценка шумовой Степени спектральной плотности на основе оптимального сглаживания и минимальной статистики». Транзакции IEEE по обработке речи и аудио. Том 9, № 5, 2001, стр. 504-512.
[3] Ефрем, Я. и Д. Малах. «Улучшение речи с использованием оценки минимальной среднеквадратичной ошибки короткого времени спектральной амплитуды». Транзакции IEEE по акустике, речи и обработке сигналов. Том 32, № 6, 1984, стр. 1109-1121.




