Обнаружение наличия речи в аудиосигнале
The voiceActivityDetector Системная object™ определяет наличие речи в аудиосегменте. Можно также использовать voiceActivityDetector Системный объект для вывода оценки отклонения шума на частотный интервал.
Чтобы обнаружить наличие речи:
Создайте voiceActivityDetector Объекту и установите его свойства.
Вызывайте объект с аргументами, как будто это функция.
Дополнительные сведения о работе системных объектов см. в разделе «Что такое системные объекты?».
VAD = voiceActivityDetector создает Системный объект, VAD, который обнаруживает присутствие речи независимо по каждому входному каналу.
VAD = voiceActivityDetector( устанавливает каждое свойство Name,Value)Name к заданной Value. Неопределенные свойства имеют значения по умолчанию.
VAD = voiceActivityDetector('InputDomain','Frequency') создает Системный объект, VAD, который принимает вход частотного диапазона.[ применяет на входе детектор голосовой активности, probability,noiseEstimate]
= VAD(audioIn)audioIn, и возвращает вероятность того, что речь присутствует. Это также возвращает предполагаемое отклонение шума на интервал частоты.
Чтобы использовать функцию объекта, задайте системный объект в качестве первого входного параметра. Например, чтобы освободить системные ресурсы системного объекта с именем obj, используйте следующий синтаксис:
release(obj)
Используйте voiceActivityDetector по умолчанию Система object™, чтобы обнаружить наличие речи в передаче потокового аудио сигнале.
Создайте считыватель аудио файла для потоковой передачи аудио файла для обработки. Задайте параметры, чтобы фрагмент аудиосигнал в неперекрывающиеся системы координат на 10 мс.
fileReader = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = fileReader.SampleRate;
fileReader.SamplesPerFrame = ceil(10e-3*fs);
Создайте voiceActivityDetector по умолчанию Системный объект для обнаружения присутствия речи в аудио файла.
VAD = voiceActivityDetector;
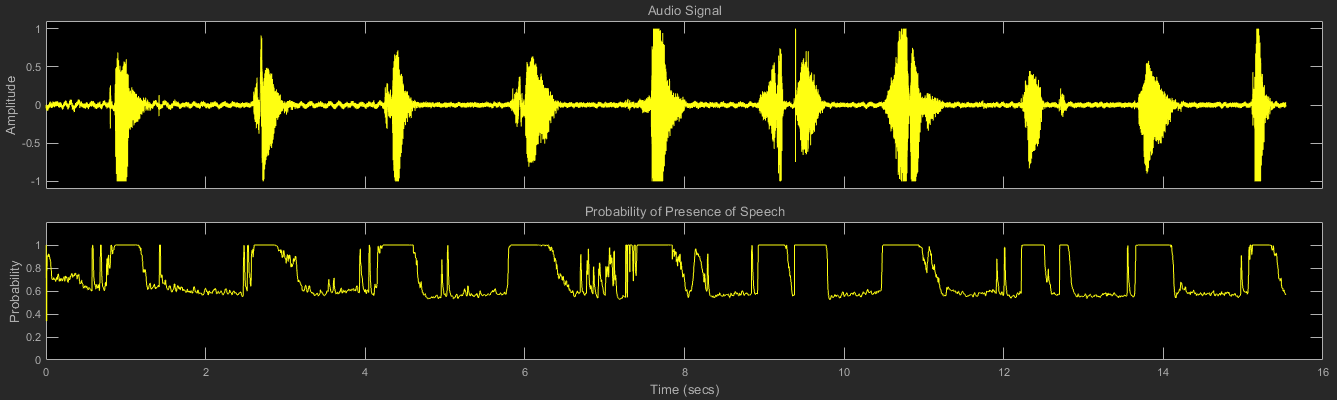
Создайте возможности, чтобы построить график аудиосигнала и соответствующей вероятности присутствия речи, обнаруженной детектором голосовой активности. Создайте аудио устройство средства записи для воспроизведения звука через звуковую карту.
scope = timescope( ... 'NumInputPorts',2, ... 'SampleRate',fs, ... 'TimeSpanSource','Property','TimeSpan',3, ... 'BufferLength',3*fs, ... 'YLimits',[-1.5 1.5], ... 'TimeSpanOverrunAction','Scroll', ... 'ShowLegend',true, ... 'ChannelNames',{'Audio','Probability of speech presence'}); deviceWriter = audioDeviceWriter('SampleRate',fs);
В цикле аудиопотока:
Считывайте с аудио файла.
Вычислим вероятность присутствия речи.
Визуализируйте вероятность наличия аудиосигнала и речи.
Воспроизведите аудиосигнал через звуковую карту.
while ~isDone(fileReader) audioIn = fileReader(); probability = VAD(audioIn); scope(audioIn,probability*ones(fileReader.SamplesPerFrame,1)) deviceWriter(audioIn); end

Используйте детектор голосовой активности, чтобы обнаружить присутствие речи в аудиосигнале. Постройте график вероятности присутствия речи вместе с аудио выборок.
Создайте dsp.AudioFileReader Система object™, чтобы считать речевой файл.
afr = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = afr.SampleRate;
Фрагмент аудио в системы координат 20 мс с 75% перекрываются между последовательными системами координат. Преобразуйте время системы координат в секундах в выборки. Определите размер скачка (шаг новых выборок). В считывателе аудио файла установите размер выборок на систему координат. Создайте dsp.AsyncBuffer по умолчанию объект для управления перекрытием между аудио систем координат.
frameSize = ceil(20e-3*fs);
overlapSize = ceil(0.75*frameSize);
hopSize = frameSize - overlapSize;
afr.SamplesPerFrame = hopSize;
inputBuffer = dsp.AsyncBuffer('Capacity',frameSize);
Создайте voiceActivityDetector Системный объект. Задайте длину БПФ 1024.
VAD = voiceActivityDetector('FFTLength',1024);
Создайте возможности, чтобы построить график аудиосигнала и соответствующей вероятности присутствия речи, обнаруженной детектором голосовой активности. Создайте audioDeviceWriter Системный объект для воспроизведения звука через звуковую карту.
scope = timescope('NumInputPorts',2, ... 'SampleRate',fs, ... 'TimeSpanSource','Property','TimeSpan',3, ... 'BufferLength',3*fs, ... 'YLimits',[-1.5,1.5], ... 'TimeSpanOverrunAction','Scroll', ... 'ShowLegend',true, ... 'ChannelNames',{'Audio','Probability of speech presence'}); player = audioDeviceWriter('SampleRate',fs);
Инициализируйте вектор, чтобы сохранить значения вероятностей.
pHold = ones(hopSize,1);
В цикле аудиопотока:
Считайте выборки хопа из аудио файла и сохраните выборки в буфер.
Считайте систему координат из буфера с заданным перекрытием из предыдущей системы координат.
Вызовите детектор голосовой активности, чтобы получить вероятность речи для анализируемой системы координат.
Установите последний элемент вектора вероятностей в новое решение вероятности. Визуализируйте вероятность аудио- и речевого присутствия с помощью временных возможностей.
Воспроизведение аудио через звуковую карту.
Установите вектор вероятности на самый последний результат для графического изображения в следующем цикле.
while ~isDone(afr) x = afr(); n = write(inputBuffer,x); overlappedInput = read(inputBuffer,frameSize,overlapSize); p = VAD(overlappedInput); pHold(end) = p; scope(x,pHold) player(x); pHold(:) = p; end

Отпустите player как только звук закончит воспроизведение.
release(player)
Многие редукции данных техники работают на частотном диапазоне. Преобразование аудиосигнала в частотный диапазон только один раз эффективно. В этом примере вы преобразовываете сигнал передачи потокового аудио в частотный диапазон и подаете этот сигнал в детектор голосовой активности. Если речь присутствует, функции mel-частотных кепстральных коэффициентов (MFCC) извлекаются из сигнала частотного диапазона с помощью cepstralFeatureExtractor System object™.
Создайте dsp.AudioFileReader Системный объект для чтения с аудио файла.
fileReader = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = fileReader.SampleRate;Обработайте аудио в системах координат 30 мс с хопом 10 мс. Создайте dsp.AsyncBuffer по умолчанию объект для управления перекрытием между аудио систем координат.
samplesPerFrame = ceil(0.03*fs); samplesPerHop = ceil(0.01*fs); samplesPerOverlap = samplesPerFrame - samplesPerHop; fileReader.SamplesPerFrame = samplesPerHop; buffer = dsp.AsyncBuffer;
Создайте voiceActivityDetector Системный объект и cepstralFeatureExtractor Системный объект. Укажите, что они работают в частотный диапазон. Создайте dsp.SignalSink для регистрации извлеченных функций cepstral.
VAD = voiceActivityDetector('InputDomain','Frequency'); cepFeatures = cepstralFeatureExtractor('InputDomain','Frequency','SampleRate',fs,'LogEnergy','Replace'); sink = dsp.SignalSink;
В цикле аудиопотока:
Считайте один скачок отсчетов из аудио файла и сохраните отсчеты в буфер.
Считайте систему координат из buffer с заданным перекрытием из предыдущей системы координат.
Вызовите детектор голосовой активности, чтобы получить вероятность речи для анализируемой системы координат.
Если анализируемая система координат имеет вероятность речи больше 0,75, извлеките кепстральные функции и логгируйте функции, используя приемник сигнала. Если анализируемая система координат имеет вероятность речи менее 0,75, запишите вектор NaNs в приемник.
threshold = 0.75; nanVector = nan(1,13); while ~isDone(fileReader) audioIn = fileReader(); write(buffer,audioIn); overlappedAudio = read(buffer,samplesPerFrame,samplesPerOverlap); X = fft(overlappedAudio,2048); probabilityOfSpeech = VAD(X); if probabilityOfSpeech > threshold xFeatures = cepFeatures(X); sink(xFeatures') else sink(nanVector) end end
Визуализируйте коэффициенты cepstral с течением времени.
timeVector = linspace(0,15,size(sink.Buffer,1)); plot(timeVector,sink.Buffer) xlabel('Time (s)') ylabel('MFCC Amplitude') legend('Log-Energy','c1','c2','c3','c4','c5','c6','c7','c8','c9','c10','c11','c12')

Создайте dsp.AudioFileReader объект для чтения в аудиокадре за кадром.
fileReader = dsp.AudioFileReader('singing-a-major.ogg');Создайте voiceActivityDetector объект для обнаружения присутствия голоса в передаче потокового аудио.
VAD = voiceActivityDetector;
Пока существуют непрочитанные выборки, считайте из файла и определите вероятность того, что система координат содержит голосовую активность. Если система координат содержит голосовую активность, вызовите pitch для оценки основной частоты аудио системы координат. Если система координат не содержит голосовой активности, объявите основную частоту следующим NaN.
f0 = []; while ~isDone(fileReader) x = fileReader(); if VAD(x) > 0.99 decision = pitch(x,fileReader.SampleRate, ... "WindowLength",size(x,1), ... "OverlapLength",0, ... "Range",[200,340]); else decision = NaN; end f0 = [f0;decision]; end
Постройте график обнаруженного контура тангажа с течением времени.
t = linspace(0,(length(f0)*fileReader.SamplesPerFrame)/fileReader.SampleRate,length(f0)); plot(t,f0) ylabel('Fundamental Frequency (Hz)') xlabel('Time (s)') grid on

The voiceActivityDetector реализует алгоритм, описанный в [1].
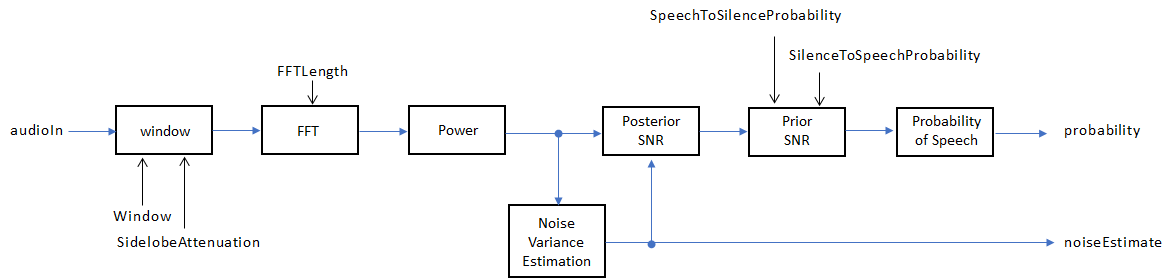
Если InputDomain задается как 'Time'входной сигнал окончается и затем преобразуется в частотный диапазон согласно Window, SidelobeAttenuation, и FFTLength свойства. Если InputDomain задан как частота, вход принят в виде оконного дискретного времени Фурье (DTFT) аудиосигнала. Затем сигнал преобразуется в область степени. Отклонение шума оценивается согласно [2]. Апостериорный и предшествующий ОСШ оцениваются согласно формуле минимальной среднеквадратичной ошибки (MMSE), описанной в [3]. Тест журнала коэффициента правдоподобия и основанная на скрытой модели Маркова (HMM) схема зависания определяют вероятность того, что текущая система координат содержит речь, согласно [1].
[1] Сон, Джонсео., Нам Су Ким и Вонён Сон. «Обнаружение голосовой активности на основе статистической модели». Обработка сигналов Букв IEEE. Том 6, № 1, 1999.
[2] Мартин, Р. «Оценка шумовой Степени спектральной плотности на основе оптимального сглаживания и минимальной статистики». Транзакции IEEE по обработке речи и аудио. Том 9, № 5, 2001, стр. 504-512.
[3] Ефрем, Я. и Д. Малах. «Улучшение речи с использованием оценки минимальной среднеквадратичной ошибки короткого времени спектральной амплитуды». Транзакции IEEE по акустике, речи и обработке сигналов. Том 32, № 6, 1984, стр. 1109-1121.
audioFeatureExtractor | cepstralFeatureExtractor | mfcc | pitch | Voice Activity Detector
