Обучение с подкреплением является направленным на достижение цели вычислительным подходом, в котором компьютер учится выполнять задачу путем взаимодействия с неизвестным динамическим окружением. Этот подход к обучению позволяет компьютеру принять ряд решений, чтобы максимизировать совокупное вознаграждение для задачи без человеческого вмешательства и без явного программирования для достижения задачи. Следующая схема показывает общее представление сценария обучения с подкреплением.
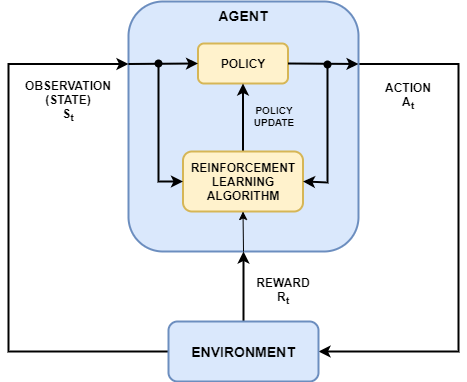
Цель обучения с подкреплением состоит в том, чтобы обучить политику агента выполнять задачу в неизвестном окружении. Агент получает наблюдения и вознаграждение от окружения и отправляет действия в окружение. Вознаграждение является мерой того, насколько успешно действие относительно выполнения цели задачи.
Чтобы создать и обучить агентов обучения с подкреплением, можно использовать пакет Reinforcement Learning Toolbox™. Обычно политики агента реализуются с помощью глубоких нейронных сетей, которые можно создать с помощью программного обеспечения Deep Learning Toolbox™.
Обучение с подкреплением полезно для многих приложений управления и планирования. Следующие примеры показывают, как обучить агентов обучения с подкреплением для робототехники и задач беспилотного вождения.
Общий рабочий процесс обучения агента, используя обучение с подкреплением, включает следующие шаги.
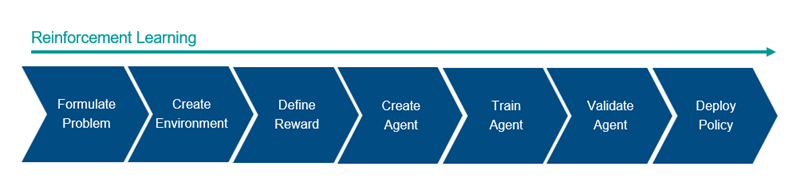
Сформулируйте задачу - Задайте задачу для обучения агента, включая то, как агент взаимодействует с окружением и любыми первичными и вторичными целями, которых должен достичь агент.
Создайте окружение - Определяют окружение, в котором агент работает, включая интерфейс между агентом и окружением и окружением динамическая модель.
Задайте вознаграждение - Задайте сигнал вознаграждения, который агент использует для измерения своей эффективности относительно целей задачи и как вычислить этот сигнал от окружения.
Создайте агента - Создайте агента, который включает в себя определение представления политики и настройку алгоритма обучения агента.
Обучите агента - Обучите представление политики агента с помощью заданного окружения, вознаграждения и алгоритма обучения агента.
Валидация агента - оценка производительности обученного агента путем совместной симуляции агента и окружения.
Развертывание политики - развертывание обученного представления политики с помощью, например, сгенерированного кода GPU.
Обучение агента с помощью обучения с подкреплением является итеративным процессом. Решения и результаты на более поздних этапах могут потребовать от вас вернуться к более раннему этапу рабочего процесса обучения. Например, если процесс обучения не сходится к оптимальной политике за разумное время, вам, вероятно, перед переобучением агента придется обновить любое из следующих:
Настройки обучения
Строение алгоритма обучения
Представление политики
Определение сигнала вознаграждения
Сигналы действия и наблюдения
Динамика окружения
В сценарии обучения с подкреплением, где вы обучаете агента для выполнения задачи, окружение моделирует динамику, с которой взаимодействует агент. Далее окружение:
Получает действия от агента.
Формирует выходные наблюдения в ответ на действия.
Генерирует вознаграждение, измеряющее, насколько хорошо действие способствует достижению задачи.
Создание модели окружения включает в себя определение следующего:
Сигналы действия и наблюдения, которые агент использует для взаимодействия со окружением.
Сигнал вознаграждения, который агент использует для измерения своего успеха. Для получения дополнительной информации смотрите Задать сигналы вознаграждения (Reinforcement Learning Toolbox).
Динамическое поведение окружения.
Вы можете создать окружение в любом из MATLAB® или Simulink®. Для получения дополнительной информации смотрите Создать окружения обучения с подкреплением MATLAB (Reinforcement Learning Toolbox) и Создать окружения обучения с подкреплением Simulink (Reinforcement Learning Toolbox).
Агент обучения с подкреплением содержит два компонента: политику и алгоритм обучения.
Политика является отображением, которое выбирает действия на основе наблюдений от окружения. Обычно политика является функциональной аппроксимацией с настраиваемыми параметрами, такими как глубокая нейронная сеть.
Алгоритм обучения постоянно обновляет параметры политики на основе действий, наблюдений и вознаграждения. Цель алгоритма обучения состоит в том, чтобы найти оптимальную политику, которая максимизирует совокупное вознаграждение, полученное во время задачи.
Агенты отличаются алгоритмами обучения и представлениями политики. Агенты могут работать в дискретных пространствах действий, непрерывных пространствах действий или обоих. В дискретном пространстве действий агент выбирает действия из конечного множества возможных действий. В непрерывном пространстве действий агент выбирает действие из непрерывной области значений возможных значений действия. Программное обеспечение Reinforcement Learning Toolbox поддерживает агентов следующих типов.
| Агент | Пространство действий |
|---|---|
| Агенты Q-обучения (Reinforcement Learning Toolbox) | Дискретный |
| Агенты глубоких Q-сетей (Reinforcement Learning Toolbox) | Дискретный |
| Агенты SARSA (Reinforcement Learning Toolbox) | Дискретный |
| Агенты градиента политики ( Reinforcement Learning Toolbox) | Дискретный или непрерывный |
| Агенты актёра-критика (Reinforcement Learning Toolbox) | Дискретный или непрерывный |
| Проксимальные агенты оптимизации политики (Reinforcement Learning Toolbox) | Дискретный или непрерывный |
| Агенты градиента глубокой детерминированной политики (Reinforcement Learning Toolbox) | Непрерывный |
| Двухдневные глубокие детерминированные агенты градиента политики (Reinforcement Learning Toolbox) | Непрерывный |
| Агенты мягкого актёра-критика (Reinforcement Learning Toolbox) | Непрерывный |
Для получения дополнительной информации см. Раздел «Агенты обучения с подкреплением» (Reinforcement Learning Toolbox).
В зависимости от типа агента, которого вы используете, его политика и алгоритм обучения требуют одного или нескольких представлений политики и функции ценности, которые можно реализовать с помощью глубоких нейронных сетей.
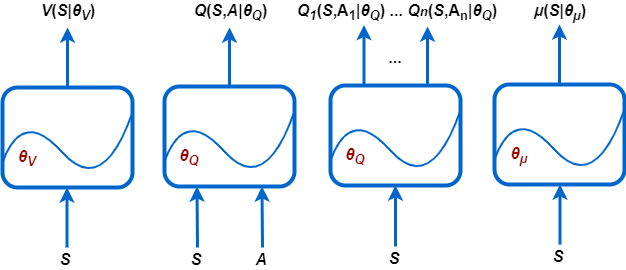
Reinforcement Learning Toolbox поддерживает следующие типы представлений функции ценности и политики.
V (S | θV) - критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение (функцию ценности) на основе заданной S наблюдения.
Q (S, A | θQ) - критики, которые оценивают функцию значения для заданного дискретного A действий и заданного S наблюдений.
Qi (S, Ai | θQ) - критики с несколькими выходами, которые оценивают функцию значения для всех возможных дискретных действий Ai и заданную S наблюдения.
μ (S | θμ) - актёры, которые выбирают действие на основе заданного наблюдения S. Актёры могут выбирать действия с помощью детерминированных или стохастических методов.
Во время обучения агент обновляет параметры этих представлений (θV, θQ и θμ).
Можно создать большинство агентов Reinforcement Learning Toolbox с представлениями политики и функции ценности по умолчанию. Агенты определяют вход и выходные слои этих глубоких нейронных сетей на основе действия и спецификаций наблюдений от окружения.
Также можно создать представления актёра и критика для вашего агента с помощью функциональности Deep Learning Toolbox, такой как приложение Deep Network Designer. В этом случае убедитесь, что входные и выходные размерности представлений актёра и критика совпадают с соответствующими спецификациями действий и наблюдений окружения. Пример, который создает представление критика с помощью Deep Network Designer, см. в разделе Создание агента с использованием Deep Network Designer и Train с использованием наблюдений изображений.
Глубокие нейронные сети состоят из ряда взаимосвязанных слоев. Полный список доступных слоев см. в Списке слоев глубокого обучения.
Все агенты, кроме агентов Q-обучения и SARSA, поддерживают рекуррентные нейронные сети (RNN). Эти сети имеют вход sequenceInputLayer и, по меньшей мере, один слой, который имеет скрытую информацию о состоянии, например, lstmLayer. Эти сети могут быть особенно полезны, когда окружение имеет состояния, которые не находятся в векторе наблюдения.
Дополнительные сведения о создании агентов и связанных с ними функциях ценности и представлениях политики см. на соответствующих страницах агента в предыдущей таблице.
Программное обеспечение Reinforcement Learning Toolbox предоставляет дополнительные слои, которые можно использовать при создании представлений глубоких нейронных сетей.
| Слой | Описание |
|---|---|
scalingLayer(Набор Reinforcement Learning Toolbox) | Применяет линейную шкалу и смещение к массиву входа. Этот слой полезен для масштабирования и перемены выходов нелинейных слоев, таких как tanhLayer и sigmoidLayer. |
quadraticLayer(Набор Reinforcement Learning Toolbox) | Создает вектор квадратичных мономов, созданных из элементов входного массива. Этот слой полезен, когда вам нужен вывод, который является некоторой квадратичной функцией его входов, например, для LQR- контроллера. |
softplusLayer(Набор Reinforcement Learning Toolbox) | Реализует активацию softplus Y = журнал (1 + eX), что гарантирует, что выход всегда положительный. Это сглаженная версия выпрямленного линейного модуля (ReLU). |
Дополнительные сведения о создании представлений политики и функции ценности см. в разделах Создание представлений политики и функции ценности (Reinforcement Learning Toolbox).
Можно также импортировать предварительно обученные глубокие нейронные сети или архитектуры слоя глубокой нейронной сети с помощью функциональности импорта сети Deep Learning Toolbox. Для получения дополнительной информации смотрите Import Policy и Представления функции ценности (Reinforcement Learning Toolbox).
Как только вы создаете окружение и агента обучения с подкреплением, можно обучить агента в окружении, используя train (Reinforcement Learning Toolbox) функция. Чтобы сконфигурировать свое обучение, используйте rlTrainingOptions (Reinforcement Learning Toolbox) объект. Для получения дополнительной информации смотрите Обучите агентов обучения с подкреплением (Reinforcement Learning Toolbox)
Если у вас есть программное обеспечение Parallel Computing Toolbox™, можно ускорить обучение и симуляцию с помощью многоядерных процессоров или графических процессоров. Для получения дополнительной информации смотрите Обучите агентов, использующих параллельные вычисления и графические процессоры (Reinforcement Learning Toolbox).
Как только вы обучаете агента обучения с подкреплением, можно сгенерировать код, чтобы развернуть оптимальную политику. Можно сгенерировать:
CUDA® код с использованием GPU Coder™
Код C/C + + с использованием MATLAB Coder™
Чтобы создать функцию оценки политики, которая выбирает действие на основе заданного наблюдения, используйте generatePolicyFunction (Reinforcement Learning Toolbox) команда. Эта команда генерирует скрипт MATLAB, который содержит функцию оценки политики, и MAT-файл, который содержит оптимальные данные политики.
Вы можете сгенерировать код для развертывания этой функции политики с помощью GPU Coder или MATLAB Coder.
Для получения дополнительной информации см. раздел Развертывание настроенных политик обучения с подкреплением (Reinforcement Learning Toolbox).
