Используйте оптимизацию площади и скорости в HDL- Coder™, чтобы сэкономить ресурсы и улучшить сроки вашего проекта на целевом устройстве FPGA. Оптимизация не изменяет функциональное поведение вашего алгоритма, но может оптимизировать определенные ресурсы в вашем проекте, ввести задержку или вызвать различие в скоростях дискретизации.
Вы можете первоначально сгенерировать HDL-код и синтезировать ваш проект на вашей платформе FPGA, не позволяя оптимизировать. Если проект не соответствует требованиям синхронизации, можно включить оптимизацию и перезапустить рабочий процесс, пока ваш проект не будет соответствовать требованиям к области и скорости. Смотрите Рабочий процесс Basic Генерации HDL-кода.
Чтобы включить оптимизацию на MATLAB® Код откройте Рабочий процесс Advisor из MATLAB. В окне Advisor, на HDL Code Generation задаче, включите настройки на вкладке Optimization.
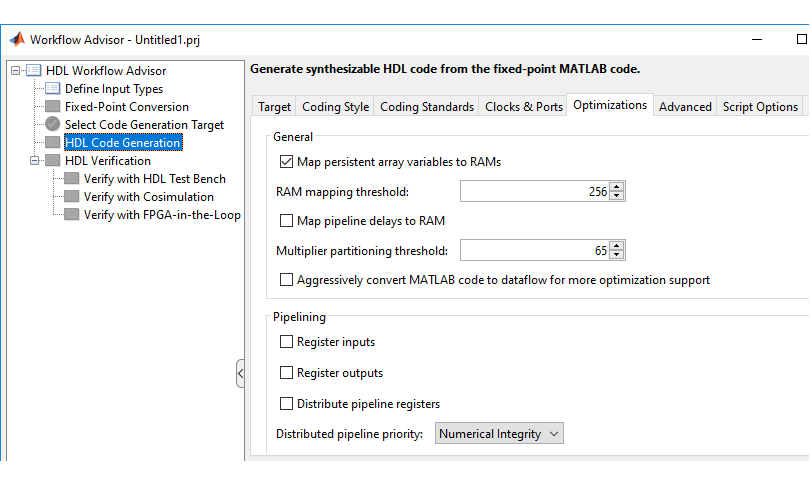
Можно включить оптимизацию на уровне модели и на уровне блоков. Задайте оптимизацию уровня модели:
В диалоговом окне «Параметры конфигурации» на панели HDL Code Generation > Optimization. См. раздел «Панель генерации HDL-кода: оптимизация».
В командной строке при помощи makehdl или hdlset_param функция для установки значения свойства.
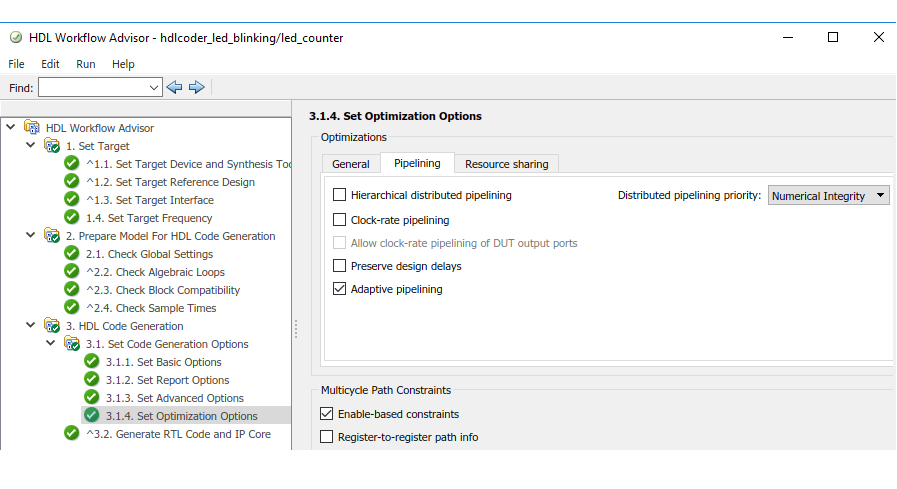
В Simulink® HDL Workflow Advisor, о задаче Set Code Generation Options > Set Optimization Options.
Подсистемы в вашей модели наследуют настройки оптимизации уровня модели. Вы можете изменить настройки уровня подсистемы в диалоговом окне HDL Block Properties для подсистем или с помощью hdlset_param функция. Можно также задать определенные дополнительные настройки для определенных блоков в модели, такие как добавление трубопроводов на входе и выходе. Эта таблица иллюстрирует различные оптимизации, которые доступны на уровне блоков и уровне модели.
| Оптимизация | Уровень модели? | Уровень подсистемы? | Комментарии |
|---|---|---|---|
| Балансировка задержки | Да | Да | – |
| Отображение ОЗУ | Да | Нет | – |
| Адаптивная конвейеризация | Да | Да | – |
| Тактовая частота конвейеризации | Да | Да | – |
| Распределённая конвейеризация | Да | Да | На уровне модели используется иерархическое распределённая конвейеризация. Чтобы применить оптимизацию между иерархиями подсистем, включите распределённую конвейеризацию на каждом уровне подсистемы. |
| Совместное использование ресурсов | Да | Да | На уровне модели вы задаете тип ресурсов, которыми хотите поделиться, таких как сумматоры и множители. На уровне блоков вы задаете SharingFactor. |
| Вытекание | Нет | Да | – |
Чтобы увидеть эффект оптимизации:
Можно сгенерировать отчет оптимизации с HDL-кодом. Чтобы узнать, как включить этот отчет, смотрите Создание и использование отчетов генерации кода.
Откройте сгенерированную модель или сгенерируйте модель валидации. Сгенерированная модель является поведенческой моделью HDL-кода, которая показывает эффект реализации блоков и оптимизации, которые вы включили. Чтобы проверить цифры сгенерированной модели с исходной моделью, можно сгенерировать модель валидации. См. Сгенерированная модель и модель валидации.
Совет
Чтобы эффективно использовать оптимизацию, измените настройку шага расчета для блоков Constant из Inf на -1.
Ваша модель может иметь проектные задержки и задержки трубопровода. Design delays задержки, которые вы вручную добавляете к модели. Pipeline delays задержки, которые вводятся настройками конвейеризации, заданными на блоках, реализациями блоков, такими как метод Ньютона-Рафсона, собственными операторами с плавающей точкой или оптимизацией скорости. Вы видите эти задержки в сгенерированном HDL-коде, сгенерированной модели и модели валидации.
Общие параметры оптимизации включают:
Сопоставление ОЗУ: используйте параметры отображения ОЗУ для отображения больших задержек, стойких переменных в коде MATLAB и задержек конвейера в ОЗУ на основе пороговой ширины бита. Смотрите также Сопоставление ОЗУ для MATLAB Code и RAM Mapping Parameters.
Балансировка задержки: Включена по умолчанию, эта оптимизация балансирует задержки трубопровода, вставляя соответствующие задержки в параллельные пути. Оптимизация соответствует числам сгенерированной модели с исходной моделью. Эффект этой оптимизации отображается в Delay Balancing разделе отчета об оптимизации. См. Раздел «Балансировка задержки»
Оптимизация скорости улучшает время вашего проекта на целевом FPGA путем оптимизации критического пути. Чтобы идентифицировать критический путь, можно запустить Generic ASIC/FPGA рабочий процесс для устройства FPGA, а затем аннотируйте критический путь или используйте отчеты синхронизации.
Чтобы быстрее идентифицировать критический путь и ускорить итерационный процесс нахождения и оптимизации критического пути, используйте оценку критического пути. Вам не нужно запускать синтез или генерировать HDL-код. Оценка критического пути использует статический анализ синхронизации с данными синхронизации из целевых баз данных синхронизации. Эффект этой оптимизации отображается в Critical Path Estimation разделе отчета об оптимизации. Смотрите оценку критического пути без выполнения синтеза.
Оптимизация скорости включает в себя:
Clock rate pipelining: Оптимизация Simulink, которая включена по умолчанию и запускает регистры конвейера с более высокой тактовой частотой, когда вы задаете Oversampling factor, больше единицы. Используйте конвейеризацию с тактовой частотой с иерархическим сплющиванием, чтобы удалить иерархические контуры в подсистеме, тем самым улучшая ретиминирование. См. Раздел «Трубная конвейеризация с тактовой частотой»
Distributed pipelining: Оптимизация, которая возвращает регистры, которые являются существующими задержками или заданы с помощью InputPipeline и OutputPipeline параметров блока. Чтобы сохранить существующие задержки, включите параметр Сохранить задержки проекта. Включите иерархическую распределенную конвейеризацию в модели и распределенную конвейеризацию в подсистемах для синхронизации регистров между иерархиями. Эффект этой оптимизации отображается в Distributed Pipelining разделе отчета об оптимизации. См. Раздел Распределять конвейеризацию и иерархическую распределять конвейеризацию.
Adaptive pipelining: Оптимизация Simulink, которая вставляет регистры конвейера на входе или выходе или обоих портов определенных блоков, чтобы создать шаблоны, которые эффективно сопоставляют блоки с модулями DSP на целевом устройстве FPGA. Оптимизация учитывает целевое устройство, целевую частоту, размеры слова умножителей и настройки свойств блоков. Эффект этой оптимизации отображается в Adaptive Pipelining разделе отчета об оптимизации. См. Раздел «Адаптивная конвейеризация»
Loop Unrolling: Оптимизация MATLAB, которая разворачивает цикл путем создания экземпляров нескольких образцов тела цикла в сгенерированном коде. Можно также частично развернуть цикл. Смотрите Оптимизацию циклов MATLAB
Оптимизация областей сокращает использование ресурсов вашего проекта. Оптимизация вашего проекта на площадь может снизить скорость, с которой ваш проект работает на FPGA.
Оптимизация площади включает в себя:
Resource Sharing: Оптимизация, которая идентифицирует несколько функционально эквивалентных ресурсов и заменяет их одним ресурсом. На уровне модели вы задаете ресурсы, которыми хотите делиться, такие как сумматоры и множители. На уровне подсистемы вы задаете SharingFactor в зависимости от количества общедоступных ресурсов в проекте. Используя оптимизацию с конвейеризацией по тактовой частоте, можно задать, как разгонять общие ресурсы. См. Раздел «Совместное использование ресурсов»
Streaming: Оптимизация Simulink, которая разделяет путь векторных данных на несколько меньших путей векторных данных на основе StreamingFactor, которые вы задаете в подсистемах, тем самым уменьшая потребление аппаратных ресурсов. См. Потоковая передача.
Loop Streaming: Оптимизация MATLAB, которая потокует цикл путем создания экземпляра тела цикла один раз и использования этого образца для каждой итерации цикла. Генератор кода переизбирает образец тела цикла, чтобы сохранить сгенерированный цикл функционально эквивалентным исходному циклу. Смотрите Оптимизацию циклов MATLAB
