Используйте эти наборы данных, чтобы начать с применением глубокого обучения.
| Набор данных | Описание | Задача |
|---|---|---|
Цифры
| Набор данных Цифр состоит из 10 000 синтетических полутоновых изображений рукописных цифр. Каждое изображение является 28 28 пикселями и имеет связанную метку, обозначающую, какую цифру изображение представляет (0–9). Каждое изображение вращалось определенным углом. При загрузке изображений как массивов можно также загрузить угол поворота изображения. Загрузите данные о Цифрах как числовые массивы в оперативной памяти с помощью [XTrain,YTrain,anglesTrain] = digitTrain4DArrayData; [XTest,YTest,anglesTest] = digitTest4DArrayData; Для примеров, показывающих, как обработать эти данные для глубокого обучения, смотрите Процесс обучения Глубокого обучения Монитора и Обучите Сверточную нейронную сеть Регрессии. | Отобразите классификацию и отобразите регрессию |
Загрузите данные о Цифрах как datastore изображений с помощью dataFolder = fullfile(toolboxdir('nnet'),'nndemos','nndatasets','DigitDataset'); imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true,'LabelSource','foldernames'); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Создают Простую сеть глубокого обучения для Классификации. | Отобразите классификацию | |
MNIST
(Представительный пример) | Набор данных MNIST состоит из 70 000 рукописных разделений цифр в обучение и тестовые разделы 60 000 и 10 000 изображений, соответственно. Каждое изображение является 28 28 пикселями и имеет связанную метку, обозначающую, какую цифру изображение представляет (0–9). Загрузите файлы MNIST с http://yann.lecun.com/exdb/mnist/ и загрузите набор данных в рабочую область. Чтобы загрузить данные из файлов как массивы MATLAB, поместите файлы в рабочую директорию, затем используйте функции помощника oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); filenameImagesTrain = 'train-images-idx3-ubyte.gz'; filenameLabelsTrain = 'train-labels-idx1-ubyte.gz'; filenameImagesTest = 't10k-images-idx3-ubyte.gz'; filenameLabelsTest = 't10k-labels-idx1-ubyte.gz'; XTrain = processImagesMNIST(filenameImagesTrain); YTrain = processLabelsMNIST(filenameLabelsTrain); XTest = processImagesMNIST(filenameImagesTest); YTest = processLabelsMNIST(filenameLabelsTest); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Обучают Вариационный Автоэнкодер (VAE) Генерировать Изображения. Чтобы восстановить путь, используйте path(oldpath); | Отобразите классификацию |
Omniglot
| Набор данных Omniglot содержит наборы символов для 50 алфавитов, разделенных на 30 наборов для обучения и 20 наборов для тестирования [1]. Каждый алфавит содержит много символов, от 14 для Ojibwe (канадский исконный syllabics) к 55 для Tifinagh. Наконец, каждый символ имеет 20 рукописных наблюдений. Загрузите и извлеките набор данных Omniglot из https://github.com/brendenlake/omniglot. Установите downloadFolder = tempdir; url = "https://github.com/brendenlake/omniglot/raw/master/python"; urlTrain = url + "/images_background.zip"; urlTest = url + "/images_evaluation.zip"; filenameTrain = fullfile(downloadFolder,"images_background.zip"); filenameTest = fullfile(downloadFolder,"images_evaluation.zip"); dataFolderTrain = fullfile(downloadFolder,"images_background"); dataFolderTest = fullfile(downloadFolder,"images_evaluation"); if ~exist(dataFolderTrain,"dir") fprintf("Downloading Omniglot training data set (4.5 MB)... ") websave(filenameTrain,urlTrain); unzip(filenameTrain,downloadFolder); fprintf("Done.\n") end if ~exist(dataFolderTest,"dir") fprintf("Downloading Omniglot test data (3.2 MB)... ") websave(filenameTest,urlTest); unzip(filenameTest,downloadFolder); fprintf("Done.\n") end Чтобы загрузить обучение и тестовые данные как хранилища данных изображений, используйте imdsTrain = imageDatastore(dataFolderTrain, ... 'IncludeSubfolders',true, ... 'LabelSource','none'); files = imdsTrain.Files; parts = split(files,filesep); labels = join(parts(:,(end-2):(end-1)),'_'); imdsTrain.Labels = categorical(labels); imdsTest = imageDatastore(dataFolderTest, ... 'IncludeSubfolders',true, ... 'LabelSource','none'); files = imdsTest.Files; parts = split(files,filesep); labels = join(parts(:,(end-2):(end-1)),'_'); imdsTest.Labels = categorical(labels); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Обучают сиамскую Сеть, чтобы Сравнить Изображения. | Отобразите подобие |
Цветы
| Цветочный набор данных содержит 3 670 изображений цветов, принадлежащих пяти классам (гирлянда, одуванчик, розы, подсолнечники и тюльпаны) [2]. Загрузите и извлеките Цветочный набор данных из http://download.tensorflow.org/example_images/flower_photos.tgz. Набор данных составляет приблизительно 218 Мбайт. Установите url = 'http://download.tensorflow.org/example_images/flower_photos.tgz'; downloadFolder = tempdir; filename = fullfile(downloadFolder,'flower_dataset.tgz'); dataFolder = fullfile(downloadFolder,'flower_photos'); if ~exist(dataFolder,'dir') fprintf("Downloading Flowers data set (218 MB)... ") websave(filename,url); untar(filename,downloadFolder) fprintf("Done.\n") end Загрузите данные как datastore изображений с помощью imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true, ... 'LabelSource','foldernames'); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Обучают Порождающую соперничающую сеть (GAN). | Отобразите классификацию |
Продовольственные изображения в качестве примера
| Продовольственный набор данных Изображений В качестве примера содержит 978 фотографий еды в девяти классах (caesar_salad, caprese_salad, french_fries, greek_salad, гамбургер, hot_dog, пицца, сашими и суши). Загрузите Продовольственный набор данных Изображений В качестве примера с помощью fprintf("Downloading Example Food Image data set (77 MB)... ") filename = matlab.internal.examples.downloadSupportFile('nnet', ... 'data/ExampleFoodImageDataset.zip'); fprintf("Done.\n") filepath = fileparts(filename); dataFolder = fullfile(filepath,'ExampleFoodImageDataset'); unzip(filename,dataFolder); Для примера, показывающего, как обработать эти данные для глубокого обучения, Поведения Сети вида на море Используя tsne. | Отобразите классификацию |
CIFAR-10
(Представительный пример) | Набор данных CIFAR-10 содержит 60 000 цветных изображений размера 32 32 пиксели, принадлежа 10 классам (самолет, автомобиль, птица, кошка, олень, собака, лягушка, лошадь, поставка и грузовик) [7]. Существует 6 000 изображений в классе. Набор данных разделен в набор обучающих данных с 50 000 изображений и набор тестов с 10 000 изображений. Этот набор данных является одним из наиболее широко используемых наборов данных для тестирования новых моделей классификации изображений. Загрузите и извлеките набор данных CIFAR-10 из https://www.cs.toronto.edu/%7Ekriz/cifar-10-matlab.tar.gz. Набор данных составляет приблизительно 175 Мбайт. Установите url = 'https://www.cs.toronto.edu/~kriz/cifar-10-matlab.tar.gz'; downloadFolder = tempdir; filename = fullfile(downloadFolder,'cifar-10-matlab.tar.gz'); dataFolder = fullfile(downloadFolder,'cifar-10-batches-mat'); if ~exist(dataFolder,'dir') fprintf("Downloading CIFAR-10 dataset (175 MB)... "); websave(filename,url); untar(filename,downloadFolder); fprintf("Done.\n") end loadCIFARData, который используется в примере, Обучают Остаточную Сеть для Классификации Изображений.oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); [XTrain,YTrain,XValidation,YValidation] = loadCIFARData(downloadFolder); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Обучают Остаточную Сеть для Классификации Изображений. Чтобы восстановить путь, используйте path(oldpath); | Отобразите классификацию |
MathWorks® Товар
| Набор данных MathWorks Merch является небольшим набором данных, содержащим 75 изображений товаров MathWorks, принадлежа пяти различным классам (дно, куб, игра в карты, отвертка и факел). Можно использовать этот набор данных, чтобы испытать передачу обучения и классификацию изображений быстро. Изображения имеют размер 227 227 3. Извлеките набор данных MathWorks Merch. filename = 'MerchData.zip'; dataFolder = fullfile(tempdir,'MerchData'); if ~exist(dataFolder,'dir') unzip(filename,tempdir); end Загрузите данные как datastore изображений с помощью imds = imageDatastore(dataFolder, ... 'IncludeSubfolders',true,'LabelSource','foldernames'); Для примеров, показывающих, как обработать эти данные для глубокого обучения, смотрите Начало работы с Передачей обучения и Обучите Нейронную сеть для глубокого обучения Классифицировать Новые Изображения. | Отобразите классификацию |
CamVid
| Набор данных CamVid является набором изображений, содержащих представления уличного уровня, полученные из автомобилей, управляемых [8]. Набор данных полезен для того, чтобы обучить нейронные сети, которые выполняют семантическую сегментацию изображений, и обеспечивает метки пиксельного уровня для 32 семантических классов, включая автомобиль, пешехода и дорогу. Изображения имеют размер 720 960 3. Загрузите и извлеките набор данных CamVid из http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData/. Набор данных составляет приблизительно 573 Мбайта. Установите downloadFolder = tempdir; url = "http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData" urlImages = url + "/files/701_StillsRaw_full.zip"; urlLabels = url + "/data/LabeledApproved_full.zip"; dataFolder = fullfile(downloadFolder,'CamVid'); dataFolderImages = fullfile(dataFolder,'images'); dataFolderLabels = fullfile(dataFolder,'labels'); filenameLabels = fullfile(dataFolder,'labels.zip'); filenameImages = fullfile(dataFolder,'images.zip'); if ~exist(filenameLabels, 'file') || ~exist(imagesZip,'file') mkdir(dataFolder) fprintf("Downloading CamVid data set images (557 MB)... "); websave(filenameImages, urlImages); unzip(filenameImages, dataFolderImages); fprintf("Done.\n") fprintf("Downloading CamVid data set labels (16 MB)... "); websave(filenameLabels, urlLabels); unzip(filenameLabels, dataFolderLabels); fprintf("Done.\n") end Загрузите данные как пиксельный datastore метки с помощью oldpath = addpath(fullfile(matlabroot,'examples','deeplearning_shared','main')); imds = imageDatastore(dataFolderImages,'IncludeSubfolders',true); classes = ["Sky" "Building" "Pole" "Road" "Pavement" "Tree" ... "SignSymbol" "Fence" "Car" "Pedestrian" "Bicyclist"]; labelIDs = camvidPixelLabelIDs; pxds = pixelLabelDatastore(dataFolderLabels,classes,labelIDs); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Семантическая Сегментация Использует Глубокое обучение. Чтобы восстановить путь, используйте path(oldpath); | Семантическая сегментация |
Транспортное средство
| Набор данных Транспортного средства состоит из 295 изображений, содержащих один или два помеченных экземпляра транспортного средства. Этот небольшой набор данных полезен для исследования метода обучения YOLO-v2, но на практике, более помеченные изображения необходимы, чтобы обучить устойчивый детектор. Изображения имеют размер 720 960 3. Извлеките набор данных Транспортного средства. Установите filename = 'vehicleDatasetImages.zip'; dataFolder = fullfile(tempdir,'vehicleImages'); if ~exist(dataFolder,'dir') unzip(filename,tempdir); end Загрузите набор данных как таблицу имен файлов и ограничительных рамок из извлеченного файла MAT и преобразуйте имена файлов в абсолютные пути к файлам. data = load('vehicleDatasetGroundTruth.mat');
vehicleDataset = data.vehicleDataset;
vehicleDataset.imageFilename = fullfile(tempdir,vehicleDataset.imageFilename);Создайте datastore изображений, содержащий изображения и datastore метки поля, содержащий ограничительные рамки с помощью filenamesImages = vehicleDataset.imageFilename;
tblBoxes = vehicleDataset(:,'vehicle');
imds = imageDatastore(filenamesImages);
blds = boxLabelDatastore(tblBoxes);
cds = combine(imds,blds);Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Обнаружение объектов Использует глубокое обучение YOLO v2. | Обнаружение объектов |
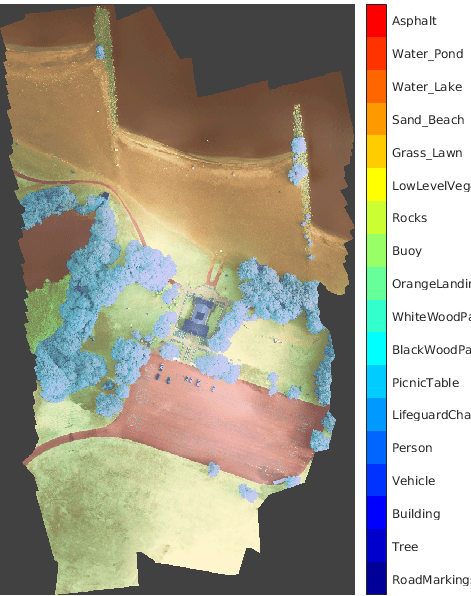
RIT-18
| Набор данных RIT-18 содержит данные изображения, полученные беспилотником по национальному парку Hamlin Beach в штате Нью-Йорк [9]. Данные содержат помеченное обучение, валидацию и наборы тестов, с 18 метками класса объекта включая дорожные разметки, дерево и создание. Набор данных составляет приблизительно 3 Гбайт. Загрузите набор данных RIT-18 с https://www.cis.rit.edu/%7Ermk6217/rit18_data.mat. Установите downloadFolder = tempdir; url = 'http://www.cis.rit.edu/~rmk6217/rit18_data.mat'; filename = fullfile(downloadFolder,'rit18_data.mat'); if ~exist(filename,'file') fprintf("Downloading Hamlin Beach data set (3 GB)... "); websave(filename,url); fprintf("Done.\n") end Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Семантическую Сегментацию Многоспектральных Изображений Используя Глубокое обучение. | Семантическая сегментация |
BraTS
| Набор данных BraTS содержит сканы MRI опухолей головного мозга, а именно, глиом, которые являются наиболее распространенной первичной мозговой зловредностью [10]. Набор данных содержит 750 4-D объемов, каждый представляющий стек 3-D изображений. Каждый 4-D объем имеет размер 240 240 155 4, где первые три измерения соответствуют высоте, ширине и глубине 3-D объемного изображения. Четвертая размерность соответствует различной модальности скана. Набор данных разделен на 484 учебных объема с метками вокселя и 266 тестовых объемов. Набор данных составляет приблизительно 7 Гбайт. Создайте директорию, чтобы сохранить набор данных BraTS. dataFolder = fullfile(tempdir,'BraTS'); if ~exist(dataFolder,'dir') mkdir(dataFolder); end Загрузите данные BraTS из Медицинского Десятиборья Сегментации путем щелкания по ссылке "Download Data". Загрузите файл "Task01_BrainTumour.tar". Извлеките файл TAR в директорию, заданную Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что 3-D Сегментация Опухоли головного мозга Использует Глубокое обучение. | Семантическая сегментация |
Camelyon16
| Данные из проблемы Camelyon16 содержат в общей сложности 400 изображений целого понижения (WSIs) лимфатических узлов из двух независимых источников, разделенных на 270 учебных изображений и 130 тестовых изображений [11]. Набор данных составляет приблизительно 451 Гбайт. Обучающий набор данных состоит из 159 WSIs нормальных лимфатических узлов и 111 WSIs лимфатических узлов с опухолью и здоровой ткани. Обычно, ткань опухоли является небольшой частью здоровой ткани. Координаты основной истины контуров повреждения сопровождают изображения опухоли. Создайте директории, чтобы сохранить набор данных Camelyon16. dataFolderTrain = fullfile(tempdir,'Camelyon16','training'); dataFolderNormalTrain = fullfile(dataFolderTrain,'normal'); dataFolderTumorTrain = fullfile(dataFolderTrain,'tumor'); dataFolderAnnotationsTrain = fullfile(dataFolderTrain,'lesion_annotations'); if ~exist(dataFolderTrain,'dir') mkdir(dataFolderTrain); mkdir(dataFolderNormalTrain); mkdir(dataFolderTumorTrain); mkdir(dataFolderAnnotationsTrain); end Загрузите набор данных Camelyon16 с Camelyon17 путем щелкания по первой "ссылке" набора данных CAMELYON16. Откройте "учебную" директорию, затем выполните эти шаги:
Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Предварительно обрабатывают Изображения Мультиразрешения для Учебной Сети Классификации (Image Processing Toolbox). | Отобразите классификацию (большие изображения) |
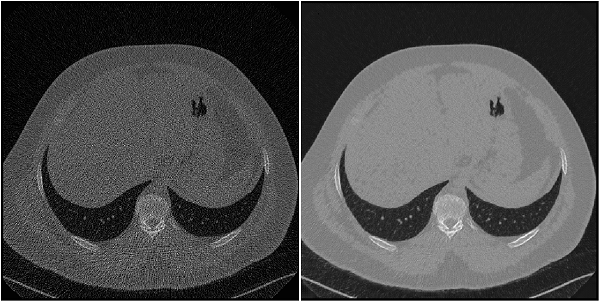
Низкий CT дозы главная проблема
| Главный вызов CT Низкой Дозы включает пары изображений CT регулярной дозы, и симулированные изображения CT низкой дозы для 99 главных сканов (пометил N для neuro), 100 сканов грудной клетки (пометил C для груди), и 100 сканов живота (пометил L для печени)[12], [13]. Полный набор данных составляет приблизительно 1,2 Тбайта. Создайте директорию, чтобы хранить файлы грудной клетки от Низкого CT Дозы Главный набор данных проблемы.
dataDir = fullfile(tempdir,"LDCT","LDCT-and-Projection-data"); if ~exist(dataDir,'dir') mkdir(dataDir); end Чтобы загрузить данные, перейдите к веб-сайту Архива Обработки изображений Рака. Загрузите файлы грудной клетки с "Изображений (DICOM, 952 Гбайт)" набор данных с помощью Ретривера Данных NBIA. Задайте Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Безнадзорное Медицинское Шумоподавление Изображений Использует CycleGAN. | Регрессия от изображения к изображению |
Общие объекты в контексте (COCO)
(Представительный пример) | COCO 2014 обучается, набор данных изображений состоит из 82 783 изображений. Данные об аннотациях содержат по крайней мере пять заголовков, соответствующих каждому изображению. Создайте директории, чтобы сохранить набор данных COCO. dataFolder = fullfile(tempdir,"coco"); if ~exist(dataFolder,'dir') mkdir(dataFolder); end Загрузите и извлеките COCO 2014, обучают изображения и заголовки под эгидой https://cocodataset.org/#download путем щелкания по ссылкам "2014 Train images" и "2014 Train/Val annotations", соответственно. Сохраните в папке данные, заданные Извлеките заголовки из файла filename = fullfile(dataFolder,"annotations_trainval2014","annotations", ... "captions_train2014.json"); str = fileread(filename); data = jsondecode(str);
Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Изображение Озаглавливает Используя Внимание. | Отобразите ввод субтитров |
IAPR TC-12
(Представительный пример) | Сравнительный тест IAPR TC-12 состоит из 20 000 все еще естественных изображений [14]. Набор данных включает фотографии людей, животных, города и т.д. Файл данных составляет приблизительно 1,8 Гбайт. Загрузите набор данных IAPR TC-12. dataDir = fullfile(tempdir,'iaprtc12'); url = 'http://www-i6.informatik.rwth-aachen.de/imageclef/resources/iaprtc12.tgz'; if ~exist(dataDir,'dir') fprintf('Downloading IAPR TC-12 data set (1.8 GB)...\n'); try untar(url,dataDir); catch % On some Windows machines, the untar command throws an error for .tgz % files. Rename to .tg and try again. fileName = fullfile(tempdir,'iaprtc12.tg'); websave(fileName,url); untar(fileName,dataDir); end fprintf('Done.\n\n'); end Загрузите данные как datastore изображений с помощью imageDir = fullfile(dataDir,'images') exts = {'.jpg','.bmp','.png'}; imds = imageDatastore(imageDir, ... 'IncludeSubfolders',true,'FileExtensions',exts); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Одно Суперразрешение Изображений Использует Глубокое обучение. | Регрессия от изображения к изображению |
Цюрихские СЫРЫЕ ДАННЫЕ к RGB
| Цюрихские СЫРЫЕ ДАННЫЕ к набору данных RGB содержат 48 043 пространственно зарегистрированных пары СЫРЫХ ДАННЫХ и закрашенные фигуры обучения RGB изображений размера 448 448 [15]. Набор данных содержит два отдельных набора тестов. Один набор тестов состоит из 1 204 пространственно зарегистрированных пар СЫРЫХ ДАННЫХ и закрашенных фигур RGB изображений размера 448 448. Другой набор тестов состоит из незарегистрированных СЫРЫХ ДАННЫХ полного разрешения и изображений RGB. Набор данных составляет 22 Гбайт. Создайте директорию, чтобы сохранить Цюрихские СЫРЫЕ ДАННЫЕ к набору данных RGB. imageDir = fullfile(tempdir,'ZurichRAWToRGB'); if ~exist(imageDir,'dir') mkdir(imageDir); end imageDir переменная. Если экстракция успешна, то imageDir содержит три директории: full_resolutionТест, и train.Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Разрабатывают НЕОБРАБОТАННЫЙ Конвейер обработки Камеры Используя Глубокое обучение. | Регрессия от изображения к изображению |
Смотрите В темноте (SID)
| Видение В темноте (SID) набор данных обеспечивает указанные пары НЕОБРАБОТАННЫХ изображений той же сцены [16]. В каждой паре одно изображение имеет короткую выдержку и недоэкспонируется, и другое изображение имеет более длительную выдержку и хорошо отсоединено. Размер данных о камере Sony из набора данных SID составляет 25 Гбайт. Создайте директорию, чтобы хранить данные о камере Sony от набора данных SID. dataDir = fullfile(tempdir,"SID"); if ~exist(dataDir,"dir") mkdir(dataDir); end Чтобы загрузить набор данных, перейдите к этой ссылке: https://storage.googleapis.com/isl-datasets/SID/Sony.zip. Извлеките данные в директорию, заданную Набор данных также предоставляет текстовые файлы, которые описывают, как разделить файлы в обучение, валидацию и наборы тестовых данных. Переместите файлы "Sony_train_list.txt", "Sony_val_list.txt" и "Sony_test_list.txt" к директории, заданной Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Восстанавливают Изображения с Экстремального Слабого освещения Используя Глубокое обучение. | Регрессия от изображения к изображению |
LIVE в дикой природе
| LIVE В Диком наборе данных состоит из 1 162 фотографий, полученных мобильными устройствами с семью дополнительными учебными изображениями [17]. Каждое изображение оценивается в среднем 175 индивидуумами по шкале [1, 100]. Набор данных обеспечивает среднее и стандартное отклонение субъективной музыки к каждому изображению. Создайте директорию, чтобы сохранить LIVE В Диком наборе данных. imageDir = fullfile(tempdir,"LIVEInTheWild"); if ~exist(imageDir,'dir') mkdir(imageDir); end Загрузите набор данных путем следования инструкциям, обрисованным в общих чертах в LIVE В Дикой Базе данных проблемы Качества изображения. Извлеките данные в директорию, заданную Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Определяют количество Качества изображения Используя Нейронную Оценку Изображений. | Отобразите классификацию |
Конкретные взломанные изображения для классификации
| Конкретные Взломанные Изображения для набора данных Классификации содержат изображения двух классов: "Отрицательные" изображения без трещин, существующих на дороге и "Положительных" изображениях с трещинами [18]. Набор данных обеспечивает 20 000 изображений каждого класса. Размер набора данных составляет 235 Мбайт. Создайте директорию, чтобы сохранить набор данных. dataDir = fullfile(tempdir,"ConcreteCracks"); if ~exist(dataDir,"dir") mkdir(dataDir); end Чтобы загрузить набор данных, перейдите к этой ссылке: Конкретные Взломанные Изображения для Классификации. Извлеките zip-файл, чтобы получить файл RAR, затем извлеките содержимое файла RAR в директорию, заданную Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Обнаруживают Аномалии Изображений Используя Объяснимую Нейронную сеть Классификации Одного класса. | Отобразите классификацию |
| Данные | Описание | Задача |
|---|---|---|
Японские гласные
| Японский набор данных Гласных содержит предварительно обработанные последовательности, представляющие произнесение японских гласных от различного [19] [20] динамиков.
Загрузите японский набор данных Гласных как массивы ячеек в оперативной памяти, содержащие числовые последовательности с помощью [XTrain,YTrain] = japaneseVowelsTrainData; [XTest,YTest] = japaneseVowelsTestData; Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Классификация Последовательностей Использует Глубокое обучение. | Классификация последовательностей к метке |
Ветрянка
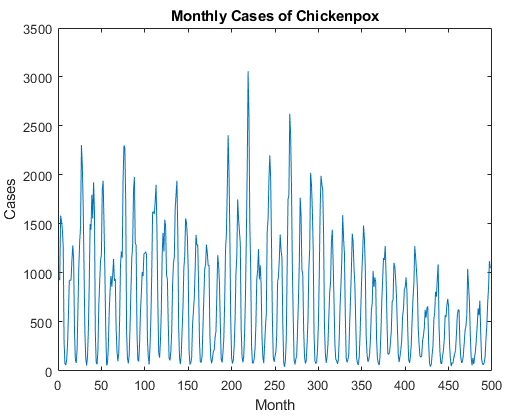
| Набор данных Ветрянки содержит одни временные ряды с временными шагами, соответствующими месяцам и значениям, соответствующим количеству случаев. Выход является массивом ячеек, где каждым элементом является один временной шаг. Загрузите данные о Ветрянке как сингл числовые последовательности с помощью data = chickenpox_dataset;
data = [data{:}];Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Временные ряды Предсказывают Используя Глубокое обучение. | Прогнозирование временных рядов |
Деятельность человека
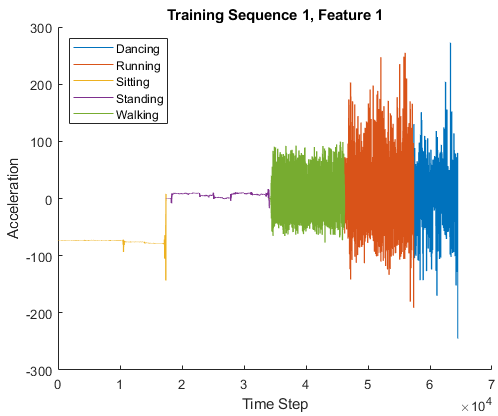
| Набор данных Деятельности человека содержит семь временных рядов данных о датчике, полученных из смартфона, который изнашивают на теле. Каждая последовательность имеет три функции и варьируется по длине. Три функции соответствуют показаниям акселерометра в трех различных направлениях. Загрузите набор данных Деятельности человека. dataTrain = load('HumanActivityTrain'); dataTest = load('HumanActivityTest'); XTrain = dataTrain.XTrain; YTrain = dataTrain.YTrain; XTest = dataTest.XTest; YTest = dataTest.YTest; Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Классификация От последовательности к последовательности Использует Глубокое обучение. | Классификация от последовательности к последовательности |
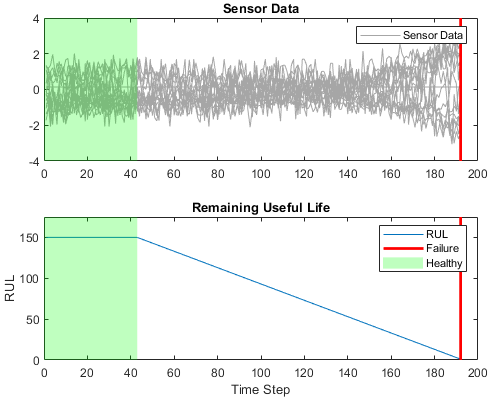
Турбовентиляторная симуляция ухудшения Engine
| Каждые временные ряды Турбовентиляторного набора Данных моделирования Ухудшения Engine представляют различный механизм [21]. Каждый механизм запускается с неизвестных степеней начального износа и производственного изменения. Механизм действует обычно в начале каждых временных рядов и разрабатывает отказ в какой-то момент во время ряда. В наборе обучающих данных отказ растет в величине до системного отказа. Данные содержат сжатые до ZIP текстовые файлы с 26 столбцами чисел, разделенных пробелами. Каждая строка является снимком состояния данных, взятых во время одного рабочего цикла, и каждый столбец является различной переменной. Столбцы соответствуют следующему:
Создайте директорию, чтобы сохранить Турбовентиляторный набор Данных моделирования Ухудшения Engine. dataFolder = fullfile(tempdir,"turbofan"); if ~exist(dataFolder,'dir') mkdir(dataFolder); end Загрузите и извлеките Турбовентиляторный Набор Данных моделирования Ухудшения Engine из https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/. Разархивируйте данные из файла filename = "CMAPSSData.zip";
unzip(filename,dataFolder)Загрузите обучение и тестовые данные с помощью функций помощника oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); filenamePredictors = fullfile(dataFolder,"train_FD001.txt"); [XTrain,YTrain] = processTurboFanDataTrain(filenamePredictors); filenamePredictors = fullfile(dataFolder,"test_FD001.txt"); filenameResponses = fullfile(dataFolder,"RUL_FD001.txt"); [XTest,YTest] = processTurboFanDataTest(filenamePredictors,filenameResponses); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Регрессия От последовательности к последовательности Использует Глубокое обучение. Чтобы восстановить путь, используйте path(oldpath); | Регрессия от последовательности к последовательности, прогнозирующее обслуживание |
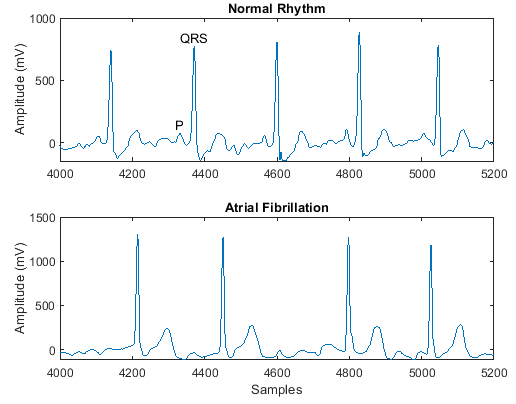
Проблема PhysioNet 2017
| Набор данных PhysioNet 2017 проблемы состоит из набора электрокардиограммы (ECG) записи, произведенные на уровне 300 Гц и разделенные на группу экспертов в различные классы [23]. Загрузите и извлеките набор данных PhysioNet 2017 проблемы с помощью Набор данных составляет приблизительно 95 Мбайт. oldpath = addpath(fullfile(matlabroot,'examples','deeplearning_shared','main')); ReadPhysionetData data = load('PhysionetData.mat') signals = data.Signals; labels = data.Labels; Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Классифицируют Сигналы ECG Используя Длинные Краткосрочные Сети Памяти. Чтобы восстановить путь, используйте path(oldpath); | Классификация последовательностей к метке |
Симуляция Процесса Теннесси Истмэна (TEP)
| Этот набор данных состоит из файлов MAT, преобразованных от данных моделирования Процесса Теннесси Истмэна (TEP) [22]. Загрузите набор данных моделирования Процесса Теннесси Истмэна (TEP) с сайта файлов поддержки MathWorks (см. правовую оговорку). Набор данных имеет четыре компонента: безотказное обучение, безотказное тестирование, дефектное обучение и дефектное тестирование. Загрузите каждый файл отдельно. Набор данных составляет 1,7 Гбайт. fprintf("Downloading TEP faulty training data (613 MB)... ") filenameFaultyTrain = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultytraining.mat'); fprintf("Done.\n") fprintf("Downloading TEP faulty testing data (1 GB)... ") filenameFaultyTest = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultytesting.mat'); fprintf("Done.\n") fprintf("Downloading TEP fault-free training data (36 MB)... ") filenameFaultFreeTrain = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultfreetraining.mat'); fprintf("Done.\n") fprintf("Downloading TEP fault-free testing data (69 MB)... ") filenameFaultFreeTest = matlab.internal.examples.downloadSupportFile('predmaint', ... 'chemical-process-fault-detection-data/faultfreetesting.mat'); fprintf("Done.\n") Загрузите загруженные файлы в MATLAB® рабочая область. load(filenameFaultyTrain); load(filenameFaultyTest); load(filenameFaultFreeTrain); load(filenameFaultFreeTest); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Химическое Обнаружение Отказа Процесса Использует Глубокое обучение. | Классификация последовательностей к метке |
Сегментация PhysioNet ECG
| Набор данных PhysioNet ECG Сегментации состоит примерно из 15 минут записей ECG от в общей сложности 105 [23] [24] пациентов. Чтобы получить каждую запись, ревизоры поместили два электрода в другие места на груди пациента, приводящей к двухканальному сигналу. База данных обеспечивает метки области сигнала, сгенерированные автоматизированной экспертной системой. Загрузите набор данных PhysioNet ECG Сегментации с https://github.com/mathworks/physionet_ECG_segmentation путем загрузки zip-файла downloadFolder = tempdir; url = "https://github.com/mathworks/physionet_ECG_segmentation/raw/master/QT_Database-master.zip"; filename = fullfile(downloadFolder,"QT_Database-master.zip"); dataFolder = fullfile(downloadFolder,"QT_Database-master"); if ~exist(dataFolder,"dir") fprintf("Downloading Physionet ECG Segmentation data set (72 MB)... ") websave(filename,url); unzip(filename,downloadFolder); fprintf("Done.\n") end Разархивация создает папку
load(fullfile(dataFolder,'QTData.mat'))Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Сегментация Формы волны Использует Глубокое обучение. | Классификация последовательностей к метке, сегментация формы волны |
Синтетический пешеход, автомобиль и обратное рассеяние велосипедиста
| Сгенерируйте синтетического пешехода, автомобиль и набор данных обратного рассеяния велосипедиста с помощью функций помощника Функция помощника Функция помощника
oldpath = addpath(fullfile(matlabroot,'examples','phased','main')); numPed = 1; % Number of pedestrian realizations numBic = 1; % Number of bicyclist realizations numCar = 1; % Number of car realizations [xPedRec,xBicRec,xCarRec,Tsamp] = helperBackScatterSignals(numPed,numBic,numCar); [SPed,T,F] = helperDopplerSignatures(xPedRec,Tsamp); [SBic,~,~] = helperDopplerSignatures(xBicRec,Tsamp); [SCar,~,~] = helperDopplerSignatures(xCarRec,Tsamp); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Классификацию Пешеходов и Велосипедистов Используя Глубокое обучение (Radar Toolbox). Чтобы восстановить путь, используйте path(oldpath); | Классификация последовательностей к метке |
Сгенерированные формы волны
| Сгенерируйте прямоугольный, линейный FM, и фаза закодировала формы волны с помощью функции помощника Функция помощника
oldpath = addpath(fullfile(matlabroot,'examples','phased','main')); [wav, modType] = helperGenerateRadarWaveforms; Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Радар и Коммуникационную Классификацию Форм волны Используя Глубокое обучение (Radar Toolbox). Чтобы восстановить путь, используйте path(oldpath); | Классификация последовательностей к метке |
| Данные | Описание | Задача |
|---|---|---|
HMDB: большая человеческая база данных движения
(Представительный пример) | Набор данных HMBD51 содержит приблизительно 2 Гбайт видеоданных для 7 000 клипов от 51 класса, таких как напиток, запуск и выжимание в упоре. Загрузите и извлеките набор данных HMBD51 из HMDB: большая человеческая база данных движения. Набор данных составляет приблизительно 2 Гбайт. После того, как вы извлекаете файлы RAR, получаете имена файлов и метки видео при помощи функции помощника oldpath = addpath(fullfile(matlabroot,'examples','nnet','main')); dataFolder = fullfile(tempdir,"hmdb51_org"); [files,labels] = hmdb51Files(dataFolder); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Классифицируют Видео Используя Глубокое обучение. Чтобы восстановить путь, используйте path(oldpath); | Видео классификация |
| Данные | Описание | Задача |
|---|---|---|
|
Отчеты фабрики
| Набор данных Отчетов Фабрики является таблицей, содержащей приблизительно 500 отчетов с различными атрибутами включая описание простого текста в переменной Считайте данные об Отчетах Фабрики из файла filename = "factoryReports.csv"; data = readtable(filename,'TextType','string'); textData = data.Description; labels = data.Category; Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Классифицируют текстовые Данные Используя Глубокое обучение. |
Классификация текстов, моделирование темы |
|
Сонеты Шекспира
| Файл Считайте данные о Сонетах Шекспира из файла filename = "sonnets.txt";
textData = fileread(filename);
Сонеты располагаются с отступом двумя пробельными символами и разделяются двумя символами новой строки. Удалите использование добавлений отступа textData = replace(textData," ",""); textData = split(textData,[newline newline]); textData = textData(5:2:end); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, Генерируют текст Используя Глубокое обучение. |
Моделирование темы, текстовая генерация |
|
Метаданные ArXiv
| ArXiv API позволяет вам получать доступ к метаданным научной электронной печати, представленной https://arxiv.org включая абстрактные и предметные области. Для получения дополнительной информации см. https://arxiv.org/help/api. Импортируйте набор кратких обзоров и подписей категорий из математических бумаг с помощью arXiV API. url = "https://export.arxiv.org/oai2?verb=ListRecords" + ... "&set=math" + ... "&metadataPrefix=arXiv"; options = weboptions('Timeout',160); code = webread(url,options); Для примера, показывающего, как проанализировать возвращенный код XML и импортировать больше записей, смотрите, что Классификация Мультитекстов метки Использует Глубокое обучение. |
Классификация текстов, моделирование темы |
|
Книги из проекта Гутенберг
| Можно загрузить много книг с Проекта Гутенберг. Например, загрузите текст с Алисы в Стране чудес Льюиса Кэрролла от https://www.gutenberg.org/files/11/11-h/11-h.htm с помощью url = "https://www.gutenberg.org/files/11/11-h/11-h.htm";
code = webread(url);Код HTML содержит соответствующий текст в tree = htmlTree(code);
selector = "p";
subtrees = findElement(tree,selector);Извлеките текстовые данные из поддеревьев HTML с помощью textData = extractHTMLText(subtrees);
textData(textData == "") = [];Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Пословно текстовую Генерацию Используя Глубокое обучение. |
Моделирование темы, текстовая генерация |
|
Обновления выходных дней
| Файл Извлеките текстовые данные из файла filename = "weekendUpdates.xlsx"; tbl = readtable(filename,'TextType','string'); textData = tbl.TextData; Для примера, показывающего, как обработать эти данные, смотрите, Анализируют Чувство в тексте (Text Analytics Toolbox). |
Анализ мнений |
|
Римские цифры
| Файл CSV Загрузите пары десятичной Римской цифры из файла CSV filename = fullfile("romanNumerals.csv"); options = detectImportOptions(filename, ... 'TextType','string', ... 'ReadVariableNames',false); options.VariableNames = ["Source" "Target"]; options.VariableTypes = ["string" "string"]; data = readtable(filename,options); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Перевод От последовательности к последовательности Использует Внимание. |
Перевод от последовательности к последовательности |
|
Финансовые отчеты
|
Комиссия по ценным бумагам и биржам (SEC) позволяет вам финансовым отчетам доступа через Электронный Сбор данных, Анализ и Извлечение (EDGAR) API. Для получения дополнительной информации см. https://www.sec.gov/os/accessing-edgar-data. Чтобы загрузить эти данные, используйте функциональный year = 2019; qtr = 4; maxLength = 2e6; textData = financeReports(year,qtr,maxLength); Для примера, показывающего, как обработать эти данные, смотрите, Генерируют Зависящий от домена Словарь Чувства (Text Analytics Toolbox). |
Анализ мнений |
| Данные | Описание | Задача |
|---|---|---|
Речевые команды
| Речевой набор данных Команд состоит приблизительно из 65 000 звуковых файлов, помеченных 1 из 12 классов включая да, нет, на, и прочь, а также классов, соответствующих неизвестным командам и фоновому шуму [25]. Загрузите и извлеките Речевой набор данных Команд из https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz. Набор данных составляет приблизительно 1,4 Гбайт. Установите dataFolder = tempdir; ads = audioDatastore(dataFolder, ... 'IncludeSubfolders',true, ... 'FileExtensions','.wav', ... 'LabelSource','foldernames'); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Распознание речевых команд с использованием глубокого обучения. | Аудио классификация, распознавание речи |
Mozilla общая речь
| Набор данных Mozilla Common Voice состоит из аудиозаписей речи и соответствующих текстовых файлов. Данные также включают демографические метаданные, такие как возраст и диакритический знак. Загрузите и извлеките набор данных набора данных Mozilla Common Voice из https://voice.mozilla.org/. Набор данных является открытым набором данных, что означает, что это может расти в зависимости от времени. По состоянию на октябрь 2019 набор данных составляет приблизительно 28 Гбайт. Установите dataFolder = tempdir;
ads = audioDatastore(fullfile(dataFolder,"clips")); | Аудио классификация, распознавание речи. |
Свободный разговорный набор данных цифры
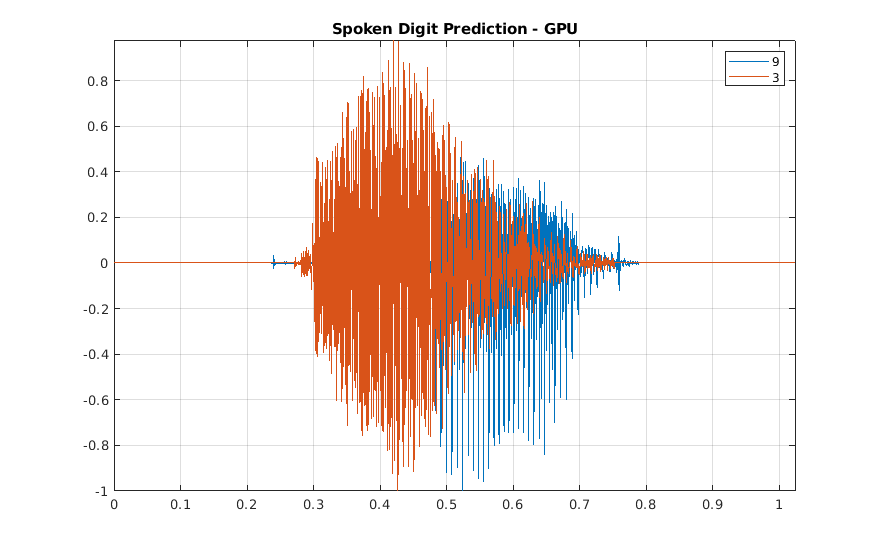
| Свободный Разговорный Набор данных Цифры, с 29 января 2019, состоит из 2 000 записей английских цифр 0 через 9 полученных от четырех докладчиков. Два из докладчиков в этой версии являются носителями американского варианта английского языка, и два докладчика являются ненативными докладчиками английского языка с французским Бельгии и немецким диакритическим знаком соответственно. Данные производятся на уровне 8 000 Гц. Загрузите записи Свободного разговорного набора данных цифры (FSDD) с https://github.com/Jakobovski/free-spoken-digit-dataset. Установите dataFolder = fullfile(tempdir,'free-spoken-digit-dataset','recordings'); ads = audioDatastore(dataFolder); Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Разговорное Распознавание Цифры с Рассеиванием Вейвлета и Глубоким обучением. | Аудио классификация, распознавание речи. |
Берлинская база данных эмоциональной речи
| Берлинская База данных Эмоциональной Речи содержит 535 произнесения, на котором говорят 10 агентов, предназначенных, чтобы передать одну из следующих эмоций: гнев, скука, отвращение, беспокойство/страх, счастье, печаль, или нейтральный [26]. Эмоции являются независимым текстом. Имена файлов являются кодами, указывающими на ID динамика, текст, на котором говорят, эмоция и версия. Веб-сайт содержит ключ для интерпретации кода и дополнительной информации о динамиках, таких как возраст. Загрузите Берлинскую Базу данных Эмоциональной Речи от http://emodb.bilderbar.info/index-1280.html. Набор данных составляет приблизительно 40 Мбайт. Установите dataFolder = tempdir;
ads = audioDatastore(fullfile(dataFolder,"wav"));
Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите Речевое Распознавание Эмоции. | Аудио классификация, распознавание речи. |
TUT акустические сцены 2017
| TUT Акустические Сцены 2 017 наборов данных состоит из 10-секундных аудио сегментов от 15 акустических сцен включая шину, автомобиль и библиотеку. Загрузите и извлеките TUT Акустические Сцены 2 017 наборов данных от TUT Акустические сцены 2017, набор данных Development и TUT Акустические сцены 2017, набор данных Evaluation [27]. Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Акустическое Распознавание Сцены Использует Последний Fusion. | Акустическая классификация сцен |
| Данные | Описание | Задача |
|---|---|---|
Данные о лидаре WPI | Данные о Лидаре WPI собраны с помощью Изгнания датчик OS1. Это содержит организованные сканы облака точек лидара магистральных сцен и соответствующих меток основной истины для объектов автомобиля и грузовика. Набор данных имеет 1 617 облаков точек, сохраненных как Выполните этот код, чтобы загрузить набор данных. url = 'https://www.mathworks.com/supportfiles/lidar/data/WPI_LidarData.tar.gz'; outputFolder = fullfile(tempdir,'WPI'); lidarDataTarFile = fullfile(outputFolder,'WPI_LidarData.tar.gz'); if ~exist(lidarDataTarFile, 'file') mkdir(outputFolder); disp('Downloading WPI Lidar driving data (760 MB)...'); websave(lidarDataTarFile, url); untar(lidarDataTarFile,outputFolder); end lidarData = load(fullfile(outputFolder, 'WPI_LidarData.mat')); WPI_LidarData папка. Если вы делаете так, изменяете outputFolder переменная в коде к местоположению загруженного файла.Для примера, показывающего, как обработать эти данные для глубокого обучения, смотрите, что Семантическая Сегментация Облака точек Лидара Использует Нейронную сеть для глубокого обучения PointSeg. | Семантическая сегментация |
Данные PandaSet | PandaSet содержит 2 560 организованных сканов облака точек лидара различных городских сцен, полученных с помощью датчика Pandar 64. Набор данных обеспечивает метки семантической сегментации для 12 различных классов и 3-D информацию об ограничительной рамке для трех классов, которые являются автомобилем, грузовиком и пешеходом. Размер набора данных составляет 5,2 Гбайт. Выполните этот код, чтобы загрузить набор данных. url = 'https://ssd.mathworks.com/supportfiles/lidar/data/Pandaset_LidarData.tar.gz'; outputFolder = fullfile(tempdir,'Pandaset'); lidarDataTarFile = fullfile(outputFolder,'Pandaset_LidarData.tar.gz'); if ~exist(lidarDataTarFile, 'file') mkdir(outputFolder); disp('Downloading Pandaset Lidar driving data (5.2 GB)...'); websave(lidarDataTarFile, url); untar(lidarDataTarFile,outputFolder); end lidarData = fullfile(outputFolder,'Lidar'); labelsFolder = fullfile(outputFolder,'semanticLabels'); В зависимости от вашего интернет-соединения может занять время процесс загрузки. В качестве альтернативы можно загрузить набор данных на локальный диск от веб-браузера с помощью URL, и затем извлечь Для примеров, показывающих, как обработать эти данные для глубокого обучения, смотрите, что Семантическая Сегментация Облака точек Лидара Использует Нейронную сеть для глубокого обучения SqueezeSegV2 и Лидар 3-D Обнаружение объектов Используя Глубокое обучение PointPillars. | Обнаружение объектов, Семантическая сегментация |
[1] Озеро, Бренден М., Руслан Салахутдинов и Джошуа Б. Тененбаум. “Концепция человеческого уровня, Учащаяся посредством Вероятностной Индукции Программы”. Наука 350, № 6266 (11 декабря 2015): 1332–38. https://doi.org/10.1126/science.aab3050.
[2] Команда TensorFlow. "Цветы" https://www.tensorflow.org/datasets/catalog/tf_flowers.
[3] Kat, Тюльпаны, изображение, https://www.flickr.com/photos/swimparallel/3455026124. Лицензия Creative Commons (CC BY).
[4] Роб Бертолф, Подсолнечники, изображение, https://www.flickr.com/photos/robbertholf/20777358950. Creative Commons 2.0 Типовая Лицензия.
[5] Parvin, Розы, изображение, https://www.flickr.com/photos/55948751@N00. Creative Commons 2.0 Типовая Лицензия.
[6] Джон Хэслэм, Одуванчики, изображение, https://www.flickr.com/photos/foxypar4/645330051. Creative Commons 2.0 Типовая Лицензия.
[7] Krizhevsky, Алекс. "Изучая Несколько Слоев Функций от Крошечных Изображений". Тезис магистра наук, Университет Торонто, 2009. https://www.cs.toronto.edu / % 7Ekriz/learning-features-2009-TR.pdf.
[8] Brostow, Габриэль Дж., Жюльен Фокер и Роберто Сиполья. “Семантические Классы объектов в Видео: База данных Основной истины Высокой четкости”. Буквы Распознавания образов 30, № 2 (январь 2009): 88–97. https://doi.org/10.1016/j.patrec.2008.04.005.
[9] Kemker, Рональд, Карл Сэльвэггио и Кристофер Кэнэн. “Многоспектральный Набор данных с высоким разрешением для Семантической Сегментации”. ArXiv:1703.01918 [Cs], 6 марта 2017. https://arxiv.org/abs/1703.01918.
[10] Isensee, Фабиан, Филипп Кикинджередер, Вольфганг Вик, Мартин Бендсзус и Клаус Х. Майер-Хейн. “Сегментация Опухоли головного мозга и Предсказание Выживания Radiomics: Вклад в проблему BRATS 2017”. В Brainlesion: Глиома, Рассеянный склероз, Штриховые и Травматические повреждения головного мозга, отредактированные Алессандро Крими, Спиридоном Бакасом, Хьюго Киджфом, Бьорном Мензом и Маурисио Рейесом, 10670: 287–97. Хан, Швейцария: Springer International Publishing, 2018. https://doi.org/10.1007/978-3-319-75238-9_25.
[11] Ehteshami Bejnordi, Babak, Митко Вета, Пол Джоханнс ван Дист, Брэм ван Джиннекен, Нико Карссемейджер, Герт Литьенс, Йерун А. В. М. ван дер Лак, и др. “Диагностическая Оценка Алгоритмов Глубокого обучения для Обнаружения Метастаз Лимфатического узла в Женщинах С Раком молочной железы”. JAMA 318, № 22 (12 декабря 2017): 2199. https://doi.org/10.1001/jama.2017.14585.
[12] МакКалоу, C.H., Чен, B., Холмс, D., III, Дуань, X., Ю, Z., Ю, L., Лэн, S., Флетчер, J. (2020). Данные из Низких Данных об Изображении и Проекции CT Дозы [Набор данных]. Архив Обработки изображений Рака. https://doi.org/10.7937/9npb-2637.
[13] Предоставления EB017095 и EB017185 (Синтия МакКалоу, PI) от национального института биомедицинской обработки изображений и биоинженерии.
[14] Grubinger, Майкл, Пол Кло, Хеннинг Мюллер и Томас Дезелэерс. "Сравнительный тест IAPR TC-12: Новый Ресурс Оценки для Визуальных Информационных систем". Продолжения ресурсов OntoImage 2006 Языка Для Извлечения Изображений На основе содержимого. Генуя, Италия. Издание 5, май 2006, p. 10.
[15] Игнатов, Андрей, Люк Ван Гул и Рэду Тимофт. “Заменяя Мобильную Камеру ISP на Одну Модель Глубокого обучения”. ArXiv:2002.05509 [Cs, Eess], 13 февраля 2020. https://arxiv.org/abs/2002.05509. Веб-сайт проекта.
[16] Чэнь, Чэнь, Цифэн Чэнь, Цзя Сюй и Владлен Кольтун. “Учась Видеть в темноте”. ArXiv:1805.01934 [Cs], 4 мая 2018. https://arxiv.org/abs/1805.01934.
[17] LIVE: Лаборатория для Изображения и Видео Разработки. https://live.ece.utexas.edu/research/ChallengeDB/index.html.
[18] Лизнерский, Филипп, Лукаш Руфф, Роберт А. Вэндермеулен, Билли Джо Фрэнкс, Мариус Клофт и Клаус-Роберт Мюллер. "Объяснимая Глубокая Классификация Одного класса". ArXiv:2007.01760 [Cs, Статистика], 18 марта 2021. http://arxiv.org/abs/2007.01760.
[19] Kudo, Mineichi, Юн Тояма и Масару Шимбо. "Многомерная Классификация Кривых Используя Прохождение через области". Буквы Распознавания образов 20, № 11-13 (ноябрь 1999): 1103–11. https://doi.org/10.1016/S0167-8655 (99) 00077-X.
[20] Kudo, Mineichi, Юн Тояма и Масару Шимбо. Японский Набор данных Гласных. Распределенный Репозиторием Машинного обучения UCI. https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
[21] Saxena, Abhinav, Кай Гоебель. "Турбовентиляторный Набор Данных моделирования Ухудшения Engine". НАСА Репозиторий данных Предзнаменований Эймса https://ti.arc.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/, Исследовательский центр Эймса, Поле Moffett, Приблизительно
[22] Rieth, Кори А., Бен Д. Амсель, Рэнди Трэн и Майя Б. Кук. "Дополнительные Данные моделирования Процесса Теннесси Истмэна для Оценки Обнаружения Аномалии". Гарвард Dataverse, Версия 1, 2017. https://doi.org/10.7910/DVN/6C3JR1.
[23] Голдбергер, Ари Л., Луис А. Н. Амараль, Леон Гласс, Джеффри М. Гаусдорф, Plamen Ch. Иванов, Роджер Г. Марк, Джозеф Э. Митус, Джордж Б. Муди, Чанг-Канг Пенг и Х. Юджин Стэнли. "PhysioBank, PhysioToolkit и PhysioNet: Компоненты Нового Ресурса Исследования для Комплексных Физиологических Сигналов". Циркуляция 101, № 23, 2000, стр e215–e220. https://circ.ahajournals.org/content/101/23/e215.full.
[24] Laguna, Пабло, Роджер Г. Марк, Ари Л. Голдбергер и Джордж Б. Муди. "База данных для Оценки Алгоритмов для Измерения QT и Других Интервалов Формы волны в ECG". Компьютеры в Кардиологии 24, 1997, стр 673–676.
[25] Начальник, Пит. "Речевые Команды: общедоступный набор данных для распознавания речи однословного", 2017. Доступный от http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz. Авторское право Google 2017. Речевой Набор данных Команд лицензируется при Приписывании Creative Commons 4,0 лицензии, доступные здесь: https://creativecommons.org/licenses/by/4.0/legalcode.
[26] Burkhardt, Феликс, Астрид Пэешк, Мелисса А. Рольфес, Уолтер Ф. Сендлмайер и Бенджамин Вайс. "База данных немецкой эмоциональной речи". Продолжения межречи 2005. Лиссабон, Португалия: международная речевая коммуникационная ассоциация, 2005.
[27] Mesaros, Annamaria, Тони Хейттола и Туомас Виртэнен. "Акустическая классификация сцен: обзор DCASE 2017 бросает вызов записям". На 2 018 16-х Международных семинарах на Акустическом Улучшении Сигнала (IWAENC), стр 411-415. IEEE, 2018.
[28] Hesai и Scale. PandaSet. https://scale.com/open-datasets/pandaset
trainingOptions | trainNetwork