Можно взять предварительно обученную сеть классификации изображений, которая уже училась извлекать мощные и информативные функции из естественных изображений и использовать его в качестве начальной точки, чтобы изучить новую задачу. Большинство предварительно обученных сетей обучено на подмножестве базы данных ImageNet [1], который используется в ImageNet крупномасштабной визуальной проблеме распознавания (ILSVRC) [2]. Эти сети были обучены больше чем на миллионе изображений и могут классифицировать изображения в 1 000 категорий объектов, таких как клавиатура, кофейная кружка, карандаш и многие животные. Используя предварительно обученную сеть с передачей обучения обычно намного быстрее и легче, чем обучение сети с нуля.
Можно использовать, ранее обучил нейронные сети для следующих задач:
| Цель | Описание |
|---|---|
| Классификация | Примените предварительно обученные сети непосредственно к проблемам классификации. Чтобы классифицировать новое изображение, использовать |
| Извлечение признаков | Используйте предварительно обученную сеть в качестве экстрактора функции при помощи активаций слоя как функции. Можно использовать эти активации в качестве функций, чтобы обучить другую модель машинного обучения, такую как машина опорных векторов (SVM). Для получения дополнительной информации смотрите Извлечение признаков. Для примера смотрите, что Функции Извлечения Изображений Используют Предварительно обученную сеть. |
| Передача обучения | Возьмите слои из сети, обученной на большом наборе данных и подстройке на новом наборе данных. Для получения дополнительной информации смотрите Передачу обучения. Для простого примера смотрите Начало работы с Передачей обучения. Чтобы попробовать больше предварительно обученных сетей, смотрите, Обучают Нейронную сеть для глубокого обучения Классифицировать Новые Изображения. |
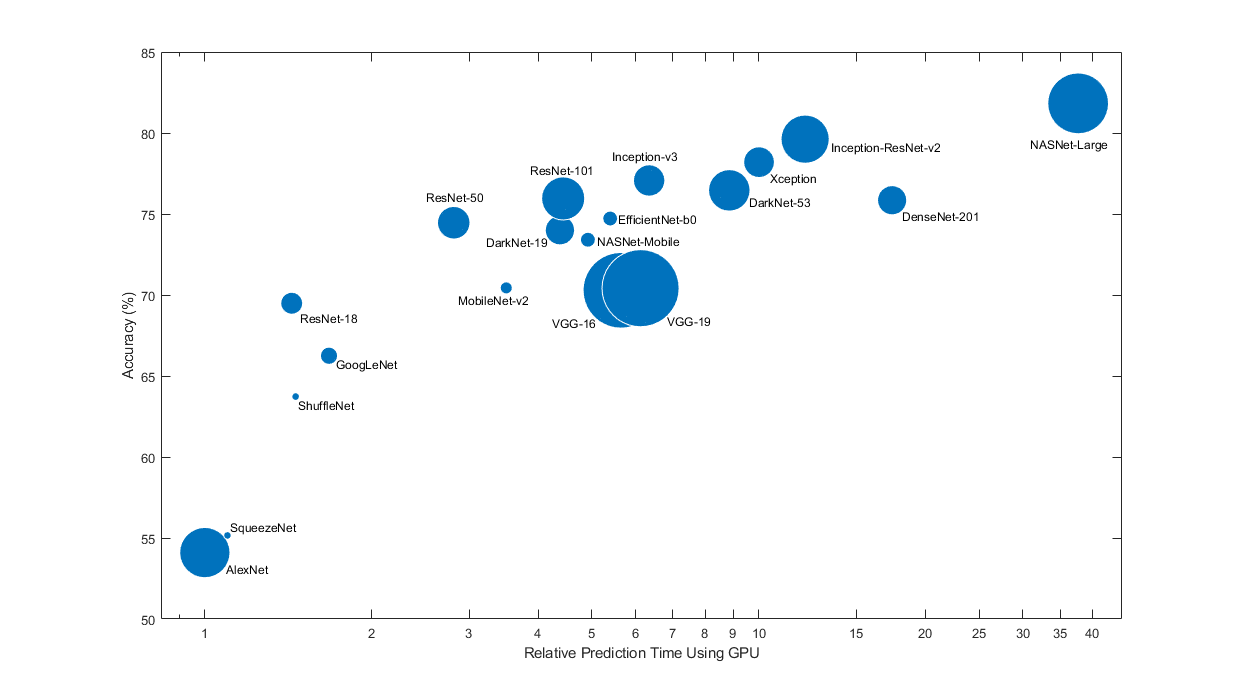
Предварительно обученные сети имеют различные характеристики, которые имеют значение при выборе сети, чтобы примениться проблеме. Самые важные характеристики являются сетевой точностью, скоростью и размером. Выбор сети обычно является компромиссом между этими характеристиками. Используйте график ниже, чтобы сравнить точность валидации ImageNet со временем, требуемым сделать предсказание с помощью сети.
Совет
Чтобы начать с передачей обучения, попытайтесь выбрать одну из более быстрых сетей, таких как SqueezeNet или GoogLeNet. Можно затем выполнить итерации быстро и испытать различные настройки, такие как шаги предварительной обработки данных и опции обучения. Если у вас есть чувство, которого настройки работают хорошо, пробуют более точную сеть, такую как Inception-v3 или ResNet и видят, улучшает ли это ваши результаты.
Примечание
График выше только показывает индикацию относительно относительных скоростей различных сетей. Точное предсказание и учебные времена итерации зависит от оборудования и мини-обрабатывает в пакетном режиме размер, который вы используете.
Хорошая сеть имеет высокую точность и быстра. График отображает точность классификации по сравнению со временем предсказания при использовании современного графического процессора (NVIDIA® Tesla® P100) и мини-пакетный размер 128. Время предсказания измеряется относительно самой быстрой сети. Область каждого маркера пропорциональна размеру сети на диске.
Точность классификации на наборе валидации ImageNet является наиболее распространенным способом измерить точность сетей, обученных на ImageNet. Сети, которые точны на ImageNet, также часто точны, когда вы применяете их к другим естественным наборам данных изображения с помощью передачи обучения или извлечения признаков. Это обобщение возможно, потому что сети учились извлекать мощные и информативные функции из естественных изображений, которые делают вывод к другим подобным наборам данных. Однако высокая точность на ImageNet не всегда передает непосредственно другим задачам, таким образом, это - хорошая идея попробовать несколько сетей.
Если вы хотите выполнить предсказание с помощью ограниченного оборудования или распределить сети по Интернету, то также рассматривают размер сети на диске и в памяти.
Существует несколько способов вычислить точность классификации на набор валидации ImageNet, и другие источники используют различные методы. Иногда ансамбль многоуровневых моделей используется, и иногда каждое изображение оценено многократно с помощью нескольких обрезок. Иногда лучшие 5 точности вместо стандарта (лучший 1) точность заключается в кавычки. Из-за этих различий часто не возможно непосредственно сравнить точность из других источников. Точность предварительно обученных сетей в Deep Learning Toolbox™ является стандартной (лучший 1) точность с помощью одной модели и одной центральной обрезки изображений.
Чтобы загрузить сеть SqueezeNet, ввести squeezenet в командной строке.
net = squeezenet;
Для других сетей используйте функции такой как googlenet заставить ссылки загружать предварительно обученные сети с Add-On Explorer.
В следующей таблице перечислены доступные предварительно обученные сети, обученные на ImageNet и некоторые их свойства. Сетевая глубина задана как наибольшее число сверточных последовательных или полносвязные слоя на пути от входного слоя до выходного слоя. Входные параметры ко всем сетям являются изображениями RGB.
| Сеть | Глубина | Размер | Параметры (Миллионы) | Отобразите входной размер |
|---|---|---|---|---|
squeezenet | 18 | 5.2 МБАЙТ | 1.24 | 227 227 |
googlenet | 22 | 27 Мбайт | 7.0 | 224 224 |
inceptionv3 | 48 | 89 Мбайт | 23.9 | 299 299 |
densenet201 | 201 | 77 Мбайт | 20.0 | 224 224 |
mobilenetv2 | 53 | 13 Мбайт | 3.5 | 224 224 |
resnet18 | 18 | 44 Мбайта | 11.7 | 224 224 |
resnet50 | 50 | 96 Мбайт | 25.6 | 224 224 |
resnet101 | 101 | 167 Мбайт | 44.6 | 224 224 |
xception | 71 | 85 Мбайт | 22.9 | 299 299 |
inceptionresnetv2 | 164 | 209 Мбайт | 55.9 | 299 299 |
shufflenet | 50 | 5.4 МБАЙТ | 1.4 | 224 224 |
nasnetmobile | * | 20 Мбайт | 5.3 | 224 224 |
nasnetlarge | * | 332 Мбайта | 88.9 | 331 331 |
darknet19 | 19 | 78 Мбайт | 20.8 | 256 256 |
darknet53 | 53 | 155 Мбайт | 41.6 | 256 256 |
efficientnetb0 | 82 | 20 Мбайт | 5.3 | 224 224 |
alexnet | 8 | 227 Мбайт | 61.0 | 227 227 |
vgg16 | 16 | 515 Мбайт | 138 | 224 224 |
vgg19 | 19 | 535 Мбайт | 144 | 224 224 |
*Сети NASNet-Mobile и NASNet-Large не состоят из линейной последовательности модулей.
Стандартная сеть GoogLeNet обучена на наборе данных ImageNet, но можно также загрузить сеть, обученную на [3]
[4] набора данных Places365. Сеть, обученная на Places365, классифицирует изображения в 365 различных категорий места, таких как поле, парк, взлетно-посадочная полоса и лобби. Чтобы загрузить предварительно обученную сеть GoogLeNet, обученную на наборе данных Places365, используйте googlenet('Weights','places365'). При использовании обучение с переносом, чтобы выполнить новую задачу, наиболее распространенный подход должен использовать сети, предварительно обученные на ImageNet. Если новая задача похожа на классификацию сцен, то использование сети, обученной на Places365, могло дать более высокую точность.
Можно загрузить и визуализировать предварительно обученные сети с помощью Deep Network Designer.
deepNetworkDesigner(squeezenet)
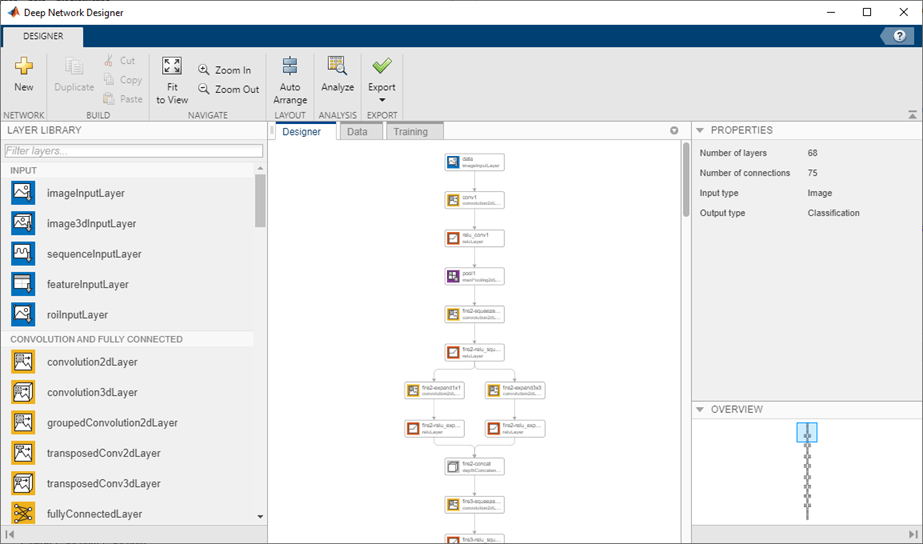
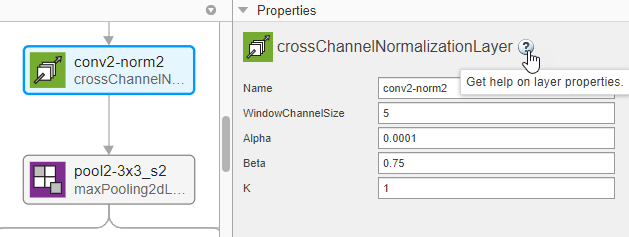
Чтобы просмотреть и отредактировать свойства слоя, выберите слой. Кликните по значку справки рядом с именем слоя для получения информации о свойствах слоя.
Исследуйте другие предварительно обученные сети в Deep Network Designer путем нажатия на New.
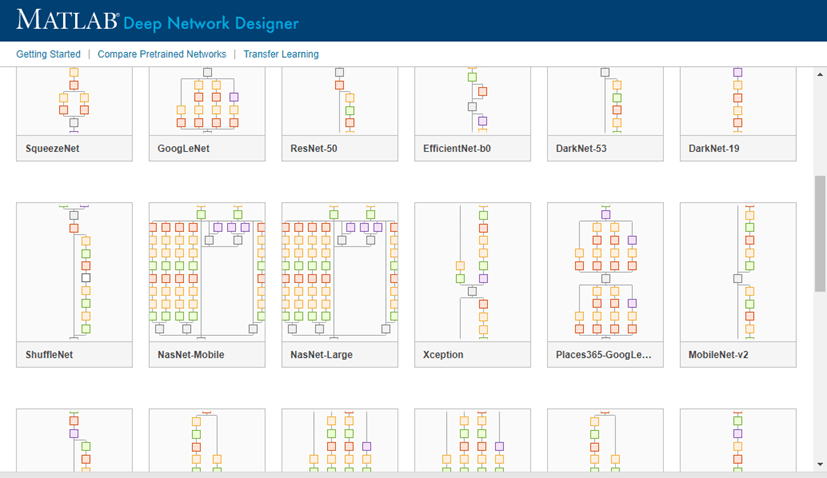
Если необходимо загрузить сеть, сделать паузу в желаемой сети и нажать Install, чтобы открыть Add-On Explorer.
Извлечение признаков является легким и быстрым способом использовать степень глубокого обучения, не инвестируя время и усилие в обучение полной сети. Поскольку это только требует одной передачи по учебным изображениям, особенно полезно, если у вас нет графического процессора. Вы извлекаете изученные функции изображений с помощью предварительно обученной сети, и затем используете те функции, чтобы обучить классификатор, такой как использование машины опорных векторов fitcsvm (Statistics and Machine Learning Toolbox).
Попробуйте извлечение признаков, когда ваш новый набор данных очень будет мал. Поскольку вы только обучаете простой классификатор на извлеченных функциях, обучение быстро. Также маловероятно, что подстройка более глубоких слоев сети улучшает точность, поскольку существуют небольшие данные, чтобы извлечь уроки из.
Если ваши данные будут очень похожи на исходные данные, то более определенные функции, извлеченные глубже в сети, вероятно, будут полезны для новой задачи.
Если ваши данные очень отличаются от исходных данных, то функции, извлеченные глубже в сетевой силе, менее полезны для вашей задачи. Попробуйте обучение итоговый классификатор на более общих функциях, извлеченных из более раннего слоя сети. Если новый набор данных является большим, то можно также попытаться обучить сеть с нуля.
ResNets часто являются хорошими экстракторами функции. Для примера, показывающего, как использовать предварительно обученную сеть для извлечения признаков, смотрите, что Функции Извлечения Изображений Используют Предварительно обученную сеть.
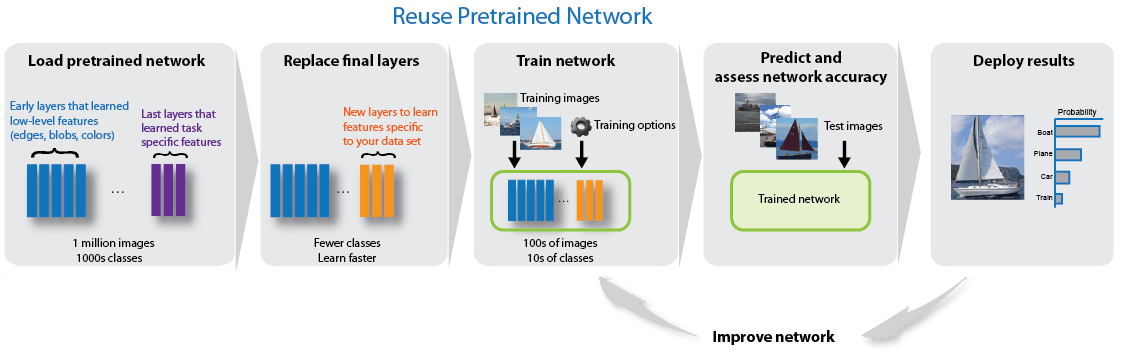
Можно подстроить более глубокие слои в сети путем обучения сети на новом наборе данных с предварительно обученной сетью как начальная точка. Подстройка сети с передачей обучения часто быстрее и легче, чем построение и обучение новой сети. Сеть уже изучила богатый набор функций изображений, но когда вы подстраиваете сеть, это может изучить функции, характерные для вашего нового набора данных. Если у вас есть очень большой набор данных, то передача обучения не может быть быстрее, чем обучение с нуля.
Совет
Подстройка сети часто дает самую высокую точность. Для очень небольших наборов данных (меньше, чем приблизительно 20 изображений в классе), попробуйте извлечение признаков вместо этого.
Подстройка сети медленнее и требует большего усилия, чем простое извлечение признаков, но поскольку сеть может учиться извлекать различный набор функций, итоговая сеть часто более точна. Подстройка обычно работает лучше, чем извлечение признаков, пока новый набор данных очень не мал, потому что затем сеть имеет данные, чтобы узнать о новых возможностях из. Для примеров, показывающих, как использовать обучение с переносом, смотрите Передачу обучения с Deep Network Designer и Обучите Нейронную сеть для глубокого обучения Классифицировать Новые Изображения.
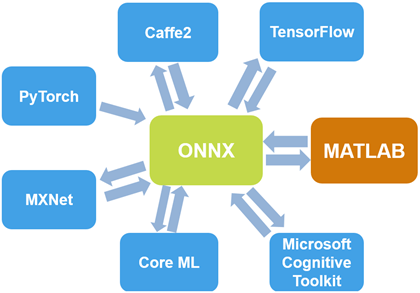
Можно импортировать сети и сетевые архитектуры из TensorFlow®- Keras, Caffe и формат модели ONNX™ (Open Neural Network Exchange). Можно также экспортировать, обучил нейронные сети к формату модели ONNX.
Импортируйте предварительно обученные сети из TensorFlow-Keras при помощи importKerasNetwork. Можно импортировать сеть и веса или от того же HDF5 (.h5) файл или разделить HDF5 и JSON (.json) файлы. Для получения дополнительной информации смотрите importKerasNetwork.
Импортируйте сетевые архитектуры из TensorFlow-Keras при помощи importKerasLayers. Можно импортировать сетевую архитектуру, или с или без весов. Можно импортировать сетевую архитектуру и веса или от того же HDF5 (.h5) файл или разделить HDF5 и JSON (.json) файлы. Для получения дополнительной информации смотрите importKerasLayers.
Импортируйте предварительно обученные сети из Caffe при помощи importCaffeNetwork функция. Существует много предварительно обученных сетей, доступных в Зоопарке Модели Caffe [5]. Загрузите желаемый .prototxt и .caffemodel файлы и использование importCaffeNetwork импортировать предварительно обученную сеть в MATLAB®. Для получения дополнительной информации смотрите importCaffeNetwork.
Можно импортировать сетевые архитектуры сетей Caffe. Загрузите желаемый .prototxt файл и использование importCaffeLayers импортировать слоя сети в MATLAB. Для получения дополнительной информации смотрите importCaffeLayers.
При помощи ONNX как промежуточный формат можно взаимодействовать с другими средами глубокого обучения, которые поддерживают экспорт модели ONNX или импорт, такой как TensorFlow, PyTorch, Caffe2, Microsoft® Познавательный инструментарий (CNTK), базовый ML и Apache MXNet™.
Экспортируйте обученную сеть Deep Learning Toolbox в формат модели ONNX при помощи exportONNXNetwork функция. Можно затем импортировать модель ONNX к другим средам глубокого обучения, которые поддерживают импорт модели ONXX.
Импортируйте предварительно обученные сети из использования ONNX importONNXNetwork и импортируйте сетевые архитектуры с или без использования весов importONNXLayers.
Используйте предварительно обученные сети для аудио и речевых приложений обработки при помощи Deep Learning Toolbox вместе с Audio Toolbox™.
Audio Toolbox обеспечивает предварительно обученные сети VGGish и YAMNet. Используйте vggish (Audio Toolbox) и yamnet (Audio Toolbox) функционирует, чтобы взаимодействовать непосредственно с предварительно обученными сетями. classifySound Функция (Audio Toolbox) выполняет требуемую предварительную обработку и постобработку для YAMNet так, чтобы можно было определить местоположение и классифицировать звуки в одну из 521 категории. Можно исследовать онтологию YAMNet с помощью yamnetGraph (Audio Toolbox) функция. vggishFeatures Функция (Audio Toolbox) выполняет необходимую предварительную обработку и постобработку для VGGish так, чтобы можно было извлечь вложения функции, чтобы ввести к системам глубокого обучения и машинному обучению. Для получения дополнительной информации об использовании глубокого обучения для аудиоприложений смотрите Введение в Глубокое обучение для Аудиоприложений (Audio Toolbox).
Используйте VGGish и YAMNet, чтобы использовать обучение с переносом и извлечение признаков. Например, смотрите Передачу обучения с Предварительно обученными Аудио Сетями (Audio Toolbox).
Чтобы найти последние предварительно обученные модели и примеры, смотрите Глубокое обучение MATLAB (GitHub).
Например:
Для моделей трансформатора, таких как GPT-2, BERT и FinBERT, видят Модели Трансформатора для MATLAB GitHub® репозиторий.
Для предварительно обученных моделей обнаружения объектов YOLO-v4, таких как YOLOv4-кокос и YOLOv4-tiny-coco, смотрите Предварительно обученную Сеть YOLO-v4 для Обнаружения объектов репозиторий GitHub.
[1] ImageNet. http://www.image-net.org
[2] Russakovsky, O., Дэн, J., Су, H., и др. “Крупный масштаб ImageNet Визуальная проблема Распознавания”. Международный журнал Компьютерного зрения (IJCV). Vol 115, Выпуск 3, 2015, стр 211–252
[3] Чжоу, Bolei, Aditya Khosla, Агата Лапедриса, Антонио Торрэлба и Од Олива. "Места: база данных изображений для глубокого понимания сцены". arXiv предварительно распечатывают arXiv:1610.02055 (2016).
[4] Места. http://places2. csail.mit.edu /
[5] Зоопарк Модели Caffe. http://caffe.berkeleyvision.org/model_zoo.html
alexnet | googlenet | inceptionv3 | densenet201 | darknet19 | darknet53 | resnet18 | resnet50 | resnet101 | vgg16 | vgg19 | shufflenet | nasnetmobile | nasnetlarge | mobilenetv2 | xception | inceptionresnetv2 | squeezenet | importCaffeNetwork | importCaffeLayers | importKerasLayers | importKerasNetwork | exportONNXNetwork | importONNXLayers | importONNXNetwork | Deep Network Designer
