После выполнения оптимизации Output узел появляется в дереве оптимизации, а также в представлениях Optimization Output. CAGE предоставляет инструменты для анализа результатов с помощью этих представлений.
CAGE автоматически выбирает успешные решения для оптимизации и выделяет неудачные решения для изучения. Эти параметры отображаются в значках и флажках рядом со столбцом Выполнить (Run) в таблице Результаты оптимизации (Optimization Results). Можно изменить выбор с помощью флажков для каждого решения или щелкнуть правой кнопкой мыши, чтобы изменить приемлемый статус решений в графических представлениях.
В этой таблице представлены способы использования выбранных решений.
| Использовать | Посмотрите |
|---|---|
Заполнение таблиц результатами оптимизации. | Заполнение таблиц из результатов оптимизации |
Экспорт решений в набор данных. | Экспорт в набор данных |
Импорт решений в другие начальные значения оптимизации. | Импорт из выходных данных |
CAGE указывает состояние принятия.
| Статус | Описание |
|---|---|
|
| CAGE автоматически устанавливает флажки Принять для решений, в которых флаг выхода из алгоритма указывает на успех (> 0). В этих решениях рядом с флажком отображается зеленый квадратный значок. Обычно ограничения выполняются в пределах допуска . |
|
| Решения с красным значком скругления указывают на то, что флаг выхода алгоритма не сообщает об успехе (< 0). Некоторые ограничения могут не выполняться . |
|
| Решения с оранжевым треугольным значком указывают, что флаг выхода алгоритма равен нулю. Некоторые ограничения могут не выполняться. Нулевой флаг выхода указывает, что алгоритм вышел из строя из-за превышения вычислительных пределов (например, у алгоритма закончились итерации или оценки функций). Вы можете принять эти решения или попытаться изменить допуски и оптимизировать снова. |
|
| Решения, в которых вы изменили статус флажка, показывают звездочку. |
|
| CAGE показывает нарушенные ограничения в виде желтых ячеек с перекрестными значками в таблице. Можно управлять значением, используемым для этого выделения, выбрав меню «Вид» > «Редактировать допуск ограничения». В зеленых решениях о статусе принятия можно выделить ограничения. Алгоритм может сообщать об успехе, если ограничения выполняются в пределах допуска для масштабированных значений. При отображении зависимости допуск применяется к необработанным значениям, и можно также отредактировать этот допуск, чтобы помочь в анализе результатов. Если просматриваются ограничения с несколькими значениями и для вида задано значение |
Можно просмотреть флаг вывода алгоритма во всплывающей подсказке, наведя указатель мыши на каждый цветной значок статуса принятия, или щелкнуть, чтобы выбрать решение, а затем просмотреть алгоритм. Exit flag, Exit messageи другие сведения в таблице Информация о решении (Solution Information).
Многие пользователи используют точечную оптимизацию, чтобы найти хорошие начальные значения для суммарной оптимизации. Чтобы сделать этот рабочий процесс более простым и быстрым, можно использовать утилиту для создания суммарной оптимизации на основе результатов оптимизации точек.
В узле вывода оптимизации точек выберите Решение > Создать оптимизацию суммы.
CAGE создает оптимизацию (называется Sum_). Оптимизация имеет следующие характеристики:myOptimizationName
Цель соответствует исходной оптимизации, но преобразована в сумму цели.
Новая оптимизация имеет те же ограничения, что и исходная оптимизация. При необходимости отредактируйте или добавьте их, как обычно.
Исходные фиксированные и свободные переменные преобразуются в оптимизацию суммы (один прогон с несколькими значениями).
Новая оптимизация использует только принятые решения из исходного вывода оптимизации (все прогоны с установленным флажком Принять (Accept)).
Поэтому количество принятых решений в исходной оптимизации определяет количество значений в прогоне суммарной оптимизации.
Исходные значения свободных переменных и фиксированные значения переменных заполняются из оптимальных результатов (только принятые решения).
Фиксированные переменные имеют столбец Веса (Weights), в котором для каждого значения установлено значение 1.
При повторном запуске оптимизаций точек, имеющих связанные оптимизации суммы, Toolbox™ Калибровка на основе модели (Model-Based Calibration) может обновить и повторно запустить оптимизацию суммы с результатами оптимизации точек. Панель инструментов калибровки на основе модели использует существующие ограничения оптимизации суммы при повторном выполнении оптимизации. Ранее панель инструментов калибровки на основе модели создавала оптимизацию суммы.
Выходные результаты оптимизации можно экспортировать в новые или существующие наборы данных.
Для экспорта в набор данных:
Выберите Решение > Экспорт в набор данных или используйте кнопку панели инструментов. Появится диалоговое окно «Экспорт в набор данных».
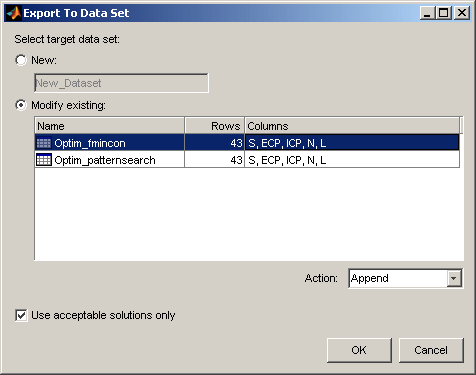
При экспорте в новый набор данных (по умолчанию) можно изменить имя в поле редактирования.
При необходимости перезаписи или добавления к существующему набору данных:
Нажмите кнопку опции Изменить существующий.
Выберите требуемый набор данных в списке.
Выберите из списка «Действие»:
Append добавляет данные в выбранный набор данных.
Overwrite заменяет все данные в наборе данных новыми данными.
По умолчанию установлен флажок Использовать только приемлемые решения. Результаты оптимизации с установленными флажками Принять (Accept) экспортируются. Снимите флажок Использовать только приемлемые решения, если требуется экспортировать все результаты оптимизации.
Нажмите кнопку ОК, и данные будут экспортированы в набор данных.
В этой таблице представлены правила экспорта.
Правила экспорта | По возможности экспортируются все фиксированные и свободные переменные. |
Модели не экспортируются в набор данных. Если требуется вычислить модель по значениям переменных, добавьте модель в набор данных в представлении «Наборы данных». | |
При добавлении правила аналогичны правилам при объединении наборов данных:
|
Рекомендуется создать собственную функцию для заполнения таблиц поиска по результатам оптимизации, например, для реализации альтернативных методов заполнения, стратегий сглаживания или настройки выходных данных.
Структура ввода/вывода пользовательской функции заливки напоминает структуру подпрограмм интерполяции MATLAB ® INTERP1 и INTERP2. Чтобы увидеть структуру функции, лучше всего посмотреть на пример:
Найдите и откройте файл griddataTableFill.m в mbctraining папка.
Введите это в командной строке, чтобы открыть пример:
edit griddataTableFill
Все 2-D пользовательские функции заполнения должны принимать следующие шесть входных данных:
| Вход | Описание |
|---|---|
| Координата столбцов результатов оптимизации |
| Координата строк результатов оптимизации |
| Оптимизированные результаты в точках (строка, кол) |
| Точки останова столбца таблицы, подлежащей заполнению |
| Точки останова строки таблицы, подлежащей заполнению |
| Существующие значения таблицы, подлежащие заполнению |
Функция должна передать три выходных аргумента обратно в CAGE, чтобы позволить CAGE заполнить таблицу:
| Продукция | Описание |
|---|---|
ok | Логический флаг, указывающий на успешность заполнения таблицы (TRUE или FALSE) |
tabval | Новые значения таблицы для заполнения (NROW-by-NCOL) |
fillmask | Логическая матрица для указания ячеек, добавляемых в маску экстраполяции вследствие заполнения таблицы (NROW-by-NCOL) |
В приведенных выше спецификациях:
NF - количество точек в результатах оптимизации, используемых для заполнения таблиц.
NCOL - количество точек останова столбцов в таблице.
NROW - количество точек останова строк в таблице.
Ваша функция должна обрабатывать случаи, когда заполнение таблицы выполнено успешно или нет. griddataTableFill, это обрабатывается с помощью конструкции try-catch вокруг вызова griddata. Если griddata должен завершиться неуспешно, то ok установлен флаг false, и функция возвращает значение.
Можно также написать пользовательские функции заливки для заполнения 1-D таблиц. В этом случае входные и выходные характеристики являются следующими:
| Вход | Описание |
|---|---|
row | Координата строк результатов оптимизации (NF-by-1) |
filldata | Оптимизированные результаты в точках (строка, кол) (NF-by-1) |
rowaxis | Точки останова строки таблицы, подлежащей заполнению (NROW-by-1) |
currtabdata | Существующие значения таблицы, подлежащие заполнению (NROW-by-1) |
| Продукция | Описание |
|---|---|
ok | Логический флаг, указывающий на успешность заполнения таблицы (TRUE или FALSE) |
tabval | Новые значения таблицы для заполнения (NROW-by-1) |
fillmask | Логическая матрица для указания ячеек, добавляемых в маску экстраполяции вследствие заполнения таблицы (NROW-by-1) |
