Целью регрессионных моделей является описание переменной ответа как функции независимых переменных. Модели множественной линейной регрессии описывают ответ как линейную комбинацию коэффициентов и функций независимых переменных. Нелинейности могут быть смоделированы с использованием нелинейных функций независимых переменных. Однако коэффициенты всегда входят в модель линейным образом.
Модели нелинейной регрессии являются более механистическими моделями нелинейных отношений между откликом и независимыми переменными. Параметры могут вводиться в модель как экспоненциальная, тригонометрическая, степенная или любая другая нелинейная функция. Неизвестные параметры в модели оцениваются путем минимизации статистического критерия, такого как отрицательное логарифмическое правдоподобие или сумма квадратичных отклонений между наблюдаемыми и прогнозируемыми значениями.
В случае фармакокинетических (PK) исследований данные ответа обычно представляют некоторые измеренные концентрации лекарств, а независимыми переменными часто являются доза и время. Нелинейная функция, часто используемая для таких данных, является экспоненциальной функцией, поскольку многие лекарства, распределенные у пациента, исключаются экспоненциальным образом. Одним из параметров PK для оценки в этом случае является скорость, с которой лекарство удаляется из организма с учетом данных о концентрации-времени.
Например, рассмотрим данные о концентрации лекарственного средства в плазме от одного индивидуума после внутривенного введения болюсной дозы, измеренной в различные моменты времени с некоторыми ошибками. Предположим, что измеренная концентрация лекарства следует за моноэкспоненциальным снижением: ket + α
Эта модель описывает временной курс концентрации лекарственного средства в организме (Ct) как функцию концентрации лекарственного средства после внутривенного введения болюсной дозы при t = 0 (C0), времени (t) и параметра скорости элиминации (ke). δ - переменная среднего нуля и единичной дисперсии, то есть ), представляющая ошибку измерения, а a - параметр модели ошибки (здесь стандартное отклонение).
Более обобщенно можно написать модель как
g (αi)
где yi - i-й ответ (такой как концентрация лекарственного средства), f - функция времени t и параметров модели p (таких как ke) и модели ошибки ).
В этой таблице представлены варианты нелинейной регрессии, доступные в SimBiology ®.
| Вариант фитинга | Пример |
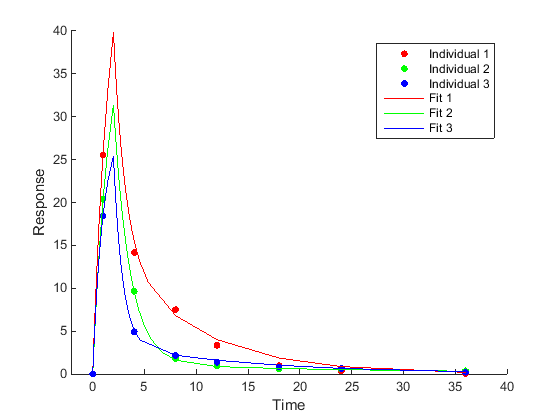
Индивидуальная оценка параметров (неохлажденный фитинг) Подгонка каждого отдельного объекта, что приводит к одному набору оценок параметров для каждого объекта. |
|
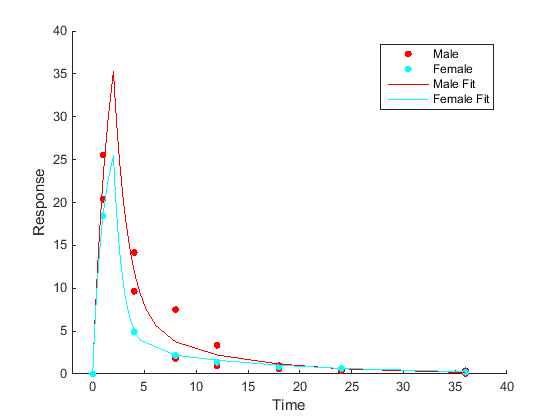
Оценка параметров, специфичных для категории или группы Подгонять каждую категорию или группу по отдельности, что приводит к одному набору оценок параметров для каждой категории. |
|
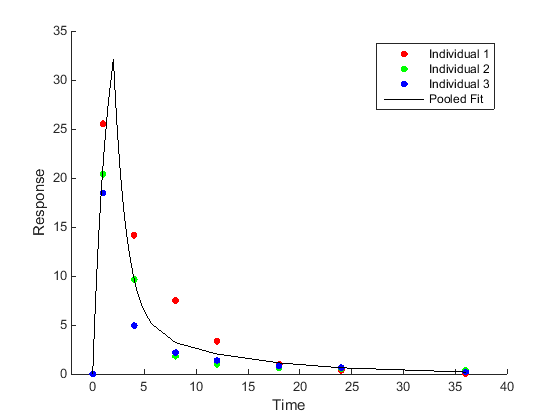
Оценка параметров для всего населения (объединенный фитинг) Подгонка всех данных, объединенных вместе, в результате чего получается только один набор оценок параметров. |
|
Кроме того, SimBiology поддерживает четыре вида моделей ошибок для измеренных или наблюдаемых ответов, а именно: постоянные (по умолчанию), пропорциональные, комбинированные и экспоненциальные. Дополнительные сведения см. в разделе Модели ошибок. В зависимости от метода оптимизации можно указать модель ошибки для каждого ответа или всех ответов. Дополнительные сведения см. в разделе Поддерживаемые методы оценки параметров в SimBiology.
SimBiology поддерживает три преобразования параметров. Эти преобразования параметров могут быть полезны для улучшения сходимости фитинга или для обеспечения границ параметров.
Общая модель, объясненная ранее, является g (αi), где p - параметры модели, которые можно преобразовать. Рассмотрим следующие два уравнения.
(p)
1 (β)
Здесь β представляет преобразованные параметры модели, p представляет нетрансформированные параметры модели, T является преобразованием, и T-1 - обратное преобразование.
SimBiology выполняет оценку параметров с использованием преобразованных параметров β, что означает, что используется преобразованная модель F (t; β) = f (t; T − 1 (β)), гдеF - функция модели, использующая преобразованные параметры. Эквивалентно, функция модели может быть переписана как T (p)).
Другими словами, оптимизатор SimBiology использует преобразованные значения во время оценки максимального правдоподобия, но сообщенный результат аппроксимации возвращается обратно в пространство модели (нетрансформированные значения). Например, если вы оцениваете логарифмически преобразованный параметр зазора Cl, у вас есть Clβ = log (Cl), где Clβ - это то, что использует оптимизатор, а Cl - то, что видит модель.
Задание преобразований параметров накладывает неявные границы на нетрансформированные значения параметров. log преобразование сохраняет значение параметра всегда положительным, и logit и probit преобразования поддерживают значение параметра в диапазоне между 0 и 1. Кроме того, можно задать дополнительные ограничения для значений параметров, предоставив явные границы для нетрансформированных параметров p или для преобразованных параметров β.
| Преобразование | Преобразованный параметр и диапазон † | Нетрансформированные параметры и диапазон ‡ | Описание |
|---|---|---|---|
| ∈[−Inf,Inf] | ∈[0,Inf] | Во многих случаях Применение |
logit | ∈[−Inf,Inf] | ) ∈[0,1] | |
probit | ∈[−Inf,Inf] | ∈[0,1] | Аналогично |
† Использовать InitialTransformedValue и TransformedBounds свойства EstimatedInfo object для установки начального преобразованного значения и преобразованных границ в требуемое подмножество диапазона.
‡ Использовать InitialValue и Bounds свойства EstimatedInfo object установка начального нетрансформированного значения и нетрансформированных границ для требуемого подмножества диапазона.
SimBiology оценивает параметры методом максимального правдоподобия. Вместо того, чтобы непосредственно максимизировать функцию правдоподобия, SimBiology создает эквивалентную задачу минимизации. Когда это возможно, оценка формулируется как оптимизация взвешенных наименьших квадратов (WLS), которая минимизирует сумму квадратов взвешенных остатков. В противном случае оценка формулируется как минимизация отрицательного логарифма правдоподобия (NLL). Состав WLS часто сходится лучше, чем состав NLL, и SimBiology может использовать преимущества специализированных алгоритмов WLS, таких как алгоритм Левенберга-Марквардта, реализованный в lsqnonlin и lsqcurvefit. SimBiology использует WLS, когда существует одна модель ошибки, которая является постоянной, пропорциональной или экспоненциальной. SimBiology использует NLL, если имеется комбинированная модель ошибки или модель с несколькими ошибками, то есть модель с моделью ошибки для каждого ответа.
sbiofit поддерживает различные методы оптимизации и передает сформулированное выражение WLS или NLL методу оптимизации, который минимизирует его. Для простоты каждое выражение, показанное ниже, предполагает только одну модель ошибки и один ответ. При наличии нескольких ответов SimBiology берет сумму выражений, соответствующих моделям ошибок заданных ответов.
| Выражение, которое сворачивается | |
|---|---|
| Взвешенные наименьшие квадраты (WLS) | Для постоянной модели ошибок fi) 2 |
| Для модели пропорциональной ошибки 2fi2/fgm2 | |
| Для экспоненциальной модели ошибок lnfi) 2 | |
| Для числовых весов 2wgm/wi | |
| Отрицательное логарифмическое правдоподобие (NLL) | Для комбинированной модели ошибок и модели с несколькими ошибками 22σi2+∑iNln2πσi2 |
Переменные определяются следующим образом.
N | Количество экспериментальных наблюдений |
yi | I-е экспериментальное наблюдение |
Прогнозируемое значение i-го наблюдения | |
Стандартное отклонение i-го наблюдения.
| |
1N | |
Вес i-го прогнозируемого значения | |
1N |
При использовании числовых весов или весовой функции предполагается, что весовые коэффициенты обратно пропорциональны дисперсии ошибки, то есть При использовании весов нельзя указать модель ошибки, кроме постоянной модели ошибки.
Различные методы оптимизации имеют различные требования к функции, которая минимизируется. Для некоторых методов оценка параметров модели выполняется независимо от оценки параметров модели ошибки. Следующая таблица суммирует модели ошибок и любые отдельные формулы, используемые для оценки параметров модели ошибок, где a и b - параметры модели ошибок, а e - стандартная переменная среднего нуля и единичной дисперсии (гауссова).
| Модель ошибки | Функция оценки параметров ошибок |
|---|---|
'constant': + ae | fi) 2 |
'exponential': ae) | lnfi) 2 |
'proportional': b 'fi' e | fifi) 2 |
'combined': b 'fi |) e | Параметры ошибок включены в минимизацию. |
| Веса | 2wi |
Примечание
nlinfit поддерживают только отдельные модели ошибок, а не модели с несколькими ошибками, то есть специфичные для ответа модели ошибок. Для комбинированной модели ошибок используется итерационный алгоритм WLS. Для других моделей ошибок используется алгоритм WLS, как описано выше. Для получения более подробной информации см. nlinfit (Статистика и инструментарий машинного обучения).
Следующие шаги показывают один из рабочих процессов, которые можно использовать в командной строке для подгонки модели PK.
Преобразование данных в groupedData формат.
Определение данных дозирования. Дополнительные сведения см. в разделе Дозы в моделях SimBiology.
Создайте несущую модель (одно-, двух- или многокамерную). Дополнительные сведения см. в разделе Создание фармакокинетических моделей.
Сопоставьте переменную ответа из данных с компонентом модели. Например, если у вас есть данные измеренной концентрации лекарственного средства для центрального отделения, то сопоставьте их с видами лекарственного средства в центральном отделении (обычно Drug_Central виды).
Укажите параметры для оценки с помощью EstimatedInfo object. При необходимости можно задать преобразования параметров, начальные значения и границы параметров.
Выполнить оценку параметров с помощью sbiofit.
Проиллюстрированные примеры см. в следующих разделах.
EstimatedInfo object | groupedData | sbiofit | sbiofitmixed