Однофакторный дисперсионный анализ
p = anova1(y)y и возвращает p -значение .anova1 обрабатывает каждый столбец y как отдельная группа. Функция проверяет гипотезу о том, что выборки в столбцах y взяты из населений с тем же средним значением против альтернативной гипотезы, что населения средства не все одинаковы. Функция также отображает прямоугольный график для каждой группы в y и стандартную таблицу ANOVA (tbl).
p = anova1(y,group,displayopt)displayopt является 'on' (по умолчанию) и подавляет отображения при displayopt является 'off'.
[ возвращает структуру, p,tbl,stats]
= anova1(___)stats, который можно использовать для выполнения нескольких сравнительных тестов. Многократный сравнительный тест позволяет вам определить, какие пары групповых средств значительно отличаются. Чтобы выполнить этот тест, используйте multcompare, обеспечивая stats структура как входной параметр.
Создайте матрицу выборочных данных y со столбцами, которые являются постоянными, плюс случайные нормальные нарушения порядка со средним значением 0 и стандартным отклонением 1.
y = meshgrid(1:5); rng default; % For reproducibility y = y + normrnd(0,1,5,5)
y = 5×5
1.5377 0.6923 1.6501 3.7950 5.6715
2.8339 1.5664 6.0349 3.8759 3.7925
-1.2588 2.3426 3.7254 5.4897 5.7172
1.8622 5.5784 2.9369 5.4090 6.6302
1.3188 4.7694 3.7147 5.4172 5.4889
Выполните однофакторный дисперсионный анализ.
p = anova1(y)


p = 0.0023
Таблица ANOVA показывает изменение между группами (Columns) и изменения внутри групп (Error). SS - сумма квадратов, и df - степени свободы. Общие степени свободы - общее количество наблюдений минус один, что составляет 25 - 1 = 24. Степени свободы между группами - это количество групп минус одна, что составляет 5 - 1 = 4. Степени свободы внутри групп являются общими степенями свободы за вычетом степеней свободы между группами, что составляет 24 - 4 = 20.
MS - средняя квадратичная невязка, которая SS/df для каждого источника изменения. F-статистическая величина является отношением средних квадратичных невязок (13.4309/2.2204). p-значение является вероятностью того, что тестовая статистика может взять значение, больше значения вычисленной тестовой статистики, т.е. P (F > 6.05). Маленькое значение p 0,0023 указывает, что различия между средними значительными.
Введите выборочные данные.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
Данные взяты из исследования упругости стержней из разного материала взятые в Хогге (1987). Сила вектора измеряет прогибы стержней в тысячных долях дюйма под 3000 фунтов силы. Векторный сплав идентифицирует каждый луч как сталь ('st'), сплав 1 ('al1'), или сплав 2 ('al2'). Несмотря на то, что сплав сортируется в этом примере, сгруппированные переменные не должны сортироваться.
Проверьте нулевую гипотезу о том, что стальные балки равны по прочности балкам, изготовленным из двух более дорогих сплавов. Отключите отображение рисунка и верните результаты Дисперсионного Анализа в массиве ячеек.
[p,tbl] = anova1(strength,alloy,'off')p = 1.5264e-04
tbl=4×6 cell array
Columns 1 through 5
{'Source'} {'SS' } {'df'} {'MS' } {'F' }
{'Groups'} {[184.8000]} {[ 2]} {[ 92.4000]} {[ 15.4000]}
{'Error' } {[102.0000]} {[17]} {[ 6.0000]} {0x0 double}
{'Total' } {[286.8000]} {[19]} {0x0 double} {0x0 double}
Column 6
{'Prob>F' }
{[1.5264e-04]}
{0x0 double }
{0x0 double }
Общие степени свободы - это общее количество наблюдений минус один, который является . Степени свободы между группами - это количество групп минус одна, которая является . Степени свободы внутри групп являются общими степенями свободы за вычетом степеней свободы между группами, что .
MS - средняя квадратичная невязка, которая SS/df для каждого источника изменения. F-статистическая величина является отношением средних квадратичных невязок. p-значение является вероятностью того, что тестовая статистика может взять значение, больше или равное значению тестовой статистики. p-значение 1.5264e-04 предполагает отказ от нулевой гипотезы.
Можно получить значения в таблице ANOVA путем индексации в массив ячеек. Сохраните F-статистическое значение и p-значение в новых переменных Fstat и pvalue.
Fstat = tbl{2,5}Fstat = 15.4000
pvalue = tbl{2,6}pvalue = 1.5264e-04
Введите выборочные данные.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
Данные взяты из исследования упругости стержней из разного материала взятые в Хогге (1987). Сила вектора измеряет прогибы стержней в тысячных долях дюйма под 3000 фунтов силы. Векторный сплав идентифицирует каждый луч как сталь (st), сплав 1 (al1), или сплав 2 (al2). Несмотря на то, что сплав сортируется в этом примере, сгруппированные переменные не должны сортироваться.
Выполните однофакторный дисперсионный анализ, используя anova1. Верните структуру stats, который содержит статистические multcompare нуждается в выполнении нескольких сравнений.
[~,~,stats] = anova1(strength,alloy);


Малое значение p 0,0002 предполагает, что прочность 0,0002 предполагает, что прочность стержней неодинакова.
Выполните многократное сравнение средней прочности стержней.
[c,~,~,gnames] = multcompare(stats);

Отображение результатов сравнения с соответствующими именами групп.
[gnames(c(:,1)), gnames(c(:,2)), num2cell(c(:,3:6))]
ans=3×6 cell array
Columns 1 through 5
{'st' } {'al1'} {[ 3.6064]} {[ 7]} {[10.3936]}
{'st' } {'al2'} {[ 1.6064]} {[ 5]} {[ 8.3936]}
{'al1'} {'al2'} {[-5.6280]} {[-2]} {[ 1.6280]}
Column 6
{[1.6831e-04]}
{[ 0.0040]}
{[ 0.3560]}
В первых двух столбцах показана пара сравниваемых групп. В четвертом столбце показано различие между предполагаемыми средними значениями группы. Третий и пятый столбцы показывают нижний и верхний пределы для 95% доверительных интервалов истинного различия средств. Шестой столбец показывает p-значение для гипотезы о том, что истинное различие средств для соответствующих групп равно нулю.
Первые две строки показывают, что оба сравнения с участием первой группы (стали) имеют доверительные интервалы, которые не включают нуль. Поскольку соответствующие значения p (1.6831e-04 и 0.0040, соответственно) малы, эти различия значительны.
Третья строка показывает, что различия в прочности двух сплавов незначительны. 95% доверительный интервал для различия является [-5.6.1.6], поэтому вы не можете отклонить гипотезу о том, что истинное различие равно нулю. Соответствующее значение p 0,3560 в шестом столбце подтверждает этот результат.
На рисунке синий брус представляет интервал сравнения для средней прочности материала для стали. Красные бруски представляют интервалы сравнения средней прочности материала для сплава 1 и сплава 2. Ни один из красных стержней не перекрывается с синим стержнем, что указывает на то, что средняя прочность материала для стали значительно отличается от прочности сплава 1 и сплава 2. Чтобы подтвердить существенное различие, щелкните по стержням, которые представляют сплав 1 и 2.
y - выборочные данныеВыборочные данные, заданная в виде вектора или матрицы.
Если y является вектором, необходимо задать group входной параметр. Каждый элемент в group представляет имя группы соответствующего элемента в y. anova1 функция обрабатывает y значения, соответствующие тому же значению group в составе той же группы. Используйте этот проект, когда группы имеют разное количество элементов (несбалансированное Дисперсионный Анализ).
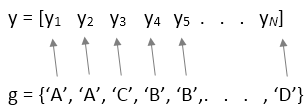
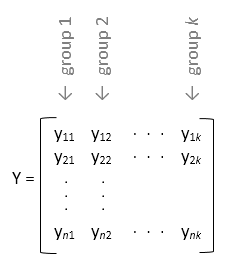
Если y является матрицей, и вы не задаете group, затем anova1 обрабатывает каждый столбец y как отдельная группа. В этом проекте функция оценивает, равны ли средние значения населения столбцов. Используйте этот проект, когда каждая группа имеет одинаковое количество элементов (сбалансированное Дисперсионный Анализ).
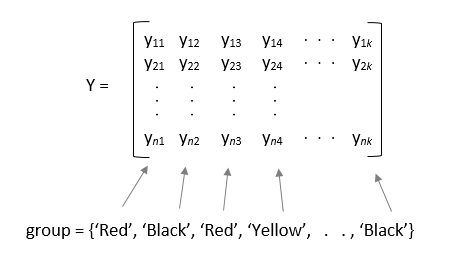
Если y является матрицей, и вы задаете group, затем каждый элемент в group представляет имя группы для соответствующего столбца в y. anova1 функция обрабатывает столбцы с тем же именем группы как часть той же группы.
Примечание
anova1 игнорирует любые NaN значения в y. Кроме того, если group содержит пустые или NaN значения, anova1 игнорирует соответствующие наблюдения в y. anova1 функция выполняет сбалансированный Дисперсионный Анализ, если каждая группа имеет одинаковое количество наблюдений после того, как функция игнорирует пустые или NaN значения. В противном случае, anova1 выполняет несбалансированное Дисперсионный Анализ.
Типы данных: single | double
group - Сгруппированная переменнаяСгруппированная переменная, содержащей имена групп, заданное как числовой вектор, логический вектор, категориальный вектор, символьный массив, строковые массивы или массив ячеек из векторов символов.
Если y является вектором, затем каждый элемент в group представляет имя группы соответствующего элемента в y. anova1 функция обрабатывает y значения, соответствующие тому же значению group в составе той же группы.
N - общее количество наблюдений.
Если y является матрицей, затем каждый элемент в group представляет имя группы для соответствующего столбца в y. The anova1 функция обрабатывает столбцы y которые имеют то же имя группы как часть одной группы.
Если вы не хотите задавать имена групп для матричных выборочных данных y, введите пустой массив ([]) или опускать этот аргумент. В этом случае, anova1 обрабатывает каждый столбец y как отдельная группа.
Если group содержит пустые или NaN значения, anova1 игнорирует соответствующие наблюдения в y.
Для получения дополнительной информации о сгруппированных переменных см. Сгруппированные переменные».
Пример: 'group',[1,2,1,3,1,...,3,1] когда y является вектором с наблюдениями, разделенными на группы 1, 2 и 3
Пример: 'group',{'white','red','white','black','red'} когда y - матрица с пятью столбцами, разделенными на группы красный, белый и черный
Типы данных: single | double | logical | categorical | char | string | cell
displayopt - Индикатор для отображения таблицы ANOVA и коробчатого графика'on' (по умолчанию) | 'off'Индикатор для отображения таблицы ANOVA и прямоугольного графика, заданный как 'on' или 'off'. Когда displayopt является 'off', anova1 возвращает только выходные аргументы. Он не отображает стандартные табличные и прямоугольные графики Дисперсионный Анализ.
Пример: p = anova(x,group,'off')
[1] Хогг, Р. В. и Дж. Ледолтер. Инженерная статистика. Нью-Йорк: Макмиллан, 1987.
anova2 | anovan | boxplot | multcompare
