Классификационные потери для перекрестно проверенной классификационной модели
L = kfoldLoss(CVMdl)CVMdl. Для каждой складки, kfoldLoss вычисляет классификационные потери для наблюдений с складкой валидации с использованием классификатора, обученного наблюдениям с складкой обучения. CVMdl.X и CVMdl.Y содержат оба набора наблюдений.
L = kfoldLoss(CVMdl,Name,Value)
Загрузите ionosphere набор данных.
load ionosphereВырастите классификационное дерево.
tree = fitctree(X,Y);
Перекрестная проверка дерева классификации с помощью 10-кратной перекрестной проверки.
cvtree = crossval(tree);
Оцените перекрестную ошибку классификации.
L = kfoldLoss(cvtree)
L = 0.1083
Загрузите ionosphere набор данных.
load ionosphereОбучите классификационный ансамбль из 100 деревьев решений с помощью AdaBoostM1. Задайте древовидные пни как слабые ученики.
t = templateTree('MaxNumSplits',1); ens = fitcensemble(X,Y,'Method','AdaBoostM1','Learners',t);
Перекрестная валидация ансамбля с помощью 10-кратной перекрестной валидации.
cvens = crossval(ens);
Оцените перекрестную ошибку классификации.
L = kfoldLoss(cvens)
L = 0.0655
kfoldLossОбучите перекрестно проверенную обобщенную аддитивную модель (GAM) с 10 складками. Затем используйте kfoldLoss вычислить совокупные ошибки классификации перекрестных валидаций (коэффициент неправильной классификации в десятичных числах). Используйте ошибки, чтобы определить оптимальное количество деревьев на предиктор (линейный термин для предиктора) и оптимальное количество деревьев на член взаимодействия.
Также можно найти оптимальные значения fitcgam аргументы имя-значение при помощи bayesopt функция. Для получения примера смотрите Оптимизацию Перекрестно Проверенной GAM Используя bayesopt.
Загрузите ionosphere набор данных. Этот набор данных имеет 34 предиктора и 351 двоичный ответ для радиолокационных возвратов, либо плохо ('b') или хорошо ('g').
load ionosphereСоздайте перекрестную проверку GAM с помощью опции перекрестной проверки по умолчанию. Задайте 'CrossVal' аргумент имя-значение как 'on'. Задайте, чтобы включить все доступные условия взаимодействия, значения p которых не более 0,05.
rng('default') % For reproducibility CVMdl = fitcgam(X,Y,'CrossVal','on','Interactions','all','MaxPValue',0.05);
Если вы задаете 'Mode' как 'cumulative' для kfoldLoss, затем функция возвращает совокупные ошибки, которые являются средними ошибками для всех складок, полученных с использованием одинакового количества деревьев для каждой складки. Отображение количества деревьев для каждой складки.
CVMdl.NumTrainedPerFold
ans = struct with fields:
PredictorTrees: [65 64 59 61 60 66 65 62 64 61]
InteractionTrees: [1 2 2 2 2 1 2 2 2 2]
kfoldLoss может вычислить совокупные ошибки, используя до 59 деревьев предикторов и одно дерево взаимодействия.
Постройте график кумулятивной, 10-кратной перекрестной ошибки классификации (коэффициент неправильной классификации в десятичных числах). Задайте 'IncludeInteractions' как false исключить условия взаимодействия из расчетов.
L_noInteractions = kfoldLoss(CVMdl,'Mode','cumulative','IncludeInteractions',false); figure plot(0:min(CVMdl.NumTrainedPerFold.PredictorTrees),L_noInteractions)

Первый элемент L_noInteractions - средняя ошибка по всем складкам, полученная с использованием только термина точка пересечения (константа). The (J+1) первый элемент L_noInteractions - средняя ошибка, полученная с помощью термина точки пересечения и первого J деревья предикторов на линейный член. Построение графика совокупных потерь позволяет вам контролировать, как изменяется ошибка, когда количество деревьев предикторов в GAM увеличивается.
Найдите минимальную ошибку и количество деревьев предикторов, используемых для достижения минимальной ошибки.
[M,I] = min(L_noInteractions)
M = 0.0655
I = 23
GAM достигает минимальной ошибки, когда включает 22 дерева предикторов.
Вычислите совокупную ошибку классификации, используя как линейные условия, так и условия взаимодействия.
L = kfoldLoss(CVMdl,'Mode','cumulative')
L = 2×1
0.0712
0.0712
Первый элемент L - средняя ошибка по всем складкам, полученная с помощью термина точка пересечения (константа) и всех деревьев предикторов на линейный термин. Второй элемент L - средняя ошибка, полученная с помощью термина точки пересечения, всех деревьев предикторов на линейный термин и одного дерева взаимодействия на термин взаимодействия. Ошибка не уменьшается при добавлении условий взаимодействия.
Если вас устраивает ошибка, когда количество деревьев предикторов составляет 22, можно создать прогнозирующую модель, снова обучив одномерную GAM и задав 'NumTreesPerPredictor',22 без перекрестной проверки.
Classification loss функции измеряют прогнозирующую неточность классификационных моделей. Когда вы сравниваете один и тот же тип потерь среди многих моделей, более низкая потеря указывает на лучшую прогнозирующую модель.
Рассмотрим следующий сценарий.
L - средневзвешенные классификационные потери.
n - размер выборки.
Для двоичной классификации:
yj - наблюдаемая метка класса. Программное обеспечение кодирует его как -1 или 1, указывая на отрицательный или положительный класс (или первый или второй класс в ClassNames свойство), соответственно.
f (Xj) является баллом классификации положительного класса для j наблюдений (строка) X данных предиктора.
mj = yj f (Xj) является классификационной оценкой для классификации j наблюдений в класс, относящийся к yj. Положительные значения mj указывают на правильную классификацию и не вносят большой вклад в средние потери. Отрицательные значения mj указывают на неправильную классификацию и вносят значительный вклад в среднюю потерю.
Для алгоритмов, которые поддерживают многоклассовую классификацию (то есть K ≥ 3):
yj* - вектор с K - 1 нулями, с 1 в положении, соответствующем истинному, наблюдаемому классу yj. Для примера, если истинный класс второго наблюдения является третьим классом и K = 4, то y 2* = [0 0 1 0]′. Порядок классов соответствует порядку в ClassNames свойство модели входа.
f (Xj) является вектором K длины счетов классов для j наблюдений X данных предиктора. Порядок счетов соответствует порядку классов в ClassNames свойство модели входа.
mj = yj*′ f (<reservedrangesplaceholder1>). Поэтому mj является скалярной классификационной оценкой, которую модель предсказывает для истинного наблюдаемого класса.
Вес для j наблюдения wj. Программа нормализует веса наблюдений так, чтобы они суммировались с соответствующей вероятностью предыдущего класса. Программное обеспечение также нормализует предыдущие вероятности, поэтому они равны 1. Поэтому,
С учетом этого сценария в следующей таблице описываются поддерживаемые функции потерь, которые можно задать при помощи 'LossFun' аргумент пары "имя-значение".
| Функция потерь | Значение LossFun | Уравнение |
|---|---|---|
| Биномиальное отклонение | 'binodeviance' | |
| Неверно классифицированный коэффициент в десятичных числах | 'classiferror' | - метка класса, соответствующая классу с максимальным счетом. I {·} является функцией индикации. |
| Потери перекрестной энтропии | 'crossentropy' |
Взвешенные потери перекрестной энтропии где веса нормированы в сумме к n вместо 1. |
| Экспоненциальные потери | 'exponential' | |
| Потеря шарнира | 'hinge' | |
| Логит потеря | 'logit' | |
| Минимальные ожидаемые затраты на неправильную классификацию | 'mincost' |
Программа вычисляет взвешенные минимальные ожидаемые затраты классификации, используя эту процедуру для наблюдений j = 1,..., n.
Взвешенное среднее значение минимальных ожидаемых потерь от неправильной классификации Если вы используете матрицу затрат по умолчанию (значение элемента которой 0 для правильной классификации и 1 для неправильной классификации), то |
| Квадратичные потери | 'quadratic' |
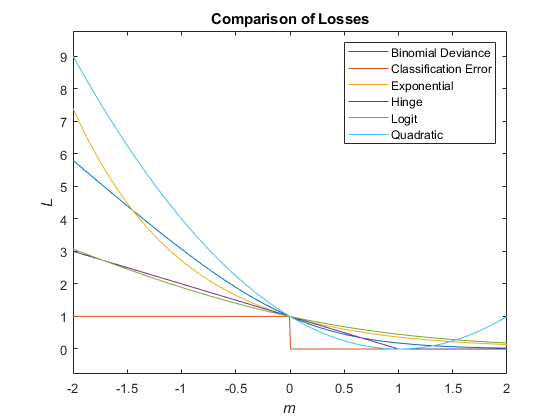
Этот рисунок сравнивает функции потерь (кроме 'crossentropy' и 'mincost') по счету m для одного наблюдения. Некоторые функции нормированы, чтобы пройти через точку (0,1).
kfoldLoss вычисляет классификационные потери, как описано в соответствующем loss функция объекта. Для описания модели смотрите соответствующее loss страницу с описанием функции в следующей таблице.
| Тип модели | loss Функция |
|---|---|
| Классификатор дискриминантного анализа | loss |
| Классификатор ансамбля | loss |
| Обобщенный классификатор аддитивной модели | loss |
| k - ближайший соседний классификатор | loss |
| Наивный классификатор Байеса | loss |
| Классификатор нейронной сети | loss |
| Машина опорных векторов | loss |
| Двоичное дерево принятия решений для многоклассовой классификации | loss |
ClassificationPartitionedModel | kfoldEdge | kfoldfun | kfoldMargin | kfoldPredict
