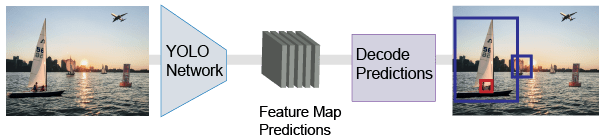
Детектор объектов (YOLO) v2 только один раз использует сеть одноэтапного обнаружения объектов. YOLO v2 быстрее, чем другие двухэтапные детекторы объектов глубокого обучения, такие как области со сверточными нейронными сетями (Faster R-CNNs).
Модель YOLO v2 запускает глубокое обучение CNN на входе изображении, чтобы создать сетевые предсказания. Детектор объектов декодирует предсказания и генерирует ограничительные рамки.
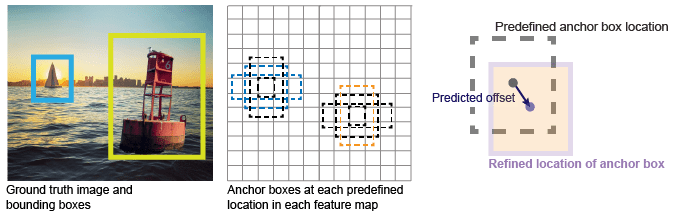
YOLO v2 использует якорные рамки для обнаружения классов объектов в изображении. Для получения дополнительной информации смотрите Якорные ящики для обнаружения объектов. YOLO v2 предсказывает эти три атрибута для каждого якорного ящика:
Пересечение над объединением (IoU) - предсказывает счет объективности каждого якорного ящика.
Смещения анкерного ящика - Уточнение положения анкерного ящика
Вероятность класса - Предсказывает метку класса, назначенную каждому якорю.
Рисунок показывает предопределенные якорные рамки (пунктирные линии) в каждом месте на карте функций и уточненном месте после применения смещений. Совпадающие поля с классом имеют цвет.
С помощью передачи обучения можно использовать предварительно обученный CNN в качестве экстрактора функцию в сети обнаружения YOLO v2. Используйте yolov2Layers функция для создания сети обнаружения YOLO v2 из любого предварительно обученного CNN, например MobileNet v2. Список предварительно обученных CNN см. в Pretrained Deep Neural Networks (Deep Learning Toolbox)
Можно также спроектировать пользовательскую модель на основе предварительно обученной классификации изображений CNN. Для получения дополнительной информации смотрите Проект сети обнаружения YOLO v2.
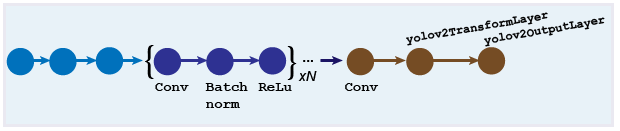
Вы можете проектировать пользовательскую модель YOLO v2 слой за слоем. Модель начинается с сети извлечения функций, которая может быть инициализирована с предварительно обученного CNN или обучена с нуля. Подсеть обнаружения содержит ряд Conv, Batch norm, и ReLu слои, за которыми следуют слои преобразования и выхода, yolov2TransformLayer и yolov2OutputLayer объекты, соответственно. yolov2TransformLayer преобразует необработанный выход CNN в форму, необходимую для создания обнаружений объектов. yolov2OutputLayer задает параметры якорного ящика и реализует функцию потерь, используемую для обучения детектора.
Можно также использовать приложение Deep Network Designer (Deep Learning Toolbox) для создания сети вручную. Конструктор включает функции Computer Vision Toolbox™ YOLO v2.
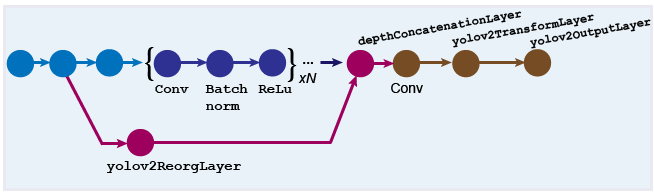
Слой реорганизации (создается с использованием spaceToDepthLayer объект) и слой конкатенации глубин (созданный с помощью depthConcatenationLayer (Deep Learning Toolbox) используются для объединения низкоуровневых и высокоуровневых функций. Эти слои улучшают обнаружение путем добавления низкоуровневой информации об изображениях и улучшения точности обнаружения для небольших объектов. Обычно слой реорганизации присоединен к слою в сети редукции данных, выходная карта функций которого больше, чем выход слоя редукции данных.
Совет
Настройте 'BlockSize' свойство spaceToDepthLayer объект таким образом, чтобы его выходной размер совпадал с входом сигнала depthConcatenationLayer (Deep Learning Toolbox) объект.
Чтобы упростить разработку сети, используйте приложение интерактивного Deep Network Designer (Deep Learning Toolbox) и analyzeNetwork (Deep Learning Toolbox) функция.
Дополнительные сведения о том, как создать сеть такого типа, см. в разделе Создание сети обнаружения объектов YOLO v2.
Чтобы узнать, как обучить детектор объектов с помощью метода глубокого обучения YOLO с CNN, смотрите пример обнаружения объектов с использованием YOLO v2 Deep Learning.
Чтобы узнать, как сгенерировать CUDA® код с использованием детектора объектов YOLO v2 (созданный с помощью yolov2ObjectDetector объект) смотрите Генерацию кода для обнаружения объектов при помощи YOLO v2.
Можно использовать Image Labeler, Video Labeler или Ground Truth Labeler (Automated Driving Toolbox) приложения для интерактивной маркировки пикселей и экспорта данных о метках для обучения. Приложения могут также использоваться для маркировки прямоугольных видимых областей (ROIs) для обнаружения объектов, меток сцен для классификации изображений и пикселей для семантической сегментации. Чтобы создать обучающие данные из любого из маркеров, экспортированных основной истиной, можно использовать objectDetectorTrainingData или pixelLabelTrainingData функций. Для получения дополнительной информации смотрите Обучающие данные для обнаружения объектов и семантической сегментации.
[1] Редмон, Джозеф и Али Фархади. «YOLO9000: Лучше, Быстрее, Сильнее». В 2017 году IEEE Conference on Компьютерное Зрение and Pattern Recognition (CVPR), 6517-25. Гонолулу, HI: IEEE, 2017. https://doi.org/10.1109/CVPR.2017.690.
[2] Редмон, Джозеф, Сантош Диввала, Росс Гиршик и Али Фархади. «Вы смотрите только один раз: унифицированное обнаружение объектов в реальном времени». Материалы Конференции IEEE по компьютерному зрению и распознаванию шаблонов (CVPR), 779-788. Лас-Вегас, NV: CVPR, 2016.
spaceToDepthLayer | yolov2ObjectDetector | yolov2OutputLayer | yolov2TransformLayer | depthConcatenationLayer (Deep Learning Toolbox)trainYOLOv2ObjectDetector | analyzeNetwork (Deep Learning Toolbox)