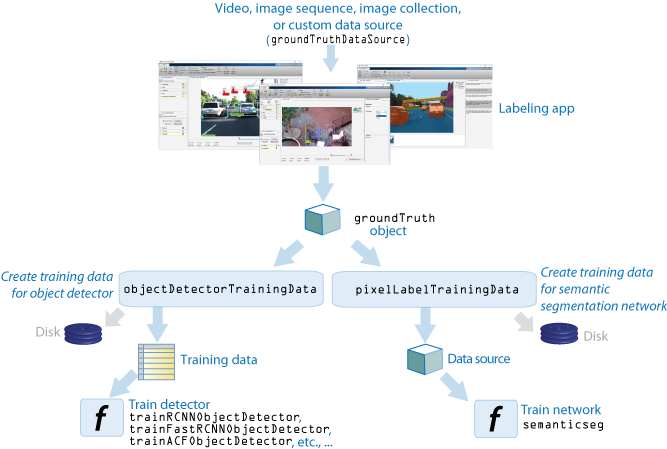
Можно использовать Image Labeler, Video Labeler и Ground Truth Labeler (требует Automated Driving Toolbox™), приложения, наряду с объектами Computer Vision Toolbox™ и функциями, чтобы обучить алгоритмы от наземных данных об истине. Во-первых, используйте свое приложение маркировки, чтобы в интерактивном режиме маркировать наземные данные об истине в видео, последовательности изображений, наборе изображений или пользовательском источнике данных. Затем используйте наземные данные об истине, чтобы создать данные тренировки алгоритма. Для объектных детекторов используйте функцию objectDetectorTrainingData. Для семантических сетей сегментации используйте функцию pixelLabelTrainingData.
Данные о загрузке для маркировки:
Image Labeler — Загрузите набор изображений из файла или объекта ImageDatastore в приложение.
Video Labeler или Ground Truth Labeler — Загрузите видео, последовательность изображений или пользовательский источник данных в приложение
Маркируйте данные и выберите алгоритм автоматизации: Создайте ROI и метки сцены в рамках приложения. Для получения дополнительной информации см.:
Image Labeler — Запуск с Image Labeler
Video Labeler — Запуск с Video Labeler
Ground Truth Labeler — Запуск с Ground Truth Labeler (Automated Driving Toolbox)
Можно выбрать из одного из встроенных алгоритмов или создать собственный алгоритм, чтобы маркировать объекты в данных. Чтобы изучить, как создать ваш собственный алгоритм автоматизации, смотрите, Создают Алгоритм Автоматизации для Маркировки.
Метки экспорта: После маркировки ваших данных можно экспортировать метки в рабочую область или сохранить их в файл. Метки экспортируются как объект groundTruth. Если ваш источник данных состоит из наборов повторного изображения, маркируйте целый набор наборов изображений, чтобы получить массив объектов groundTruth. Для получения дополнительной информации о совместном использовании объектов groundTruth, смотрите Долю, и Хранилище Маркировало Ground Truth Data.
Создайте данные тренировки: Чтобы создать данные тренировки из объекта groundTruth, используйте одну из этих функций:
Данные тренировки для объектных детекторов — Использование функция objectDetectorTrainingData.
Данные тренировки для семантических сетей сегментации — Использование функция pixelLabelTrainingData.
Выберите наземные данные об истине путем определения фактора выборки. Выборка смягчает перетренировку объектного детектора на подобных выборках. Для объектов, созданных с помощью видеофайла или пользовательского источника данных, objectDetectorTrainingData и pixelLabelTrainingData, функционирует изображения записи к диску для groundTruth.
Алгоритм train:
Объектные детекторы — Использование один из нескольких детекторов объекта Computer Vision Toolbox. Смотрите, что Обнаружение объектов использует Функции. Для объектных детекторов, характерных для автоматизированного управления, смотрите детекторы объекта Automated Driving Toolbox, перечисленные в Визуальном Восприятии (Automated Driving Toolbox).
Семантическая сеть сегментации — Использование функция semanticseg. Для получения дополнительной информации при обучении семантической сети сегментации, смотрите Семантические Основы Сегментации и Обнаружение объектов Используя пример Глубокого обучения.
groundTruth | groundTruthDataSource | objectDetectorTrainingData | pixelLabelTrainingData | semanticseg | trainACFObjectDetector | trainFasterRCNNObjectDetector | trainRCNNObjectDetector | trainRCNNObjectDetector