Вычислить выходные данные, ошибки и веса адаптивного фильтра LMS
dsp.LMSFilter Система object™ реализует адаптивный фильтр конечной импульсной характеристики (FIR), который сходит входной сигнал с требуемым сигналом, используя один из следующих алгоритмов:
LMS
Нормализованная LMS
LMS для регистрации данных
LMS со знаком ошибки
Подписывающий LMS
Дополнительные сведения о каждом из этих методов см. в разделе Алгоритмы.
Фильтр адаптирует свои веса до тех пор, пока погрешность между первичным входным сигналом и требуемым сигналом не станет минимальной. Средний квадрат этой ошибки (MSE) вычисляется с помощью msesim функция. Прогнозируемая версия MSE определяется с помощью фильтра Винера в msepred функция. maxstep функция вычисляет максимальный размер шага адаптации, который управляет скоростью сходимости.
Обзор методологии адаптивных фильтров и наиболее распространенных приложений, в которых используются адаптивные фильтры, см. в разделе Обзор адаптивных фильтров и приложений.
Для фильтрации сигнала с помощью адаптивного КИХ-фильтра:
Создать dsp.LMSFilter и задайте его свойства.
Вызовите объект с аргументами, как если бы это была функция.
Дополнительные сведения о работе системных объектов см. в разделе Что такое системные объекты?.
При определенных условиях этот объект System также поддерживает создание кода SIMD. Дополнительные сведения см. в разделе Создание кода.
lms = dsp.LMSFilterlms, которая вычисляет отфильтрованный выходной сигнал, ошибку фильтра и веса фильтра для данного входного сигнала и требуемого сигнала с использованием алгоритма наименьших средних квадратов (LMS).
lms = dsp.LMSFilter( возвращает объект фильтра LMS с заданным значением каждого свойства. Заключите каждое имя свойства в отдельные кавычки. Этот синтаксис можно использовать с предыдущим входным аргументом.Name,Value)
Если не указано иное, свойства не настраиваются, что означает невозможность изменения их значений после вызова объекта. Объекты блокируются при их вызове, и release функция разблокирует их.
Если свойство настраивается, его значение можно изменить в любое время.
Дополнительные сведения об изменении значений свойств см. в разделе Проектирование системы в MATLAB с использованием системных объектов.
Method - Метод расчета веса фильтра'LMS' (по умолчанию) | 'Normalized LMS' | 'Sign-Data LMS' | 'Sign-Error LMS' | 'Sign-Sign LMS'Метод вычисления весов фильтра, указанный как один из следующих:
'LMS' - Решает уравнение Вайнера - Хопфа и находит коэффициенты фильтра для адаптивного фильтра.
'Normalized LMS' - Нормализованное изменение алгоритма LMS.
'Sign-Data LMS' - Коррекция весов фильтра на каждой итерации зависит от знака ввода x.
'Sign-Error LMS' - Поправка, применяемая к текущим весам фильтра для каждой последовательной итерации, зависит от знака ошибки, err.
'Sign-Sign LMS' - Коррекция, применяемая к текущим весам фильтра для каждой последовательной итерации, зависит от обоих знаков x и знак err.
Дополнительные сведения о алгоритмах см. в разделе Алгоритмы.
Length - Длина вектора весов КИХ-фильтра32 (по умолчанию) | положительное целое числоДлина вектора весов фильтра FIR, заданного как положительное целое число.
Пример: 64
Пример: 16
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
StepSizeSource - Метод определения размера шага адаптации'Property' (по умолчанию) | 'Input port'Способ задания размера шага адаптации, указанный как одно из следующих:
'Property' - Свойство StepSize указывает размер каждого шага адаптации.
'Input port' - Укажите размер шага адаптации в качестве одного из входов в объект.
StepSize - Размер шага адаптации0.1 (по умолчанию) | неотрицательный скалярКоэффициент размера шага адаптации, заданный как неотрицательный скаляр. Для сходимости нормализованного метода LMS размер шага должен быть больше 0 и меньше 2.
Малый размер шага обеспечивает небольшую ошибку установившегося состояния между выходом y и требуемым сигналом d. Если размер шага мал, скорость сходимости фильтра уменьшается. Чтобы повысить скорость сходимости, увеличьте размер шага. Обратите внимание, что если размер шага велик, фильтр может стать нестабильным. Чтобы вычислить максимальный размер шага, который может принять фильтр, не становясь нестабильным, используйте maxstep функция.
Настраиваемый: Да
Это свойство применяется при установке для StepStartSource значения 'Property'.
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
LeakageFactor - Коэффициент течи, используемый в способе LMS1 (по умолчанию) | [0 1]Коэффициент утечки, используемый при реализации метода licky LMS, указанный как скаляр в диапазоне [0 1]. Когда значение равно 1, в способе адаптации нет утечки. Если значение меньше 1, фильтр реализует метод licy LMS.
Пример: 0.5
Настраиваемый: Да
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
InitialConditions - Исходные условия масс фильтров0 (по умолчанию) | скаляр | векторНачальные условия весов фильтра, заданные как скаляр или вектор длины, равный значению свойства Length. Когда входные данные являются реальными, значение этого свойства должно быть реальным.
Пример: 0
Пример: [1 3 1 2 7 8 9 0 2 2 8 2]
Типы данных: single | double | int8 | int16 | int32 | int64 | uint8 | uint16 | uint32 | uint64
Поддержка комплексного номера: Да
AdaptInputPort - Флаг для адаптации весов фильтраfalse (по умолчанию) | trueФлаг для адаптации весов фильтра, указанный как один из следующих:
false - Объект постоянно обновляет веса фильтра.
true - Входной сигнал управления адаптацией предоставляется объекту при вызове его алгоритма. Если это значение не равно нулю, объект непрерывно обновляет веса фильтра. Если значение этого входа равно нулю, веса фильтра остаются на их текущем значении.
WeightsResetInputPort - Флажок для сброса весов фильтраfalse (по умолчанию) | trueФлажок для сброса весов фильтра, указанный как одно из следующих значений:
false - Объект не сбрасывает веса.
true - Управляющий вход сброса предоставляется объекту при вызове его алгоритма. Этот параметр включает свойство WearingResetCondition. Объект сбрасывает веса фильтра на основе значений WeightsResetCondition и входной сигнал сброса, предоставленный алгоритму объекта.
WeightsResetCondition - Событие для сброса весов фильтра'Non-zero' (по умолчанию) | 'Rising edge' | 'Falling edge' | 'Either edge'Событие, запускающее сброс весов фильтра, указанное как одно из следующих значений. Объект сбрасывает веса фильтра всякий раз, когда событие сброса обнаруживается на его входе сброса.
'Non-zero' - Запускает операцию сброса в каждом образце, когда входной сигнал сброса не равен нулю.
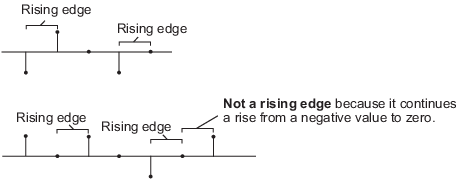
'Rising edge' -- Запускает операцию сброса, когда вход сброса выполняет одно из следующих действий:
Увеличивается от отрицательного значения до положительного значения или нуля.
Повышается от нуля до положительного значения, где подъем не является продолжением подъема от отрицательного значения до нуля.
'Falling edge' -- Запускает операцию сброса, когда вход сброса выполняет одно из следующих действий:
Падает от положительного значения до отрицательного значения или нуля.
Падает от нуля до отрицательного значения, где падение не является продолжением падения от положительного значения до нуля.
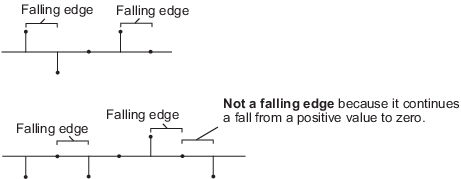
'Either edge' - Запускает операцию сброса, когда входным сигналом сброса является передний или задний фронт.
Объект сбрасывает веса фильтра на основе значения этого свойства и входного значения сброса r обеспечивается алгоритму объекта.
Это свойство применяется при установке для свойства WearingResetInputPort значения true.
WeightsOutput - Метод вывода адаптированных весов фильтра'Last' (по умолчанию) | 'None' | 'All'Способ вывода адаптированных весов фильтра, указанный как один из следующих:
'Last' (по умолчанию) - объект возвращает вектор столбца весов, соответствующий последней выборке кадра данных. Длина вектора весов - это значение, заданное свойством Length.
'All' - объект возвращает матрицу весов FrameLength-by-Length. Матрица соответствует полной выборочной истории весов для всех выборок FrameLength входных значений. Каждая строка в матрице соответствует набору весов фильтра LMS, вычисленных для соответствующей входной выборки.
'None' - Этот параметр отключает вывод весов.
RoundingMethod - Метод округления для операций с фиксированной точкой'Floor' (по умолчанию) | 'Ceiling' | 'Convergent' | 'Nearest' | 'Round' | 'Simplest' | 'Zero'Укажите режим округления для операций с фиксированной точкой. Дополнительные сведения см. в разделе Режим округления.
OverflowAction - Действие переполнения для операций с фиксированной точкой'Wrap' (по умолчанию) | 'Saturate'Действие переполнения для операций с фиксированной точкой, указанное как одно из следующих:
'Wrap' - Объект переносит результат операций с фиксированной точкой.
'Saturate' - Объект насыщает результат операций с фиксированной точкой.
Дополнительные сведения о действиях по переполнению см. в разделе Режим переполнения для операций с фиксированной точкой.
StepSizeDataType - Параметры длины слова размера шага и длины дроби'Same word length as first input' (по умолчанию) | 'Custom'Параметры длины слова размера шага и длины дроби, указанные как одно из следующих:
'Same word length as first input' -- Объект указывает длину слова размера шага, которая должна совпадать с длиной слова первого ввода. Длина дроби вычисляется для получения наилучшей возможной точности.
'Custom' -- Тип данных размера шага задается как пользовательский числовой тип с помощью свойства CustomStepStartDataType.
Дополнительные сведения о типе данных размера шага, используемом этим объектом, см. в разделе Фиксированная точка.
CustomStepSizeDataType - Длины слов и дробей размера шагаnumerictype([],16,15) (по умолчанию)Длина слова и дроби размера шага, заданная как автоматически введенный числовой тип с длиной слова 16 и длиной дроби 15.
Пример: числовой тип ([], 32)
Это свойство применяется при следующих условиях:
Для свойства StepStartSource установлено значение 'Property' и StepStartDataType имеет значение 'Custom'.
StepSizeSource свойство имеет значение 'Input port'.
LeakageFactorDataType - Параметры длины слова коэффициента утечки и длины дроби'Same word length as first input' (по умолчанию) | 'Custom'Параметры длины слова коэффициента утечки и длины дроби, указанные как одно из следующих:
'Same word length as first input' - Объект указывает, что длина слова коэффициента утечки должна совпадать с длиной слова первого входа. Длина дроби вычисляется для получения наилучшей возможной точности.
'Custom' - Тип данных коэффициента утечки задается в качестве пользовательского числового типа с помощью свойства CustomExingFactorDataType.
Дополнительные сведения о типе данных коэффициента утечки для этого объекта см. в разделе Фиксированная точка.
CustomLeakageFactorDataType - Длина слов и долей коэффициента утечкиnumerictype([],16,15) (по умолчанию)Длина слова и дроби коэффициента утечки, определяемая как автоматически обозначенный числовой тип с длиной слова 16 и длиной дроби 15.
Пример: числовой тип ([], 32)
Это свойство применяется при установке для свойства PerformateFactorDataType значения 'Custom'.
WeightsDataType - Весовые параметры длины слова и длины дроби'Same as first input' (по умолчанию) | 'Custom'Весовые параметры длины слова и дроби, указанные как одно из следующих:
'Same as first input' -- Объект указывает тип данных весов фильтра, который должен совпадать с типом данных первого входа.
'Custom' - Тип данных весов фильтра задается в качестве пользовательского числового типа с помощью свойства CustomWeelingDataType.
Дополнительные сведения о типе данных весов фильтра, используемого этим объектом, см. в разделе Фиксированная точка.
CustomWeightsDataType - Длины слов и дробей весов фильтраnumerictype([],16,15) (по умолчанию)Длины слов и дробей весов фильтра, определяемые как автоматически назначаемый числовой тип с длиной слова 16 и длиной дроби 15.
Пример: числовой тип ([], 32,20)
Это свойство применяется при установке для свойства WealingDataType значения 'Custom'.
EnergyProductDataType - Параметры длины слова энергетического продукта и длины дроби'Same as first input' (по умолчанию) | 'Custom'Параметры длины слова энергетического продукта и длины дроби, указанные как одно из следующих:
'Same as first input' - Объект указывает тип данных энергетического продукта, который должен совпадать с типом данных первого входного сигнала.
'Custom' - Тип данных энергетического продукта задается как пользовательский числовой тип с помощью свойства CustomStartProductDataType.
Дополнительные сведения о типе данных энергетического продукта, используемого этим объектом, см. в разделе Фиксированная точка.
Это свойство применяется при установке для свойства Method значения 'Normalized LMS'.
CustomEnergyProductDataType - Длина энергетического продукта в словах и доляхnumerictype([],32,20) (по умолчанию)EnergyAccumulatorDataType - Параметры длины слова накопителя энергии и длины дроби'Same as first input' (по умолчанию) | 'Custom'Параметры длины слова накопителя энергии и длины дроби, указанные как одно из следующих:
'Same as first input' - Объект определяет тип данных накопителя энергии, который должен совпадать с типом данных первого входа.
'Custom' - Тип данных накопителя энергии задается в качестве пользовательского числового типа с помощью свойства CustomGroupAccumateDataType.
Дополнительные сведения о типе данных накопителя энергии, используемом этим объектом, см. в разделе Фиксированная точка.
Это свойство применяется при установке для свойства Method значения 'Normalized LMS'.
CustomEnergyAccumulatorDataType - Длины слов и дробей накопителя энергииnumerictype([],32,20) (по умолчанию)Длины слов и дробей накопителя энергии, определенные как автоматически обозначенный числовой тип с длиной слова 32 и длиной дроби 20.
Это свойство применяется при установке для свойства Method значения 'Normalized LMS' и свойство (Тип (Тип) Data 'Custom'.
ConvolutionProductDataType - Настройки длины слова продукта свертки и длины дроби'Same as first input' (по умолчанию) | 'Custom'Параметры длины слова продукта свертки и длины дроби, указанные как одно из следующих:
'Same as first input' -- Объект указывает тип данных продукта свертки, который должен совпадать с типом данных первого входа.
'Custom' -- Тип данных продукта свертки задается как пользовательский числовой тип с помощью свойства CustomConvolableProductDataType.
Дополнительные сведения о типе данных продукта свертки, используемом этим объектом, см. в разделе Фиксированная точка.
CustomConvolutionProductDataType - Длина словосочетания и дроби свёрткиnumerictype([],32,20) (по умолчанию)Длины слов и дробей произведения свертки, определенные как автоматически обозначенный числовой тип с длиной слова 32 и длиной дроби 20.
Это свойство применяется при установке для свойства ConvolableProductDataType значения 'Custom'.
ConvolutionAccumulatorDataType - Настройки длины слова свертки и длины дроби'Same as first input' (по умолчанию) | 'Custom'Настройки длины слова-накопителя свертки и длины дроби, указанные как одно из следующих:
'Same as first input' -- Объект указывает тип данных накопителя свертки, который должен совпадать с типом данных первого входа.
'Custom' - Тип данных накопителя свертки задается как пользовательский числовой тип с помощью свойства CustomConvolureAcculityAcculateDataType.
Дополнительные сведения о типе данных накопителя свертки, используемом этим объектом, см. в разделе Фиксированная точка.
CustomConvolutionAccumulatorDataType - Длины слов и дробей аккумулятора сверткиnumerictype([],32,20) (по умолчанию)Длины слов и дробей накопителя свертки, определенные как автоматически обозначенный числовой тип с длиной слова 32 и длиной дроби 20.
Это свойство применяется при установке для свойства ConvoliveAccumerAccumateDataType значения 'Custom'.
StepSizeErrorProductDataType - Погрешность размера шага настройки длины слова продукта и длины дроби'Same as first input' (по умолчанию) | 'Custom'Ошибка размера шага настройки длины слова продукта и длины дроби, указанные как одно из следующих значений:
'Same as first input' -- Объект указывает тип данных продукта ошибки размера шага, который должен совпадать с типом данных первого ввода.
'Custom' -- Тип данных продукта ошибки размера шага указывается как пользовательский числовой тип с помощью свойства CustomStepStartErrorProductDataType.
Дополнительные сведения о типе данных продукта с ошибкой размера шага см. в разделе Фиксированная точка.
CustomStepSizeErrorProductDataType - Длина слова и дроби продукта ошибки размера шагаnumerictype([],32,20) (по умолчанию)Длина слова и дроби продукта ошибки размера шага, заданного как автоматически введенный числовой тип с длиной слова 32 и длиной дроби 20.
Это свойство применяется при установке для свойства StepStartErrorProductDataType значения 'Custom'.
WeightsUpdateProductDataType - Вес фильтра обновляет настройки длины слова продукта и длины дроби'Same as first input' (по умолчанию) | 'Custom'Параметры длины слов и долей весов фильтра обновляют продукт, указанный как один из следующих:
'Same as first input' -- Объект указывает тип данных продукта обновления весов фильтра, который должен совпадать с типом данных первого ввода.
'Custom' - Тип данных продукта обновления весов фильтра задается как пользовательский числовой тип с помощью свойства CustomWeausingStartProductDataType.
Дополнительные сведения о весах фильтра для обновления типа данных продукта, используемого этим объектом, см. в разделе Фиксированная точка.
CustomWeightsUpdateProductDataType - Словарно-дробные длины весов фильтра обновляют продуктnumerictype([],32,20) (по умолчанию)Длины слов и дробей весов фильтра обновляют продукт, указанный как автоматически обозначенный числовой тип с длиной слова 32 и длиной дроби 20.
Это свойство применяется при задании для свойства WeausingStartProductDataType значения 'Custom'.
QuotientDataType - Параметры длины частного слова и длины дроби'Same as first input' (по умолчанию) | 'Custom'Параметры длины частного слова и длины дроби, указанные как одно из следующих:
'Same as first input' -- Объект указывает, что тип данных-частное должен совпадать с типом данных первого ввода.
'Custom' -- Тип данных-частное задается как пользовательский числовой тип с помощью свойства CustomQuotityDataType.
Дополнительные сведения о частном типе данных, используемом этим объектом, см. в разделе Фиксированная точка.
Это свойство применяется при установке для свойства Method значения 'Normalized LMS'.
CustomQuotientDataType - Длина слова и дроби частногоnumerictype([],32,20) (по умолчанию)Длины слов и дробей весов фильтра обновляют продукт, указанный как автоматически обозначенный числовой тип с длиной слова 32 и длиной дроби 20.
Это свойство применяется при установке для свойства Method значения 'Normalized LMS' и свойство QuotityDataType для 'Custom'.
[ фильтрует входной сигнал, y,err,wts] = lms(x,d)x, использование d в качестве требуемого сигнала и возвращает отфильтрованный выходной сигнал в y, ошибка фильтра в errи оценочные веса фильтра в wts. Объект фильтра LMS оценивает веса фильтра, необходимые для минимизации ошибки между выходным сигналом и требуемым сигналом.
[ фильтрует входной сигнал, y,err] = lms(x,d)x, использование d в качестве требуемого сигнала и возвращает отфильтрованный выходной сигнал в y и ошибка фильтра в err если для свойства WeatingOutput установлено значение 'None'.
[___] = lms( фильтрует входной сигнал, x,d,mu)x, использование d в качестве требуемого сигнала и mu как размер шага, если для свойства StepStartSource установлено значение 'Input port'. Эти входы могут использоваться с любым из предыдущих наборов выходов.
[___] = lms( фильтрует входной сигнал, x,d,a)x, использование d в качестве требуемого сигнала и a в качестве элемента управления адаптацией, если для свойства ExecutionInputPort установлено значение true. Когда a ненулевое значение, объект System непрерывно обновляет веса фильтра. Когда a равно нулю, весовые коэффициенты фильтра остаются постоянными.
[___] = lms( фильтрует входной сигнал, x,d,r)x, использование d в качестве требуемого сигнала и r как сигнал сброса, если для свойства WeeingResetInputPort установлено значение true. Для установки условия триггера сброса можно использовать свойство WearingResetCondition. Если происходит событие сброса, объект System сбрасывает веса фильтра до их начальных значений.
Чтобы использовать функцию объекта, укажите объект System в качестве первого входного аргумента. Например, для освобождения системных ресурсов объекта System с именем obj, используйте следующий синтаксис:
release(obj)
Среднеквадратичная ошибка (MSE) измеряет среднее значение квадратов ошибок между требуемым сигналом и первичным сигналом, входящим в адаптивный фильтр. Уменьшение этой ошибки сводит первичный вход к требуемому сигналу. Определить прогнозируемое значение MSE и смоделированное значение MSE в каждый момент времени с помощью msepred и msesim функции. Сравните эти значения MSE друг с другом и относительно минимальных значений MSE и стационарных значений MSE. Кроме того, вычислите сумму квадратов ошибок коэффициента, задаваемых следом ковариационной матрицы коэффициента.
Примечание.При использовании R2016a или более ранней версии замените каждый вызов объекта синтаксисом эквивалентного шага. Например, obj(x) становится step(obj,x).
Инициализация
Создать dsp.FIRFilterСистемный object™, представляющий неизвестную систему. Передайте сигнал, x, к фильтру FIR. Выход неизвестной системы является требуемым сигналом, d, которая является суммой выходного сигнала неизвестной системы (FIR-фильтр) и аддитивного шумового сигнала, n.
num = fir1(31,0.5); fir = dsp.FIRFilter('Numerator',num); iir = dsp.IIRFilter('Numerator',sqrt(0.75),... 'Denominator',[1 -0.5]); x = iir(sign(randn(2000,25))); n = 0.1*randn(size(x)); d = fir(x) + n;
Фильтр LMS
Создать dsp.LMSFilter Системный объект для создания фильтра, который адаптируется для вывода требуемого сигнала. Установите длину адаптивного фильтра равной 32 отводам, размер шага - 0,008, а коэффициент прореживания для анализа и моделирования - 5. Переменная simmse представляет смоделированный MSE между выходными данными неизвестной системы, dи выходной сигнал адаптивного фильтра. Переменная mse дает соответствующее прогнозируемое значение.
l = 32; mu = 0.008; m = 5; lms = dsp.LMSFilter('Length',l,'StepSize',mu); [mmse,emse,meanW,mse,traceK] = msepred(lms,x,d,m); [simmse,meanWsim,Wsim,traceKsim] = msesim(lms,x,d,m);
Постройте график результатов MSE
Сравните значения смоделированного MSE, прогнозируемого MSE, минимального MSE и конечного MSE. Конечное значение MSE задается суммой минимального MSE и избыточного MSE.
nn = m:m:size(x,1); semilogy(nn,simmse,[0 size(x,1)],[(emse+mmse)... (emse+mmse)],nn,mse,[0 size(x,1)],[mmse mmse]) title('Mean Squared Error Performance') axis([0 size(x,1) 0.001 10]) legend('MSE (Sim.)','Final MSE','MSE','Min. MSE') xlabel('Time Index') ylabel('Squared Error Value')

Прогнозируемый MSE следует той же траектории, что и смоделированный MSE. Обе эти траектории сходятся с установившейся (конечной) MSE.
Постройте график траекторий коэффициентов
meanWsim - среднее значение смоделированных коэффициентов, заданное msesim. meanW - среднее значение прогнозируемых коэффициентов, msepred.
Сравните смоделированные и прогнозируемые средние значения коэффициентов фильтра LMS 12,13,14 и 15.
plot(nn,meanWsim(:,12),'b',nn,meanW(:,12),'r',nn,... meanWsim(:,13:15),'b',nn,meanW(:,13:15),'r') PlotTitle ={'Average Coefficient Trajectories for';... 'W(12), W(13), W(14), and W(15)'}
PlotTitle = 2x1 cell
{'Average Coefficient Trajectories for'}
{'W(12), W(13), W(14), and W(15)' }
title(PlotTitle) legend('Simulation','Theory') xlabel('Time Index') ylabel('Coefficient Value')

В установившемся состоянии обе траектории сходятся.
Сумма ошибок квадратного коэффициента
Сравните сумму квадратичных ошибок коэффициентов, заданных msepred и msesim. Эти значения задаются следом ковариационной матрицы коэффициентов.
semilogy(nn,traceKsim,nn,traceK,'r') title('Sum-of-Squared Coefficient Errors') axis([0 size(x,1) 0.0001 1]) legend('Simulation','Theory') xlabel('Time Index') ylabel('Squared Error Value')

maxstep функция вычисляет максимальный размер шага адаптивного фильтра. Этот размер шага сохраняет фильтр стабильным с максимально возможной скоростью сходимости. Создайте первичный входной сигнал, xпутем передачи подписанного случайного сигнала в БИХ-фильтр. Сигнал x содержит 50 кадров из 2000 выборок каждого кадра. Создайте фильтр LMS с 32 отводами и размером шага 0,1.
x = zeros(2000,50); IIRFilter = dsp.IIRFilter('Numerator',sqrt(0.75),'Denominator',[1 -0.5]); for k = 1:size(x,2) x(:,k) = IIRFilter(sign(randn(size(x,1),1))); end mu = 0.1; LMSFilter = dsp.LMSFilter('Length',32,'StepSize',mu);
Вычислите максимальный размер шага адаптации и максимальный размер шага в среднеквадратичном значении, используя maxstep функция.
[mumax,mumaxmse] = maxstep(LMSFilter,x)
mumax = 0.0625
mumaxmse = 0.0536
Идентификация системы - это процесс идентификации коэффициентов неизвестной системы с помощью адаптивного фильтра. Общий обзор процесса показан в разделе Идентификация системы - использование адаптивного фильтра для идентификации неизвестной системы. Основными компонентами являются:
Алгоритм адаптивного фильтра. В этом примере установите Method имущество dsp.LMSFilter кому 'LMS' для выбора алгоритма адаптивного фильтра LMS.
Неизвестная система или процесс для адаптации. В этом примере фильтр разработан fircband является неизвестной системой.
Соответствующие входные данные для осуществления процесса адаптации. Для общей модели LMS это желаемый сигнал ) и входной сигнал k).
Целью адаптивного фильтра является минимизация сигнала ошибки между выходом адаптивного фильтра ) и выходом неизвестной системы (или системы, которая должна быть идентифицирована) k). Как только сигнал ошибки минимизируется, адаптированный фильтр напоминает неизвестную систему. Коэффициенты обоих фильтров тесно совпадают.
Примечание.При использовании R2016a или более ранней версии замените каждый вызов объекта синтаксисом эквивалентного шага. Например, obj(x) становится step(obj,x).
Неизвестная система
Создать dsp.FIRFilter объект, представляющий идентифицируемую систему. Используйте fircband функция для разработки коэффициентов фильтра. Проектируемый фильтр представляет собой фильтр нижних частот, ограниченный до 0,2 пульсации в полосе останова.
filt = dsp.FIRFilter; filt.Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],... {'w' 'c'});
Передать сигнал x к фильтру FIR. Требуемый сигнал d - сумма выходного сигнала неизвестной системы (КИХ-фильтр) и аддитивного шумового сигнала n.
x = 0.1*randn(250,1); n = 0.01*randn(250,1); d = filt(x) + n;
Адаптивный фильтр
При наличии разработанного неизвестного фильтра и требуемого сигнала создайте и примените объект адаптивного фильтра LMS для идентификации неизвестного фильтра.
Подготовка объекта адаптивного фильтра требует начальных значений для оценок коэффициентов фильтра и размера шага LMS (mu). Можно начать с некоторого набора ненулевых значений в качестве оценок коэффициентов фильтра. В этом примере используются нули для 13 начальных весов фильтра. Установите InitialConditions имущество dsp.LMSFilter к требуемым начальным значениям весов фильтра. Для размера шага 0,8 является хорошим компромиссом между достаточно большим для того, чтобы сойтись в пределах 250 итераций (250 точек входной выборки) и достаточно малым для того, чтобы создать точную оценку неизвестного фильтра.
Создать dsp.LMSFilter объект для представления адаптивного фильтра, который использует адаптивный алгоритм LMS. Установите длину адаптивного фильтра равной 13 отводам, а размер шага - 0,8.
mu = 0.8;
lms = dsp.LMSFilter(13,'StepSize',mu)lms =
dsp.LMSFilter with properties:
Method: 'LMS'
Length: 13
StepSizeSource: 'Property'
StepSize: 0.8000
LeakageFactor: 1
InitialConditions: 0
AdaptInputPort: false
WeightsResetInputPort: false
WeightsOutput: 'Last'
Show all properties
Прохождение первичного входного сигнала x и желаемый сигнал d к фильтру LMS. Запустите адаптивный фильтр для определения неизвестной системы. Продукция y адаптивного фильтра является сигнал, сходящийся к требуемому сигналу d, тем самым минимизируя ошибку e между двумя сигналами.
Постройте график результатов. Выходной сигнал не соответствует требуемому сигналу, что делает ошибку между двумя нетривиальными.
[y,e,w] = lms(x,d); plot(1:250, [d,y,e]) title('System Identification of an FIR filter') legend('Desired','Output','Error') xlabel('Time index') ylabel('Signal value')

Сравнение весов
Вектор весов w представляет коэффициенты фильтра LMS, который подобен неизвестной системе (фильтр FIR). Чтобы подтвердить сходимость, сравните числитель фильтра FIR и расчетные веса адаптивного фильтра.
Оцененные веса фильтра не совпадают с фактическими весами фильтра, подтверждая результаты, наблюдаемые на предыдущем графике сигнала.
stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Изменение размера шага
В качестве эксперимента измените размер шага на 0,2. Повторение примера с mu = 0.2 приводит к следующему графику стебля. Фильтры не сходятся, и расчетные веса не являются хорошими расчетами фактических весов.
mu = 0.2; lms = dsp.LMSFilter(13,'StepSize',mu); [~,~,w] = lms(x,d); stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Увеличение количества выборок данных
Увеличьте размер кадра требуемого сигнала. Несмотря на то, что это увеличивает количество вычислений, алгоритм LMS теперь имеет больше данных, которые можно использовать для адаптации. При 1000 выборках данных сигнала и размере шага 0,2 коэффициенты выравниваются ближе, чем раньше, что указывает на улучшенную сходимость.
release(filt); x = 0.1*randn(1000,1); n = 0.01*randn(1000,1); d = filt(x) + n; [y,e,w] = lms(x,d); stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Увеличьте число выборок данных путем ввода данных через итерации. Выполните алгоритм на 4000 выборках данных, переданных в алгоритм LMS партиями по 1000 выборок в течение 4 итераций.
Сравните веса фильтров. Веса фильтра LMS очень близко совпадают с весами фильтра FIR, что указывает на хорошую сходимость.
release(filt); n = 0.01*randn(1000,1); for index = 1:4 x = 0.1*randn(1000,1); d = filt(x) + n; [y,e,w] = lms(x,d); end stem([(filt.Numerator).' w]) title('System Identification by Adaptive LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Выходной сигнал очень близко соответствует требуемому сигналу, делая ошибку между двумя близкими к нулю.
plot(1:1000, [d,y,e]) title('System Identification of an FIR filter') legend('Desired','Output','Error') xlabel('Time index') ylabel('Signal value')

Для улучшения характеристик сходимости алгоритма LMS нормализованный вариант (NLMS) использует адаптивный размер шага на основе мощности сигнала. По мере изменения мощности входного сигнала алгоритм вычисляет входную мощность и регулирует размер шага для поддержания соответствующего значения. Размер шага изменяется со временем, и в результате нормализованный алгоритм во многих случаях быстрее сходится с меньшим количеством выборок. Для входных сигналов, которые медленно изменяются во времени, нормализованный алгоритм LMS может быть более эффективным подходом LMS.
Пример использования подхода LMS см. в разделе Системная идентификация фильтра FIR с использованием алгоритма LMS.
Примечание.При использовании R2016a или более ранней версии замените каждый вызов объекта синтаксисом эквивалентного шага. Например, obj(x) становится step(obj,x).
Неизвестная система
Создать dsp.FIRFilter объект, представляющий идентифицируемую систему. Используйте fircband функция для разработки коэффициентов фильтра. Проектируемый фильтр представляет собой фильтр нижних частот, ограниченный до 0,2 пульсации в полосе останова.
filt = dsp.FIRFilter; filt.Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],... {'w' 'c'});
Передать сигнал x к фильтру FIR. Требуемый сигнал d - сумма выходного сигнала неизвестной системы (КИХ-фильтр) и аддитивного шумового сигнала n.
x = 0.1*randn(1000,1); n = 0.001*randn(1000,1); d = filt(x) + n;
Адаптивный фильтр
Для использования нормализованного изменения алгоритма LMS установите Method свойство на dsp.LMSFilter кому 'Normalized LMS'. Установите длину адаптивного фильтра равной 13 отводам, а размер шага - 0,2.
mu = 0.2; lms = dsp.LMSFilter(13,'StepSize',mu,'Method',... 'Normalized LMS');
Прохождение первичного входного сигнала x и желаемый сигнал d к фильтру LMS.
[y,e,w] = lms(x,d);
Продукция y адаптивного фильтра является сигнал, сходящийся к требуемому сигналу d, тем самым минимизируя ошибку e между двумя сигналами.
plot(1:1000, [d,y,e]) title('System Identification by Normalized LMS Algorithm') legend('Desired','Output','Error') xlabel('Time index') ylabel('Signal value')

Сравнение адаптированного фильтра с неизвестной системой
Вектор весов w представляет коэффициенты фильтра LMS, который подобен неизвестной системе (FIR-фильтр). Чтобы подтвердить сходимость, сравните числитель фильтра FIR и оцененные веса адаптивного фильтра.
stem([(filt.Numerator).' w]) title('System Identification by Normalized LMS Algorithm') legend('Actual filter weights','Estimated filter weights',... 'Location','NorthEast')

Адаптивный фильтр адаптирует свои коэффициенты фильтра к коэффициентам неизвестной системы. Целью является минимизация сигнала ошибки между выходом неизвестной системы и выходом адаптивного фильтра. Когда эти два выхода сходятся и близко совпадают для одного и того же входа, коэффициенты, как говорят, совпадают близко. Адаптивный фильтр в этом состоянии напоминает неизвестную систему. В этом примере сравнивается скорость, с которой происходит эта сходимость для нормализованного алгоритма LMS (NLMS) и алгоритма LMS без нормализации.
Неизвестная система
Создать dsp.FIRFilter представляет неизвестную систему. Передать сигнал x в качестве входных данных неизвестной системы. Требуемый сигнал d - сумма выходного сигнала неизвестной системы (КИХ-фильтр) и аддитивного шумового сигнала n.
filt = dsp.FIRFilter; filt.Numerator = fircband(12,[0 0.4 0.5 1],[1 1 0 0],[1 0.2],... {'w' 'c'}); x = 0.1*randn(1000,1); n = 0.001*randn(1000,1); d = filt(x) + n;
Адаптивный фильтр
Создать два dsp.LMSFilter объекты, один из которых установлен в алгоритм LMS, а другой - в нормализованный алгоритм LMS. Выберите размер шага адаптации 0,2 и установите длину адаптивного фильтра равной 13 отводам.
mu = 0.2; lms_nonnormalized = dsp.LMSFilter(13,'StepSize',mu,... 'Method','LMS'); lms_normalized = dsp.LMSFilter(13,'StepSize',mu,... 'Method','Normalized LMS');
Прохождение первичного входного сигнала x и желаемый сигнал d к обоим вариациям алгоритма LMS. Переменные e1 и e2 представляют ошибку между требуемым сигналом и выходом нормализованного и ненормализованного фильтров соответственно.
[~,e1,~] = lms_normalized(x,d); [~,e2,~] = lms_nonnormalized(x,d);
Постройте график сигналов ошибок для обоих вариантов. Сигнал ошибки для варианта NLMS сходится к нулю гораздо быстрее, чем сигнал ошибки для варианта LMS. Нормализованная версия адаптируется в гораздо меньшем количестве итераций к результату почти так же хорошо, как ненормированная версия.
plot([e1,e2]); title('Comparing the LMS and NLMS Conversion Performance'); legend('NLMS derived filter weights', ... 'LMS derived filter weights','Location', 'NorthEast'); xlabel('Time index') ylabel('Signal value')

Отмена аддитивного шума n, добавленного в неизвестную систему с помощью адаптивного фильтра LMS. Фильтр LMS адаптирует свои коэффициенты до тех пор, пока его передаточная функция не будет максимально точно соответствовать передаточной функции неизвестной системы. Разность между выходом адаптивного фильтра и выходом неизвестной системы представляет сигнал ошибки, e. Минимизация этого сигнала ошибки является целью адаптивного фильтра.
Неизвестная система и фильтр LMS обрабатывают один и тот же входной сигнал, xи производить результаты d и yсоответственно. Если коэффициенты адаптивного фильтра совпадают с коэффициентами неизвестной системы, ошибка, e, фактически представляет собой аддитивный шум.
Примечание.При использовании R2016a или более ранней версии замените каждый вызов объекта синтаксисом эквивалентного шага. Например, obj(x) становится step(obj,x).
Создать dsp.FIRFilter Системный объект для представления неизвестной системы. Создать dsp.LMSFilter и установить длину 11 отводов и размер шага 0,05. Создайте синусоидальную волну для представления шума, добавленного в неизвестную систему. Просмотрите сигналы во временном диапазоне.
FrameSize = 100; NIter = 10; lmsfilt2 = dsp.LMSFilter('Length',11,'Method','Normalized LMS', ... 'StepSize',0.05); firfilt2 = dsp.FIRFilter('Numerator', fir1(10,[.5, .75])); sinewave = dsp.SineWave('Frequency',0.01, ... 'SampleRate',1,'SamplesPerFrame',FrameSize); scope = timescope('TimeUnits','Seconds',... 'YLimits',[-3 3],'BufferLength',2*FrameSize*NIter, ... 'ShowLegend',true,'ChannelNames', ... {'Noisy signal', 'Error signal'});
Создайте случайный входной сигнал x и передайте его в фильтр FIR. Добавьте синусоидальную волну к выходному сигналу КИХ-фильтра для генерации шумового сигнала, d. Сигнал, d - выход неизвестной системы. Передайте шумовой сигнал и первичный входной сигнал в фильтр LMS. Просмотрите шумный сигнал и сигнал ошибки во временном диапазоне.
for k = 1:NIter x = randn(FrameSize,1); d = firfilt2(x) + sinewave(); [y,e,w] = lmsfilt2(x,d); scope([d,e]) end release(scope)

Сигнал ошибки, e, - синусоидальный шум, добавленный к неизвестной системе. Минимизация сигнала ошибки сводит к минимуму шум, добавляемый в систему.
Когда объем вычислений, необходимых для получения адаптивного фильтра, управляет процессом разработки, вариант sign-data алгоритма LMS (SDLMS) может быть очень хорошим выбором, как показано в этом примере.
В стандартных и нормированных вариациях адаптивного фильтра LMS коэффициенты для адаптирующего фильтра возникают из среднеквадратической ошибки между требуемым сигналом и выходным сигналом от неизвестной системы. Алгоритм знаковых данных изменяет вычисление среднеквадратической ошибки, используя знак входных данных для изменения коэффициентов фильтра.
Когда ошибка является положительной, новые коэффициенты являются предыдущими коэффициентами плюс ошибка, умноженная на размер шага. Если ошибка отрицательна, новые коэффициенты снова являются предыдущими коэффициентами минус ошибка, умноженная на
Когда входной сигнал равен нулю, новые коэффициенты совпадают с предыдущим набором.
В векторной форме алгоритм LMS знаковых данных:
sgn (x (k)),
где
0-1, x (k) < 0
с вектором , содержащим веса, применяемые к коэффициентам фильтра, и вектором , содержащим входные данные. Вектор представляет собой ошибку между требуемым сигналом и отфильтрованным сигналом. Целью алгоритма SDLMS является минимизация этой ошибки. Размер шага представлен .
При меньшем коррекция весов фильтра становится меньше для каждой выборки, и ошибка SDLMS падает медленнее. Более крупная изменяет веса больше для каждого шага, поэтому ошибка падает быстрее, но результирующая ошибка не приближается к идеальному решению так близко. Чтобы обеспечить хорошую скорость схождения и стабильность, выберите в следующих практических пределах.
InputSignalPower},
где - количество выборок в сигнале. Кроме того, для эффективной обработки данных в качестве мощности, равной двум, следует определить λ.
Примечание.То, как вы устанавливаете начальные условия алгоритма знаковых данных, оказывает глубокое влияние на эффективность процесса адаптации. Поскольку алгоритм по существу квантует входной сигнал, алгоритм может легко стать нестабильным.
Ряд больших входных значений, связанных с процессом квантования, может привести к росту ошибки за все границы. Сдерживают тенденцию алгоритма знаковых данных выходить из-под контроля, выбирая малый размер шага и устанавливая начальные условия для алгоритма ненулевыми положительными и отрицательными значениями.
В этом примере шумоподавления установите Method имущество dsp.LMSFilter кому 'Sign-Data LMS'. В этом примере требуется два набора входных данных:
Данные, содержащие сигнал, поврежденный шумом. На блок-схеме в разделе «Шум или подавление помех - использование адаптивного фильтра для удаления шума из неизвестной системы» это требуемый сигнал ). Процесс подавления шума удаляет шум из сигнала.
Данные, содержащие случайный шум. На блок-схеме в разделе «Шум или подавление помех - использование адаптивного фильтра для удаления шума из неизвестной системы» это значение равно ). Сигнал k) коррелирует с шумом, который повреждает данные сигнала. Без корреляции между шумовыми данными адаптирующий алгоритм не может удалить шум из сигнала.
Для сигнала используйте синусоидальную волну. Обратите внимание, что signal является вектором столбца из 1000 элементов.
signal = sin(2*pi*0.055*(0:1000-1)');
Теперь добавьте коррелированный белый шум к signal. Чтобы гарантировать корреляцию шума, пропустите шум через фильтр КИХ нижних частот и затем добавьте отфильтрованный шум к сигналу.
noise = randn(1000,1); filt = dsp.FIRFilter; filt.Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise является коррелированным шумом и d теперь является желаемым входом в алгоритм знаковых данных.
Для подготовки dsp.LMSFilter объект для обработки, установить исходные условия весов фильтра и mu (StepSize). Как отмечалось ранее в этом разделе, значения, установленные для coeffs и mu определить, может ли адаптивный фильтр удалить шум из тракта сигнала.
В разделе Системная идентификация фильтра FIR с помощью алгоритма LMS создан фильтр по умолчанию, который устанавливает коэффициенты фильтра на нули. В большинстве случаев этот подход не работает для алгоритма знаковых данных. Чем ближе исходные коэффициенты фильтра к ожидаемым значениям, тем больше вероятность того, что алгоритм будет вести себя хорошо и сойдется с решением фильтра, которое эффективно устранит шум.
Для этого примера начните с коэффициентов, используемых в шумовом фильтре (filt.Numerator) и слегка модифицируйте их, чтобы алгоритм должен адаптироваться.
coeffs = (filt.Numerator).'-0.01; % Set the filter initial conditions. mu = 0.05; % Set the step size for algorithm updating.
С требуемыми входными аргументами для dsp.LMSFilter подготовлен, построен объект фильтра LMS, выполнена адаптация и просмотрены результаты.
lms = dsp.LMSFilter(12,'Method','Sign-Data LMS',... 'StepSize',mu,'InitialConditions',coeffs); [~,e] = lms(noise,d); L = 200; plot(0:L-1,signal(1:L),0:L-1,e(1:L)); title('Noise Cancellation by the Sign-Data Algorithm'); legend('Actual signal','Result of noise cancellation',... 'Location','NorthEast'); xlabel('Time index') ylabel('Signal values')

Когда dsp.LMSFilter он использует гораздо меньше операций умножения, чем любой из стандартных алгоритмов LMS. Кроме того, выполнение адаптации знаковых данных требует только умножения на битовый сдвиг, когда размер шага равен степени два.
Хотя производительность алгоритма знаковых данных, как показано на этом графике, достаточно хорошая, алгоритм знаковых данных гораздо менее стабилен, чем стандартные вариации LMS. В этом примере подавления шума обработанный сигнал является очень хорошим совпадением с входным сигналом, но алгоритм может очень легко расти без ограничения, а не достигать хорошей производительности.
Изменение начальных условий веса (InitialConditions) и mu (StepSize) или даже фильтр нижних частот, использованный для создания коррелированного шума, может привести к сбою подавления шума.
В стандартных и нормированных вариациях адаптивного фильтра LMS коэффициенты для адаптирующего фильтра возникают из вычисления среднеквадратической ошибки между требуемым сигналом и выходным сигналом от неизвестной системы и применения результата к текущим коэффициентам фильтра. Алгоритм LMS со знаком ошибки (SELMS) заменяет вычисление среднеквадратической ошибки на использование знака ошибки для изменения коэффициентов фильтра.
Когда ошибка является положительной, новые коэффициенты являются предыдущими коэффициентами плюс ошибка, умноженная на размер шага . Если ошибка отрицательная, новые коэффициенты являются предыдущими коэффициентами минус ошибка, умноженная на - обратите внимание на изменение знака. Когда входной сигнал равен нулю, новые коэффициенты совпадают с предыдущим набором.
В векторной форме алгоритм LMS со знаком ошибки:
(k)) (x (k)),
где
0-1, e (k) < 0
с вектором , содержащим веса, применяемые к коэффициентам фильтра, и вектором , содержащим входные данные. Вектор представляет собой ошибку между требуемым сигналом и отфильтрованным сигналом. Целью алгоритма SELMS является минимизация этой ошибки.
При меньшем коррекция к весам фильтра становится меньше для каждой выборки, и ошибка SELMS падает медленнее. Более крупная больше изменяет веса для каждого шага, так что ошибка падает быстрее, но результирующая ошибка не приближается к идеальному решению так близко. Чтобы обеспечить хорошую скорость схождения и стабильность, выберите в следующих практических пределах.
InputSignalPower}
где - количество выборок в сигнале. Кроме того, для эффективного вычисления можно определить λ как мощность двух.
Примечание.То, как вы устанавливаете начальные условия алгоритма ошибки знака, оказывает глубокое влияние на эффективность процесса адаптации. Поскольку алгоритм по существу квантует сигнал ошибки, алгоритм может легко стать нестабильным.
Ряд больших значений ошибок, связанных с процессом квантования, может привести к росту ошибок за все границы. Сдерживать тенденцию алгоритма ошибки знака к неустойчивости, выбирая небольшой размер шага и устанавливая начальные условия для алгоритма ненулевыми положительными и отрицательными значениями.
В этом примере шумоподавления установите Method имущество dsp.LMSFilter кому 'Sign-Error LMS'. В этом примере требуется два набора входных данных:
Данные, содержащие сигнал, поврежденный шумом. На блок-схеме в разделе «Шум или подавление помех - использование адаптивного фильтра для удаления шума из неизвестной системы» это требуемый сигнал ). Процесс подавления шума удаляет шум из сигнала.
Данные, содержащие случайный шум. На блок-схеме в разделе «Шум или подавление помех - использование адаптивного фильтра для удаления шума из неизвестной системы» это значение равно ). Сигнал k) коррелирует с шумом, который повреждает данные сигнала. Без корреляции между шумовыми данными адаптирующий алгоритм не может удалить шум из сигнала.
Для сигнала используйте синусоидальную волну. Обратите внимание, что signal является вектором столбца из 1000 элементов.
signal = sin(2*pi*0.055*(0:1000-1)');
Теперь добавьте коррелированный белый шум к signal. Чтобы гарантировать корреляцию шума, пропустите шум через фильтр КИХ нижних частот и затем добавьте отфильтрованный шум к сигналу.
noise = randn(1000,1); filt = dsp.FIRFilter; filt.Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise является коррелированным шумом и d теперь является желаемым входом в алгоритм ошибки знака.
Для подготовки dsp.LMSFilter объект для обработки, установить исходные условия весов фильтра (InitialConditions) и mu (StepSize). Как отмечалось ранее в этом разделе, значения, установленные для coeffs и mu определить, может ли адаптивный фильтр удалить шум из тракта сигнала.
В разделе Системная идентификация фильтра FIR с помощью алгоритма LMS создан фильтр по умолчанию, который устанавливает коэффициенты фильтра на нули. В большинстве случаев этот подход не работает для алгоритма ошибки знака. Чем ближе исходные коэффициенты фильтра к ожидаемым значениям, тем больше вероятность того, что алгоритм будет вести себя хорошо и сойдется с решением фильтра, которое эффективно устранит шум.
Для этого примера начните с коэффициентов, используемых в шумовом фильтре (filt.Numerator) и немного изменить их, чтобы алгоритм должен адаптироваться.
coeffs = (filt.Numerator).'-0.01; % Set the filter initial conditions. mu = 0.05; % Set the step size for algorithm updating.
С требуемыми входными аргументами для dsp.LMSFilter подготовлен, выполните адаптацию и просмотрите результаты.
lms = dsp.LMSFilter(12,'Method','Sign-Error LMS',... 'StepSize',mu,'InitialConditions',coeffs); [~,e] = lms(noise,d); L = 200; plot(0:199,signal(1:200),0:199,e(1:200)); title('Noise cancellation performance by the sign-error LMS algorithm'); legend('Actual signal','Error after noise reduction',... 'Location','NorthEast') xlabel('Time index') ylabel('Signal value')

Когда выполняется алгоритм LMS со знаком ошибки, он использует гораздо меньше операций умножения, чем любой из стандартных алгоритмов LMS. Кроме того, выполнение адаптации со знаком ошибки требует только кратного сдвига битов, когда размер шага равен степени два.
Хотя производительность алгоритма ошибки знака, как показано на этом графике, достаточно хорошая, алгоритм ошибки знака гораздо менее стабилен, чем стандартные вариации LMS. В этом примере подавления шума адаптированный сигнал является очень хорошим совпадением с входным сигналом, но алгоритм может очень легко стать нестабильным, а не достигать хороших рабочих характеристик.
Изменение начальных условий веса (InitialConditions) и mu (StepSize), или даже фильтр нижних частот, который вы использовали для создания коррелированного шума, может привести к сбою подавления шума, и алгоритм станет бесполезным.
Алгоритм LMS со знаком (SSLMS) заменяет вычисление среднеквадратической ошибки, используя знак входных данных для изменения коэффициентов фильтра. Когда ошибка является положительной, новые коэффициенты являются предыдущими коэффициентами плюс ошибка, умноженная на размер шага . Если ошибка отрицательная, новые коэффициенты являются предыдущими коэффициентами минус ошибка, умноженная на - обратите внимание на изменение знака. Когда входной сигнал равен нулю, новые коэффициенты совпадают с предыдущим набором.
По существу, алгоритм квантует как ошибку, так и входные данные, применяя к ним оператор знака.
В векторной форме знаковый алгоритм LMS:
sgn (x (k)),
где
0-1, z (k) < 0
(x (k))
Вектор содержит веса, применяемые к коэффициентам фильтра, а вектор содержит входные данные. Вектор представляет собой ошибку между требуемым сигналом и отфильтрованным сигналом. Целью алгоритма SSLMS является минимизация этой ошибки.
При меньшем коррекция весов фильтра становится меньше для каждой выборки, и ошибка SSLMS падает медленнее. Более крупная изменяет веса больше для каждого шага, поэтому ошибка падает быстрее, но результирующая ошибка не приближается к идеальному решению так близко. Чтобы обеспечить хорошую скорость схождения и стабильность, выберите в следующих практических пределах.
InputSignalPower}
где - количество выборок в сигнале. Кроме того, для эффективного вычисления можно определить λ как мощность двух
Примечание:
То, как вы устанавливаете начальные условия алгоритма знака, глубоко влияет на эффективность процесса адаптации. Поскольку алгоритм по существу квантует входной сигнал и сигнал ошибки, алгоритм может легко стать нестабильным.
Ряд больших значений ошибок, связанных с процессом квантования, может привести к росту ошибок за все границы. Сдерживать тенденцию знакового алгоритма к неустойчивости, выбирая малый размер шага и задавая начальные условия для алгоритма ненулевыми положительными и отрицательными значениями.
В этом примере шумоподавления установите Method имущество dsp.LMSFilter кому 'Sign-Sign LMS'. В этом примере требуется два набора входных данных:
Данные, содержащие сигнал, поврежденный шумом. На блок-схеме в разделе «Шум или подавление помех - использование адаптивного фильтра для удаления шума из неизвестной системы» это требуемый сигнал ). Процесс подавления шума удаляет шум из сигнала.
Данные, содержащие случайный шум. На блок-схеме в разделе «Шум или подавление помех - использование адаптивного фильтра для удаления шума из неизвестной системы» это значение равно ). Сигнал k) коррелирует с шумом, который повреждает данные сигнала. Без корреляции между шумовыми данными адаптирующий алгоритм не может удалить шум из сигнала.
Для сигнала используйте синусоидальную волну. Обратите внимание, что signal является вектором столбца из 1000 элементов.
signal = sin(2*pi*0.055*(0:1000-1)');
Теперь добавьте коррелированный белый шум к signal. Чтобы гарантировать корреляцию шума, пропустите шум через фильтр КИХ нижних частот, затем добавьте отфильтрованный шум к сигналу.
noise = randn(1000,1); filt = dsp.FIRFilter; filt.Numerator = fir1(11,0.4); fnoise = filt(noise); d = signal + fnoise;
fnoise является коррелированным шумом и d теперь является желаемым входом в алгоритм знака.
Для подготовки dsp.LMSFilter объект для обработки, установить исходные условия весов фильтра (InitialConditions) и mu (StepSize). Как отмечалось ранее в этом разделе, значения, установленные для coeffs и mu определить, может ли адаптивный фильтр удалить шум из тракта сигнала. В разделе Системная идентификация фильтра FIR с помощью алгоритма LMS создан фильтр по умолчанию, который устанавливает коэффициенты фильтра на нули. Обычно этот подход не работает для алгоритма знака.
Чем ближе исходные коэффициенты фильтра к ожидаемым значениям, тем больше вероятность того, что алгоритм будет вести себя хорошо и сойдется с решением фильтра, которое эффективно устранит шум. В этом примере начинается с коэффициентов, используемых в шумовом фильтре (filt.Numerator) и слегка модифицируйте их, чтобы алгоритм должен адаптироваться.
coeffs = (filt.Numerator).' -0.01; % Set the filter initial conditions.
mu = 0.05;С требуемыми входными аргументами для dsp.LMSFilter подготовлен, выполните адаптацию и просмотрите результаты.
lms = dsp.LMSFilter(12,'Method','Sign-Sign LMS',... 'StepSize',mu,'InitialConditions',coeffs); [~,e] = lms(noise,d); L = 200; plot(0:199,signal(1:200),0:199,e(1:200)); title('Noise cancellation performance by the sign-sign LMS algorithm'); legend('Actual signal','Error after noise reduction',... 'Location','NorthEast') xlabel('Time index') ylabel('Signal value')

Когда dsp.LMSFilter он использует гораздо меньше операций умножения, чем любой из стандартных алгоритмов LMS. Кроме того, выполнение адаптации знака требует только кратного сдвига битов, когда размер шага равен степени два.
Хотя производительность алгоритма знака, как показано на этом графике, достаточно хорошая, алгоритм знака гораздо менее стабилен, чем стандартные вариации LMS. В этом примере подавления шума адаптированный сигнал является очень хорошим совпадением с входным сигналом, но алгоритм может очень легко стать нестабильным, а не достигать хороших рабочих характеристик.
Изменение начальных условий веса (InitialConditions) и mu (StepSize), или даже фильтр нижних частот, который вы использовали для создания коррелированного шума, может привести к сбою подавления шума, и алгоритм станет бесполезным.
Примечание.Этот пример выполняется только в R2017a или более поздних версиях. Если версия используется раньше R2017a, объект не выводит полную историю взвешивания фильтра по выборке. Если вы используете разъединение раньше R2016b, замените каждый вызов функции эквивалентным step синтаксис. Например, myObject(x) становится step(myObject,x).
Инициализируйте dsp.LMSFilter Системный объект и установка WeightsOutput свойство для 'All'. Этот параметр позволяет фильтру LMS выводить матрицу весов с размерами [FrameLength Length], что соответствует полной выборочной истории весов для всех FrameLength выборки входных значений.
FrameSize = 15000; lmsfilt3 = dsp.LMSFilter('Length',63,'Method','LMS', ... 'StepSize',0.001,'LeakageFactor',0.99999, ... 'WeightsOutput','All'); % full Weights history w_actual = fir1(64,[0.5 0.75]); firfilt3 = dsp.FIRFilter('Numerator',w_actual); sinewave = dsp.SineWave('Frequency',0.01, ... 'SampleRate',1,'SamplesPerFrame',FrameSize); scope = timescope('TimeUnits','Seconds', ... 'YLimits',[-0.25 0.75],'BufferLength',2*FrameSize, ... 'ShowLegend',true,'ChannelNames', ... {'Coeff 33 Estimate','Coeff 34 Estimate','Coeff 35 Estimate', ... 'Coeff 33 Actual','Coeff 34 Actual','Coeff 35 Actual'});
Запустите один кадр и выведите полную историю адаптивных весов, w.
x = randn(FrameSize,1); % Input signal d = firfilt3(x) + sinewave(); % Noise + Signal [~,~,w] = lmsfilt3(x,d);
Каждая строка в w - набор весов, оцененных для соответствующей входной выборки. Каждый столбец в w дает полную историю конкретного веса. Постройте график фактического веса и всей истории 33-го, 34-го и 35-го веса. На графике можно увидеть, что выход расчетного веса в конечном итоге сходится с фактическим весом, так как адаптивный фильтр получает входные выборки и продолжает адаптироваться.
idxBeg = 33; idxEnd = 35; scope([w(:,idxBeg:idxEnd), repmat(w_actual(idxBeg:idxEnd),FrameSize,1)])

Алгоритм фильтрации LMS определяется следующими уравнениями.
(n − 1) + f (u (n), e (n), λ)
Различные алгоритмы адаптивного фильтра LMS, доступные в данном объекте System, определяются как:
LMS - решает уравнение Вайнера-Хопфа и находит коэффициенты фильтра для адаптивного фильтра.
(n) u * (n)
Нормализованная LMS - нормализованная вариация алгоритма LMS.
)
В нормализованной LMS, чтобы преодолеть потенциальную численную нестабильность при обновлении весов, в знаменателе была добавлена небольшая положительная константа λ. Для двойной точности вход с плавающей запятой, ε является 2.2204460492503131e-016. Для ввода с плавающей запятой с одинарной прецизионностью, λ равно 1.192092896e-07. Для ввода с фиксированной запятой, λ равно 0.
Sign-Data LMS - коррекция весов фильтра на каждой итерации зависит от знака входа u (n).
знак (u (n))
где u (n) является реальным.
Sign-Error LMS - коррекция, применяемая к текущим весам фильтра для каждой последовательной итерации, зависит от знака ошибки, e (n).
(n)) u * (n)
Знак-знак LMS - коррекция, применяемая к текущим весам фильтра для каждой последовательной итерации, зависит как от знака u (n), так и от знака e (n).
знак (u (n))
где u (n) является реальным.
Переменные следующие:
| Переменная | Описание |
|---|---|
|
n |
Текущий индекс времени |
|
u (n) |
Вектор буферизированных входных выборок на этапе n |
|
u * (n) |
Комплексное сопряжение вектора буферизированных входных выборок на этапе n |
|
w (n) |
Вектор оценок веса фильтра на шаге n |
|
y (n) |
Отфильтрованные выходные данные на шаге n |
|
e (n) |
Ошибка оценки на шаге n |
|
d (n) |
Требуемый отклик на этапе n |
|
µ |
Размер шага адаптации |
α | Коэффициент утечки (0 < α ≤ 1) |
ε | Константа, корректирующая любую потенциальную числовую нестабильность, возникающую во время обновления весов. |
[1] Хейс, М.Х. Статистическая цифровая обработка и моделирование сигналов. Нью-Йорк: John Wiley & Sons, 1996.
Примечания и ограничения по использованию:
См. Системные объекты в создании кода MATLAB (кодер MATLAB).
dsp.LMSFilter Системный объект поддерживает создание кода SIMD с использованием технологии Intel AVX2 при следующих условиях:
Method имеет значение 'LMS' или 'Normalized LMS'.
WeightsOutput имеет значение 'None' или 'Last'.
Входной сигнал является действительным.
Входной сигнал имеет тип данных single или double.
Технология SIMD значительно повышает производительность генерируемого кода.
На следующих диаграммах показаны типы данных, используемые в dsp.LMSFilter объект для сигналов фиксированной точки. Таблица суммирует определения переменных, используемых на диаграммах:
| Переменная | Определение |
|---|---|
u | Входной вектор |
W | Вектор весов фильтра |
µ | Размер шага |
e | Ошибка |
Q | Частное, |
Продукт u 'u | Тип данных продукта в диаграмме расчета энергопотребления |
Аккумулятор u 'u | Тип данных аккумулятора на схеме расчета энергии |
Продукт W 'u | Тип данных продукта в схеме свертки |
Аккумулятор W 'u | Тип данных аккумулятора на схеме свертки |
продукта | Тип данных продукта в окне «Продукт с размером шага и диаграммой ошибок» |
продукта | Тип данных продукта и аккумулятора в диаграмме обновления веса. 1 |
1The этого количества автоматически устанавливается тот же тип данных аккумулятора, что и тип данных продукта. Сведения о минимальном, максимальном и переполнении для этого накопителя регистрируются как часть информации о продукте. Автоматическое масштабирование рассматривает этот продукт и накопитель как один тип данных.
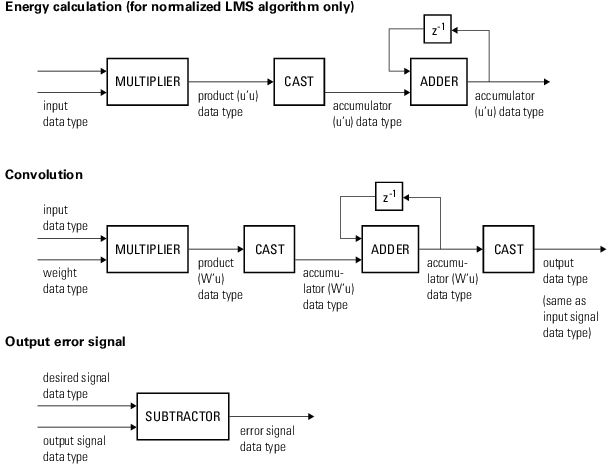
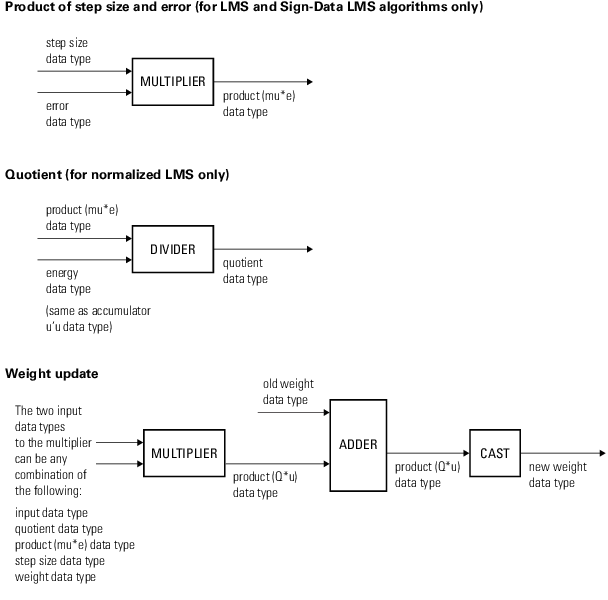
В свойствах объекта Система можно задать тип данных свойств, весов, продуктов, частного и накопителей. Входные, выходные и системные свойства объекта с фиксированной точкой должны иметь следующие характеристики:
Входной сигнал и требуемый сигнал должны иметь одинаковую длину слова, но их длины дробей могут отличаться.
Размер шага и коэффициент утечки должны иметь одинаковую длину слова, но их длины дробей могут отличаться.
Выходной сигнал и сигнал ошибки имеют одинаковую длину слова и ту же длину дроби, что и требуемый сигнал.
Частное и выходное произведение операций u 'u, W' u, μ⋅e и Q⋅u должны иметь одинаковую длину слова, но их длины дробей могут отличаться.
Тип данных накопителя операций u 'u и W' u должен иметь одинаковую длину слова, но их длины дробей могут отличаться.
Выходной сигнал множителя находится в виде выходных данных произведения, если, по меньшей мере, один из входных сигналов множителя является реальным. Если оба входа умножителя являются комплексными, результат умножения находится в накопительном типе данных. Для получения подробной информации о выполненном комплексном умножении см. Типы данных умножения.
dsp.AdaptiveLatticeFilter | dsp.AffineProjectionFilter | dsp.BlockLMSFilter | dsp.FastTransversalFilter | dsp.FilteredXLMSFilter | dsp.FIRFilter | dsp.FrequencyDomainAdaptiveFilter | dsp.RLSFilter