Для проектов, требующих доступа к большим наборам данных из внешней памяти, смоделировать алгоритм с помощью упрощенного протокола AXI4 Master. При запуске IP Core Generation workflow, HDL Coder™ генерирует ядро IP с интерфейсами AXI4 Master. Интерфейс AXI4 Master может взаимодействовать между конструкцией и внешним контроллером памяти IP с помощью протокола AXI4 Master. Используйте интерфейс AXI4 Master в следующих случаях:
Дизайн предназначен для многокадровых приложений обработки видео. Данные изображения можно хранить во внешней памяти, например, в DDR3 памяти, а затем считывать или записывать изображения в конструкцию в пакетном режиме для высокоскоростной обработки.
Алгоритм должен обращаться к данным памяти в непотоковом произвольном шаблоне.
Ядро DUT IP должно управлять другими IP с помощью AXI4 подчиненного интерфейса в системе. Эта возможность особенно полезна в автономных устройствах FPGA.
Для сопоставления портов DUT с интерфейсами AXI4 Master используется упрощенный протокол AXI4 Master. Не нужно моделировать фактический основной протокол AXI4 и вместо этого можно использовать упрощенный протокол. При запуске IP Core Generation генерируемый код HDL содержит логику оболочки, которая преобразуется между упрощенным протоколом и фактическим главным протоколом AXI4. Упрощенный протокол требует меньше сигналов протокола, упрощает механизм квитирования между действительными и готовыми сигналами и поддерживает пакеты произвольной длины.
Используйте упрощенный протокол записи AXI4 Master для транзакции записи и упрощенный протокол чтения AXI4 Master для транзакции чтения. На этом рисунке показана временная диаграмма сигналов, моделируемых в интерфейсах ввода и вывода DUT для транзакции записи AXI4 Master.
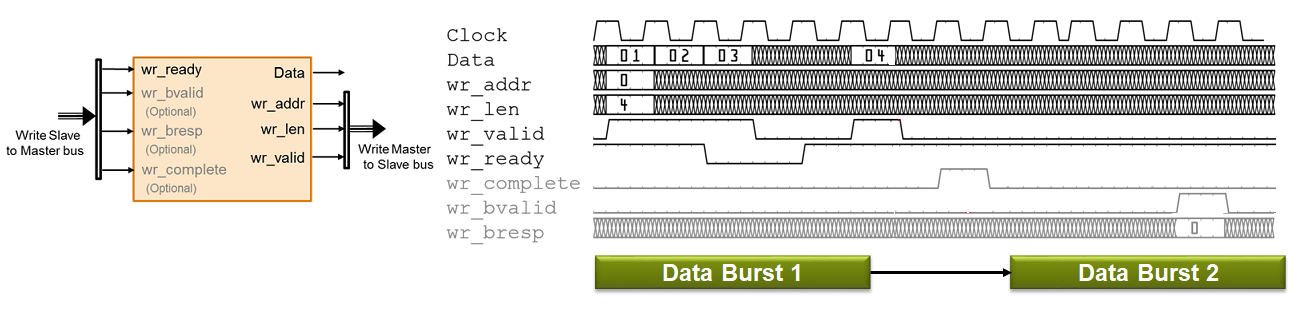
DUT ожидает wr_ready стать высоким, чтобы инициировать запрос на запись. Когда wr_ready становится высоким, DUT может послать запрос на запись. Запрос на запись состоит из Data и Write Master to Slave bus сигналы. Эта шина состоит из wr_len, wr_addr, и wr_valid. wr_addr указывает начальный адрес, на который DUT хочет выполнить запись. wr_len сигнал соответствует количеству элементов данных в этой транзакции записи. Data может быть отправлен до тех пор, пока wr_valid высоко. Когда wr_ready становится низким, DUT должен прекратить отправку данных в течение одного тактового цикла, и Data сигнал становится недействительным. Если DUT продолжает посылать данные после одного такта, данные игнорируются.
Выходные сигналы
Смоделировать Data и Write Master to Slave bus сигналы на выходном интерфейсе DUT.
DataДанные, которые требуется перенести, действительны в каждом цикле транзакции.
Write Master to Slave bus который состоит из:
wr_addr: Начальный адрес транзакции записи, который отбирается в первом цикле транзакции. Адрес указан в байтах.
wr_len: Количество значений данных, которые требуется перенести, выбранных в первом цикле транзакции. wr_len сигнал указывается словами. Это означает, что каждая единица wr_len является полным элементом данных. Например, когда wr_len является 2, и битовая ширина данных равна 128 бит, два 128-разрядные элементы данных записываются.
wr_validКогда этот управляющий сигнал становится высоким, он указывает, что Data сигнал, дискретизированный на выходе, является действительным.
Входные сигналы
Смоделировать Write Slave to Master bus который состоит из:
wr_complete (необязательный сигнал): Управляющий сигнал, который остается высоким в течение одного такта, указывает, что транзакция записи завершена. Следующий пакет данных может быть отправлен после wr_complete утверждает. Раннее утверждение wr_complete делает среднюю задержку почти 3 такты между двумя пакетами, что делает операцию записи конвейерной и улучшает пропускную способность записи.
wr_ready: Этот сигнал соответствует обратному давлению со стороны ведомого IP-ядра или внешней памяти. Когда этот управляющий сигнал становится высоким, это означает, что данные могут быть измерены. когда wr_ready низкий, DUT должен прекратить передачу данных в течение одного тактового цикла. Вы также можете использовать wr_ready чтобы определить, может ли DUT послать второй пакетный сигнал сразу после того, как первый пакетный сигнал был определен. wr_ready сигнал остается высоким, чтобы принять второй пакет сразу после того, как принят последний элемент первого пакета. Используя wr_ready чтобы определить, когда начать следующий пакет, можно уменьшить среднюю задержку между двумя пакетами до менее чем 3 тактовых циклов.
wr_bvalid (дополнительный сигнал): Ответный сигнал от ведомого IP-ядра, который можно использовать для диагностики. wr_bvalid сигнал становится высоким после того, как AXI4 межсоединение принимает каждую пакетную транзакцию. Если wr_len больше, чем 256модуль записи AXI4 Master разбивает большой пакетный сигнал на 256 пакетов. wr_bvalid становится высоким для каждого пакета 256-го размера.
wr_bresp (дополнительный сигнал): Ответный сигнал от ведомого IP-ядра, который можно использовать для диагностики. Используйте этот сигнал с wr_bvalid сигнал.
Главный протокол AXI4 поддерживает максимальный размер пакета, равный 256. Когда у вас большой всплеск размера больше, чем 256, ведущий интерфейс AXI в сгенерированном IP-ядре HDL делит большой пакет на несколько меньших пакетов с размером 256. Поэтому даже для больших пакетов данных вы видите улучшенную пропускную способность записи.
На этом рисунке показана временная диаграмма для сигналов, моделируемых в интерфейсах ввода и вывода DUT для транзакции чтения AXI4 Master. Эти сигналы включают в себя Data, Read Master to Slave Bus, и Read Slave to Master Bus.
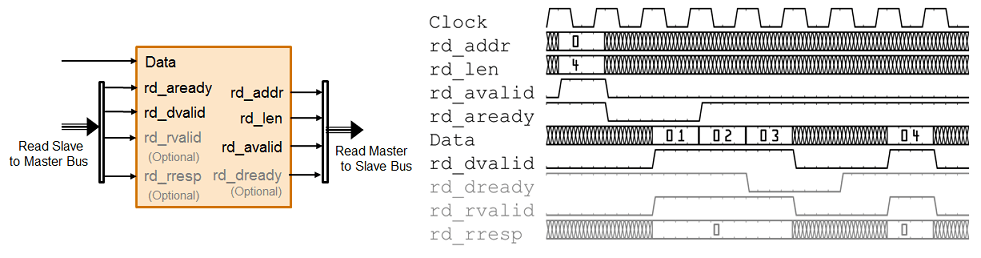
DUT ожидает rd_aready становится высоким, чтобы инициировать запрос на чтение. Когда rd_aready высокий, DUT может отправить запрос на чтение. Запрос на чтение состоит из rd_addr, rd_len, и rd_avalid сигналы Read Master to Slave bus. Подчиненный IP или внешняя память отвечает на запрос на чтение, посылая Data на каждом такте. rd_len сигнал соответствует количеству считываемых значений данных. DUT может принимать Data до тех пор, пока rd_dvalid высоко.
Запрос на чтение
Чтобы смоделировать запрос на чтение, в интерфейсе вывода DUT смоделируйте Read Master to Slave bus который состоит из:
rd_addrНачальный адрес для прочитанной транзакции, который был выбран в первом цикле транзакции. Адрес указан в байтах.
rd_len: Количество значений данных, которые вы хотите прочитать, отобранных в первом цикле транзакции. rd_len сигнал указывается словами. Это означает, что каждая единица rd_len является полным элементом данных. Например, когда rd_len является 2, и битовая ширина данных равна 128 бит, два 128Считываются -разрядные элементы данных.
rd_avalid: Управляющий сигнал, указывающий, является ли запрос на чтение действительным.
На входном интерфейсе DUT выполните команду rd_aready сигнал. Этот сигнал является частью Read Slave to Master bus и указывает, когда принимать запросы на чтение. Вы можете контролировать rd_aready сигнал для определения, может ли DUT посылать последовательные пакетные запросы. Когда rd_aready становится высоким, это указывает на то, что DUT может послать запрос на чтение в следующем такте.
Ответ на чтение
На входном интерфейсе DUT смоделируйте Data и Read Slave to Master bus сигналы.
Data: Данные, возвращенные из запроса на чтение.
Read Slave to Master bus который состоит из:
rd_dvalidУправляющий сигнал, указывающий, что Data возвращено из запроса на чтение.
rd_rvalid (дополнительный сигнал): ответный сигнал от ведомого IP-ядра, который можно использовать для диагностики.
rd_rresp (необязательный сигнал): Ответный сигнал от ведомого IP-ядра, который указывает состояние транзакции считывания.
На выходном интерфейсе DUT можно дополнительно реализовать rd_dready сигнал. Этот сигнал является частью Read Master to Slave bus и указывает, когда DUT может начать прием данных. По умолчанию, если этот сигнал не сопоставлен с интерфейсом чтения AXI4 Master, сгенерированные IP-соединения HDL rd_dready на высокий логический уровень.
Для генерируемых IP-ядер HDL Coder включает базовый регистр адресов для поддержки разработки драйверов для каналов чтения и записи AXI4 Master. Регистр базового адреса добавляется к адресу, указанному DUT ADDR для формирования главного адреса AXI4. Эта возможность позволяет драйверу использовать режим адресации, который программирует фиксированный адрес регистра с базовым адресом буфера. Запрограммированный адрес вместе с DUT ADDR используется для индексации буфера. По умолчанию регистры принимают нулевое значение, если они не используются.
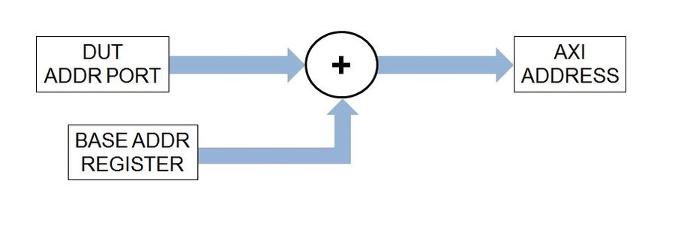
При запуске IP Core Generation рабочий процесс или Simulink Real-Time FPGA I/O workflow-процесс, можно указать начальное значение для регистров считываемых и записываемых базовых адресов основных данных AXI4. По умолчанию начальное значение равно нулю. Чтобы задать ненулевое значение, выполните следующие действия.
В таблице интерфейса целевой платформы при сопоставлении входного порта DUT с портом данных AXI4 Master Read или выходного порта DUT с интерфейсом порта данных AXI4 Master Write в столбце Interface Options появляется кнопка Options.
Нажмите кнопку «» Параметры «», а затем укажите DefureReadBaseAddress или DefureWriteBaseAddress.
Можно моделировать алгоритм с помощью сигналов протокола Data и AXI4 Master на портах DUT, а затем сопоставлять сигналы с интерфейсами AXI4 Master.

Чтобы узнать, как моделировать алгоритм DUT для отображения интерфейса AXI4 Master, откройте эту модель Simulink ®. Подсистема DUT содержит простой алгоритм, который считывает данные из DDR и записывает данные обратно на другой адрес в памяти DDR.

Дважды щелкните подсистему DUT. Подсистема DDR_Access_Controller моделирует ведущие каналы чтения и записи AXI и имеет простую двухпортовую оперативную память, которая вычисляет сигнал wr_data. При двойном щелчке по DDR_Access_Controller Subsystem появятся два блока Edge Detection Subsystem, которые генерируют два начальных импульса в качестве входных для каждого функционального блока MATLAB. Одна подсистема обнаружения краев и функция контроллера чтения DDR MATLAB моделируют транзакцию считывания. Другая подсистема обнаружения границ и контроллер записи DDR MATLAB Function моделирует транзакцию записи. Эту конструкцию можно изменить для моделирования только транзакции записи или транзакции чтения с помощью одной подсистемы обнаружения границ и соответствующего функционального блока MATLAB.
Канал чтения
Контроллер чтения DDR моделируется как конечный автомат с четырьмя состояниями: INIT, IDLE, READ_BURST_START и DATA_COUNT. Состояние INIT инициализирует сигналы считывания и входные сигналы ОЗУ. Когда сигнал запуска становится высоким, конечный автомат переходит в состояние IDLE, а затем ожидает rd_aready сигнал, чтобы стать высоким. Когда rd_aready становится высоким, конечный автомат переходит в состояние READ_BURST_START, и DUT начинает считывать данные. Затем конечный автомат безоговорочно переключается в состояние DATA_COUNT и продолжает считывать данные до rd_avalid падает.
Канал записи
Контроллер записи DDR моделируется аналогично каналу чтения как конечный автомат с четырьмя состояниями: IDLE, WRITE_BURST_START, DATA_COUNT и ACK_WAIT. DUT находится в состоянии IDLE, а затем переключается в состояние WRITE_BURST_START, где он ожидает wr_ready сигнал. Когда wr_ready становится высоким, конечный автомат переключается в состояние DATA_COUNT и начинает запись данных. Данные действительны, когда wr_valid высоко. DUT продолжает записывать данные, когда wr_ready высоко. Как wr_ready становится низким, конечный автомат переключается в состояние ACK_WAIT и затем ожидает сигнала готовности, чтобы инициировать следующую транзакцию записи.
Чтобы увидеть действующий упрощенный протокол AXI4 Master, смоделируйте модель. Если установлен DSP System Toolbox™, результаты можно просмотреть и проанализировать в Logic Analyzer.

Рабочий процесс создания IP-ядра можно использовать для создания IP-ядра HDL с помощью интерфейса AXI4 Master. Если установлен Verifier™ HDL и используется плата Xilinx Zynq ZC706, то можно интегрировать ядро IP в систему по умолчанию с эталонным дизайном доступа к памяти внешнего DDR3.
Для интеграции ядра HDL IP в более крупные эталонные конструкции и достижения более высокой пропускной способности при использовании порта AXI4 Master для доступа к внешней памяти DDR, возможно, потребуется использовать большую битовую ширину на Data порт. Шина интерфейса AXI4 Master поддерживает максимальную битовую ширину 1024 биты.
Simulink ® поддерживает типы данных с фиксированной точкой, которые имеют длину слова до 128 биты. Моделирование портов DUT с длиной слова больше 128 биты, используйте векторные типы данных. Если используется векторный порт, то общая битовая ширина всех элементов в векторе больше, чем 1024 bits, задача Set Target Interface отображает ошибку.
Например, в hdlcoder_axi_master , чтобы расширить битовую ширину axim_rd_data порт в 512 биты, измените ddr_data параметр внутри DDR в fi(([40:-1:1]),0,128,0) и затем четыре раза объединяют 128-битовый вход, чтобы сформировать выход 512 бит. Блок Vector Concatenate можно использовать для вывода комбинированной битовой ширины 512 бит. Для моделирования модели замените блок простого двухпортового ОЗУ в подсистеме DUT системой простого двухпортового ОЗУ.
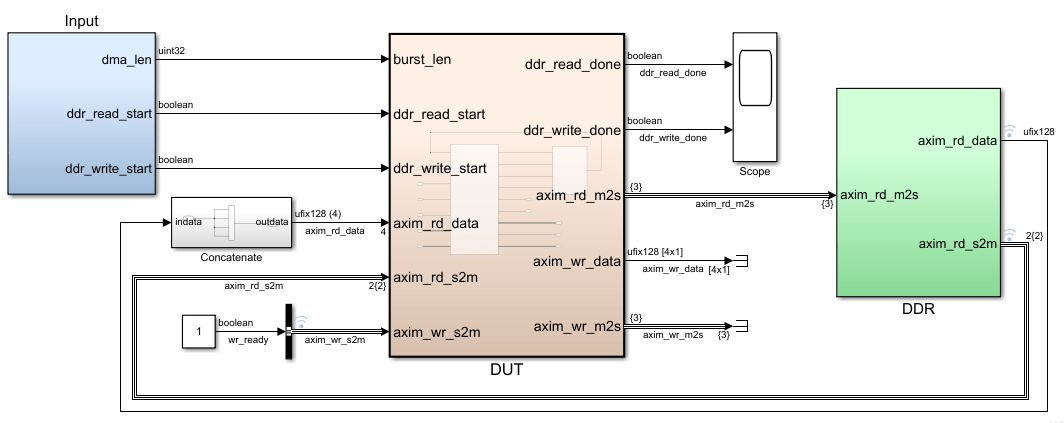
Затем эти порты данных DUT можно сопоставить с AXI4 Master Read или AXI Master Write порты в таблице интерфейса целевой платформы, создайте IP-ядро HDL и интегрируйте IP-ядро в эталонные проекты Vivado ® или Qsys. В сгенерированном коде HDL для ядра IP DUT, Data порты сопоставлены с 512-разрядные интерфейсы. Генерируют множество блоков FIFO, соответствующих каждому элементу векторного ввода.
ENTITY DUT_ip IS
PORT( IPCORE_CLK : IN std_logic; -- ufix1
IPCORE_RESETN : IN std_logic; -- ufix1
AXI4_Master_Rd_RDATA : IN std_logic_vector(511 DOWNTO 0); -- ufix256
...
...
AXI4_Master_Wr_WDATA : OUT std_logic_vector(511 DOWNTO 0); -- ufix256
...
);
END DUT_ip;На этом рисунке показан порядок записи векторных данных в форму и считывания.
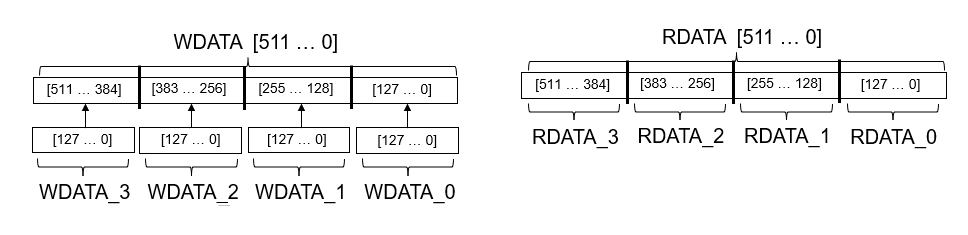
В коде HDL для ядра DUT IP можно увидеть, как AXI4_Master_Rd_RDATA и AXI4_master_Wr_WDATA интерфейсы нанесены на карту к портам DUT и заказу, в котором данные написаны интерфейсу AXI4 Master, и затем читайте назад.
...
...
--------------------------------------------------------------------
AXI4 Master Read Sequence
--------------------------------------------------------------------
AXI4_Master_Rd_RDATA_0 <= AXI4_Master_Rd_RDATA_unsigned(127 DOWNTO 0);
AXI4_Master_Rd_RDATA_1 <= AXI4_Master_Rd_RDATA_unsigned_1(255 DOWNTO 128);
AXI4_Master_Rd_RDATA_2 <= AXI4_Master_Rd_RDATA_unsigned_7(383 DOWNTO 256);
AXI4_Master_Rd_RDATA_3 <= AXI4_Master_Rd_RDATA_unsigned_7(511 DOWNTO 384);
--------------------------------------------------------------------
AXI4 Master Write Sequence
--------------------------------------------------------------------
AXI4_Master_Wr_WDATA_tmp <= unsigned(AXI4_Master_Wr_WDATA_Vec_3) &
unsigned(AXI4_Master_Wr_WDATA_Vec_2) &
unsigned(AXI4_Master_Wr_WDATA_Vec_1) &
unsigned(AXI4_Master_Wr_WDATA_Vec_0);
AXI4_Master_Wr_WDATA <= std_logic_vector(AXI4_Master_Wr_WDATA_tmp);
...
...
Если используется нестандартная битовая ширина для AXI4 Master Data порт, Data порт обновлен до стандартного контейнера битовой ширины, имеющего больший размер. Стандартная битовая ширина включает 32, 64, 128, 256, 512, и 1024 биты. Например, если используется вектор, имеющий четыре 35-битовые элементы, результирующая битовая ширина 140 биты (35x4) сопоставлен с 256-bit AXI4 Главный интерфейс. На канале записи Data порт, биты 255 кому 141 заполнены нулями. На канале Read Data порт, биты 255 кому 141 игнорируются.
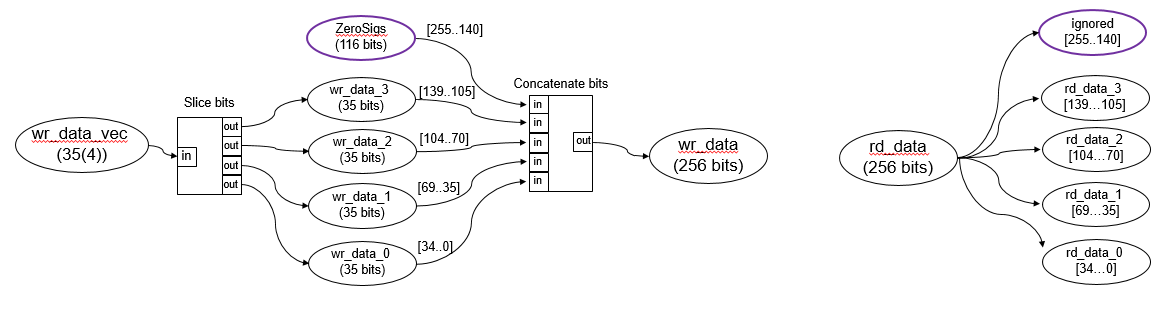
Использование нестандартных разрядов может повлиять на производительность, поскольку не используется вся полоса пропускания интерфейса AXI4 Master. Чтобы избежать снижения производительности, используйте стандартную битовую ширину AXI.
Программное обеспечение HDL Coder поддерживает проекты с несколькими частотами выборки при запуске рабочего процесса генерации IP Core. При сопоставлении портов интерфейса с интерфейсами AXI4 Master, чтобы использовать несколько скоростей выборки, убедитесь, что порты DUT, которые сопоставляются с этими интерфейсами AXI4, работают с самой высокой скоростью проектирования после генерации кода HDL.
Дополнительные сведения см. в разделе Создание многоскоростного ядра IP.
Сгенерированное ядро IP HDL можно интегрировать с интерфейсами AXI4 Master в следующие эталонные проекты кодера HDL:
Default System with External DDR3 Memory AccessКогда ваша целевая платформа Xilinx Zynq ZC706 evaluation kit.
Default System with External DDR4 Memory AccessКогда ваша целевая платформа Altera Arria10 SoC development kit.
Для использования этих ссылочных проектов необходимо установить Verifier™ HDL. На этом рисунке показана высокоуровневая блок-схема эталонной архитектуры конструкции.
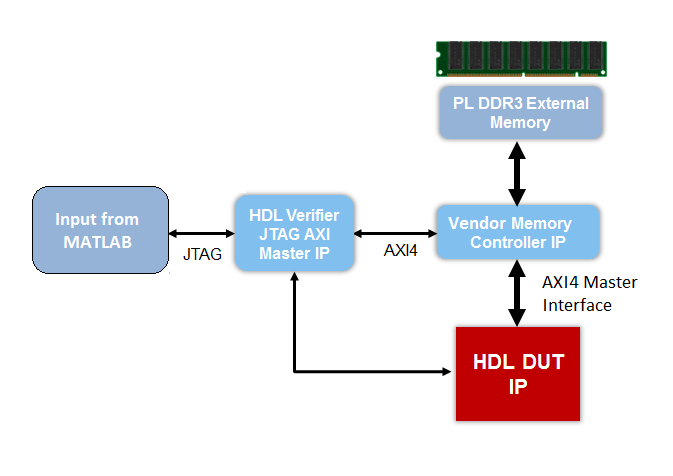
В этой архитектуре HDL DUT IP блок соответствует ядру IP, которое генерируется из IP Core Generation workflow-процесс. Другие блоки в архитектуре представляют предопределенную эталонную конструкцию, состоящую из MATLAB ® JTAG AXI Master IP который предоставляется верификатором HDL. После запуска конструкции FPGA на плате, используя JTAG AXI Master IP, можно использовать входные данные в MATLAB для инициализации встроенной DDR3 внешней памяти. HDL DUT IP ядро считывает входные данные из внешней памяти через интерфейс AXI4 Master. Затем ядро IP выполняет вычисление алгоритма и записывает результат в DDR3 память через интерфейс AXI4 Master. JTAG AXI Master IP может считывать результат из DDR3 памяти и затем проверять результат в MATLAB.
Использование addAXI4MasterInterface способ hdlcoder.ReferenceDesign класс, вы можете интегрировать ядро IP с AXI4 Master Interface в свой собственный эталонный дизайн.
Средство синтеза: Должно быть Xilinx Vivado или Altera QUARTUS II. Xilinx ISE не поддерживается.
Целевой рабочий процесс: Использовать IP Core Generation workflow-процесс. Чтобы запустить рабочий процесс, откройте помощник по рабочим процессам HDL из алгоритма DUT в Simulink. Рабочий процесс MATLAB-HDL не поддерживается.
Синхронизация процессора/FPGA: Должно быть Free running режим.
