Оцените и проверьте линейные модели из данных multi-input/single-output (MISO), чтобы найти ту, которая лучше всего описывает динамику системы.
После выполнения этого руководства вы сможете выполнить следующие задачи с помощью командной строки:
Создайте объекты данных для представления данных.
Постройте график данных.
Обработайте данные путем удаления смещений из сигналов входа и выхода.
Оцените и проверьте линейные модели из данных.
Моделируйте и прогнозируйте выход модели.
Примечание
Это руководство использует данные временной области, чтобы продемонстрировать, как вы можете оценить линейные модели. Тот же процесс применяется к подгонке данных частотного диапазона.
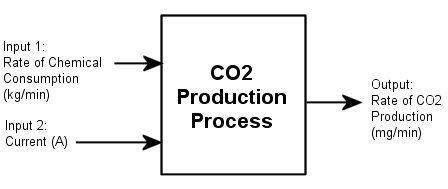
В этом руководстве используется файл данных co2data.mat, который содержит два эксперимента данных временной области с двумя входами и одним выходом (MISO) из установившегося состояния, которое оператор возмущал от значений равновесия.
В первом эксперименте оператор ввел импульсную волну на оба входа. Во втором эксперименте оператор ввел импульсную волну на первый вход и шаговый сигнал на второй вход.
Загрузите данные.
load co2data
Эта команда загружает следующие пять переменных в Рабочее пространство MATLAB:
Input_exp1 и Output_exp1 являются входными и выходными данными первого эксперимента, соответственно.
Input_exp2 и Output_exp2 являются входными и выходными данными второго эксперимента, соответственно.
Time - временной вектор от 0 до 1000 минут, увеличивающаяся в равных шагах 0.5 мин.
Для обоих экспериментов входные данные состоят из двух столбцов значений. Первый столбец значений - темп потребления химикатов (в килограммах в минуту), а второй столбец значений - ток (в амперах). Выходными данными является один столбец скорости производства углекислого газа (в миллиграммах в минуту).
Постройте график входных и выходных данных из обоих экспериментов.
plot(Time,Input_exp1,Time,Output_exp1) legend('Input 1','Input 2','Output 1') figure plot(Time,Input_exp2,Time,Output_exp2) legend('Input 1','Input 2','Output 1')


Первый график показывает первый эксперимент, где оператор применяет импульсную волну к каждому входу, чтобы возмущать его от своего установившегося равновесия.
Второй график показывает второй эксперимент, где оператор применяет импульсную волну к первому входу и шаговый сигнал ко второму входу.
Построение графика данных, как описано в Графическом изображении Входных/Выходных Данных, показывает, что входы и выходы имеют ненулевые равновесные значения. В этом фрагменте руководства вы вычитаете равновесные значения из данных.
Причина, по которой вы вычитаете средние значения из каждого сигнала, заключается в том, что, как правило, вы создаете линейные модели, которые описывают отклики на отклонения от физического равновесия. С помощью статических данных разумно предположить, что средние уровни сигналов соответствуют такому равновесию. Таким образом, можно искать модели около нуля, не моделируя абсолютные равновесные уровни в физических единицах измерения.
Увеличьте изображение графиков, чтобы увидеть, что самый ранний момент, когда оператор применяет нарушение порядка к входам, происходит после 25 минут установившихся условий (или после первых 50 выборок). Таким образом, среднее значение первых 50 выборок представляет условия равновесия.
Используйте следующие команды, чтобы удалить равновесные значения из входов и выходов в обоих экспериментах:
Input_exp1 = Input_exp1-... ones(size(Input_exp1,1),1)*mean(Input_exp1(1:50,:)); Output_exp1 = Output_exp1-... mean(Output_exp1(1:50,:)); Input_exp2 = Input_exp2-... ones(size(Input_exp2,1),1)*mean(Input_exp2(1:50,:)); Output_exp2 = Output_exp2-... mean(Output_exp2(1:50,:));
Объекты System Identification Toolbox™ данных, iddata и idfrd, инкапсулируйте значения данных и свойства данных в одну сущность. Можно использовать команды System Identification Toolbox, чтобы удобно манипулировать этими объектами данных как отдельными сущностями.
В этом фрагменте руководства вы создаете два iddata объекты, по одному для каждого из двух экспериментов. Вы используете данные Эксперимента 1 для оценки модели и данные Эксперимента 2 для валидации модели. Вы работаете с двумя независимыми наборами данных, потому что вы используете один набор данных для оценки модели, а другой для валидации модели.
Примечание
Когда два независимых набора данных недоступны, можно разделить один набор данных на две части, принимая, что каждая деталь содержит достаточно информации, чтобы адекватно представлять динамику системы.
Вы, должно быть, уже загрузили выборочные данные в MATLAB® рабочая область, как описано в разделе Загрузка данных в рабочее пространство MATLAB.
Используйте эти команды для создания двух объектов данных, ze и zv :
Ts = 0.5; % Sample time is 0.5 min
ze = iddata(Output_exp1,Input_exp1,Ts);
zv = iddata(Output_exp2,Input_exp2,Ts);
ze содержит данные эксперимента 1 и zv содержит данные эксперимента 2. Ts - шаг расчета.
iddata конструктор требует три аргумента для данных временной области и имеет следующий синтаксис:
data_obj = iddata(output,input,sampling_interval);
Просмотр свойств iddata объект, использовать get команда. Для примера введите эту команду, чтобы получить свойства данных оценки:
get(ze)
ans =
struct with fields:
Domain: 'Time'
Name: ''
OutputData: [2001x1 double]
y: 'Same as OutputData'
OutputName: {'y1'}
OutputUnit: {''}
InputData: [2001x2 double]
u: 'Same as InputData'
InputName: {2x1 cell}
InputUnit: {2x1 cell}
Period: [2x1 double]
InterSample: {2x1 cell}
Ts: 0.5000
Tstart: []
SamplingInstants: [2001x0 double]
TimeUnit: 'seconds'
ExperimentName: 'Exp1'
Notes: {}
UserData: []
Чтобы узнать больше о свойствах этого объекта данных, смотрите iddata страница с описанием.
Для изменения свойств данных можно использовать запись через точку или set команда. Для примера, чтобы назначить имена каналов и модулей, которые маркируют оси графика, введите следующий синтаксис в Командном окне MATLAB:
% Set time units to minutes ze.TimeUnit = 'min'; % Set names of input channels ze.InputName = {'ConsumptionRate','Current'}; % Set units for input variables ze.InputUnit = {'kg/min','A'}; % Set name of output channel ze.OutputName = 'Production'; % Set unit of output channel ze.OutputUnit = 'mg/min'; % Set validation data properties zv.TimeUnit = 'min'; zv.InputName = {'ConsumptionRate','Current'}; zv.InputUnit = {'kg/min','A'}; zv.OutputName = 'Production'; zv.OutputUnit = 'mg/min';
Можно проверить, что InputName свойство ze изменяется или «index» в это свойство:
ze.inputname;
Совет
Имена свойства, такие как InputUnit, не чувствительны к регистру. Можно также сокращать имена свойства, начинающиеся с Input или Output путем подстановки u для Input и y для Output в имени свойства. Для примера, OutputUnit эквивалентно yunit.
Можно построить график iddata объекты, использующие plot команда.
Постройте график данных оценки.
plot(ze)

Нижние оси показывают входы ConsumptionRate и Current, и верхние оси показывают выходные ProductionRate .
Постройте график данных валидации в новом окне рисунка.
figure % Open a new MATLAB Figure window plot(zv) % Plot the validation data

Увеличьте изображение графиков, чтобы увидеть, что процесс эксперимента усиливает первый вход (ConsumptionRate ) в 2 раза и усиливает второй вход (Current ) в 10 раз.
Прежде чем вы начнете, создайте новый набор данных, который содержит только первые 1000 выборок исходных наборов данных оценки и валидации, чтобы ускорить вычисления.
Ze1 = ze(1:1000); Zv1 = zv(1:1000);
Для получения дополнительной информации об индексации в iddata объекты соответствующую страницу с описанием.
Частотная характеристика и переходная характеристика являются непараметрическими моделями, которые могут помочь вам понять динамические характеристики вашей системы. Эти модели не представлены компактной математической формулой с регулируемыми параметрами. Вместо этого они состоят из таблиц данных.
В этом фрагменте руководства вы оцениваете эти модели с помощью набора данных ze. Вы, должно быть, уже создали ze, как описано в разделе Создание объектов iddata.
Графики отклика из этих моделей показывают следующие характеристики системы:
Ответ от первого входа на выход может быть функцией второго порядка.
Ответ от второго входа на выход может быть функцией первого порядка или передувкой.
Продукт System Identification Toolbox обеспечивает три функции для оценки частотной характеристики:
Использование spa для оценки частотной характеристики.
Ge = spa(ze);
Постройте график частотной характеристики как диаграмма Боде.
bode(Ge)

Амплитудные достигать максимума на частоте 0,54 рад/мин, что предполагает возможное резонансное поведение (комплексные полюсы) для первой комбинации вход-выход - ConsumptionRate на Production .
На обоих графиках фаза быстро откатывается, что предполагает задержку времени для обеих комбинаций вход/выход.
Чтобы оценить переходную характеристику из данных, сначала оцените непараметрическую модель импульсной характеристики (конечная импульсная характеристика фильтр) из данных, а затем постройте график ее переходной характеристики.
% model estimation Mimp = impulseest(Ze1,60); % step response step(Mimp)

Переходная характеристика для первой комбинации вход/выход предполагает перерегулирование, которое указывает на наличие недостаточно демпфированного режима (сложных полюсов) в физической системе.
Переходная характеристика от второго входа к выходу не показывает перерегулирования, что указывает или на ответ первого порядка, или на ответ более высокого порядка с реальными полюсами (перезаданный ответ).
Это переходный процесс указывает на ненулевую задержку в системе, которая согласуется с быстрым срывом фазы, который вы получили в Диаграмму Боде, которую вы создали в Оценке Эмпирической Переходной характеристики.
Чтобы идентифицировать параметрические модели черного ящика, необходимо задать задержку ввода/вывода как часть порядка модели.
Если вы не знаете задержек ввода/вывода для вашей системы из эксперимента, можно использовать программное обеспечение System Identification Toolbox, чтобы оценить задержку.
В случае систем с одним входом можно считать задержку на графике импульсной характеристики. Однако в случае систем с несколькими входами, таких как в этом руководстве, вы можете не сказать, какой вход вызвал начальное изменение выхода, и вы можете использовать delayest вместо этого команда.
Команда оценивает временную задержку в динамической системе, оценивая модель ARX низкого порядка в дискретном времени с областью значений задержек, а затем выбирая задержку, соответствующую наилучшей подгонке.
Структура модели ARX является одной из простейших параметрических структур черного ящика. В дискретном времени структура ARX является разностным уравнением со следующей формой:
y (t) представляет выход в момент t, u (t) представляет вход в момент t, na - количество полюсов, nb - количество b параметров (равное количеству нулей плюс 1), nk - количество выборок перед тем, как вход влияет на выход системы (называется задержкой или потерей времени модели), и e (t) является нарушением порядка белого шума.
delayest принимает, что na = nb = 2 и что шум e белый или незначительный, и оценивает nk.
Чтобы оценить задержку в этой системе, введите:
delayest(ze)
ans =
5 10
Этот результат включает два числа, потому что существует два входа: предполагаемая задержка для первого входа 5 выборки данных и предполагаемая задержка для второго входа 10 выборки данных. Потому что шаг расчета для экспериментов 0.5 min, это соответствует 2.5 -min задержка перед тем, как первый вход влияет на выход, и 5.0 -min задержка перед тем, как второй вход влияет на выход.
Существует два альтернативных метода оценки временной задержки в системе:
Постройте график времени входных и выходных данных и считайте различие времени между первым изменением входа и первым изменением выхода. Этот метод практичен только для системы с одним входом/одним выходом; в случае систем с несколькими входами, вы можете не сказать, какой вход вызвал первоначальное изменение в выходе.
Постройте график импульсной характеристики данных с доверительной областью с 1 стандартом отклонения. Можно оценить временную задержку, используя время, когда импульсная характеристика сначала находится вне области доверия.
Порядок модели является одним или несколькими целыми числами, которые определяют сложность модели. В целом порядок модели связан с количеством полюсов, количеством нулей и задержкой отклика (время в терминах количества выборок до того, как выход реагирует на вход). Конкретное значение порядка модели зависит от структуры модели.
Чтобы вычислить параметрические модели черного ящика, вы должны предоставить порядок модели в качестве входов. Если вы не знаете порядок своей системы, вы можете оценить его.
После выполнения шагов в этом разделе вы получаете следующие результаты:
Для первой комбинации вход/выход: na = 2, nb = 2 и задержка nk = 5.
Для второй комбинации вход/выход: na = 1, nb = 1 и задержка nk = 10.
Позже вы исследуете различные структуры модели путем определения значений порядка модели, которые являются небольшими изменениями вокруг этих начальных оценок.
В этом фрагменте руководства вы используете struc, arxstruc, и selstruc чтобы оценить и сравнить простые полиномиальные (ARX) модели для области значений порядков моделей и задержек, и выбрать лучшие заказы на основе качества модели.
Следующий список описывает результаты использования каждой команды:
struc создает матрицу комбинаций порядка модели для заданной области значений na, nb и nk.
arxstruc принимает выход из struc, систематически оценивает модель ARX для каждого порядка модели и сравнивает выход модели с измеренным выходом. arxstruc возвращает функцию потерь для каждой модели, которая является нормированной суммой квадратов ошибок предсказания.
selstruc принимает выход из arxstruc и открывает окно Выбор структуры модели ARX, которое напоминает следующий рисунок, чтобы помочь вам выбрать порядок модели.
Этот график используется для выбора оптимальной модели.
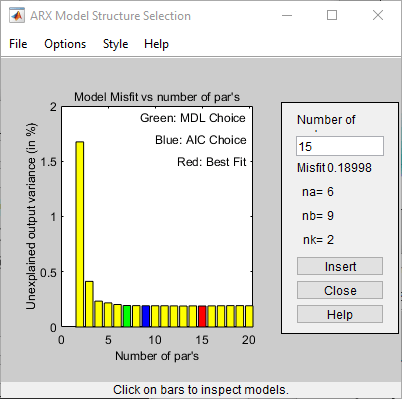
Горизонтальная ось - это общее количество параметров - na + nb.
Вертикальная ось, называемая Unexplained output variance (in %), является фрагментом выхода, не объясняемой моделью - ошибкой предсказания модели ARX для количества параметров, показанных на горизонтальной оси.
Ошибка предсказания является суммой квадратов различий между выходными данными валидации и прогнозируемым выходом модели на один шаг вперед.
nk - задержка.
Три прямоугольника подсвечены на графике зеленым, синим и красным цветом. Каждый цвет указывает тип критерия наилучшего соответствия следующим образом:
Красный - Лучшая подгонка минимизирует сумму квадратов различия между выходными данными валидации и выходами модели. Этот прямоугольник указывает общую лучшую подгонку.
Зеленый - лучшая подгонка минимизирует критерий Rissanen MDL.
Blue - Best fit минимизирует критерий AIC Акайке.
В этом руководстве значение Unexplained output variance (in %) остается приблизительно постоянным для совокупного числа параметров от 4 до 20. Такое постоянство указывает, что производительность модели не улучшается при более высоких порядках. Таким образом, модели низкого порядка могут одинаково хорошо соответствовать данным.
Примечание
При использовании того же набора данных для оценки и валидации используйте критерии MDL и AIC для выбора порядков модели. Эти критерии компенсируют сверхподбор кривой, к которой приводит использование слишком большого количества параметров. Для получения дополнительной информации об этих критериях см. selstruc страница с описанием.
В этом руководстве существует два входа в систему и один выход, и вы оцениваете порядки модели для каждой комбинации вход/выход независимо. Можно либо оценить задержки от двух входов одновременно, либо по одному входу за раз.
Имеет смысл попробовать следующие комбинации порядка для первой комбинации вход/выход:
na = 2:5
nb = 1:5
nk = 5
Это связано с тем, что непараметрические модели, которые вы оценили в Оценке моделей импульсной характеристики, показывают, что реакция для первой комбинации вход/выход может иметь ответ второго порядка. Точно так же при оценке задержек в системе с несколькими входами задержка для этой комбинации вход/выход была оценена как 5.
Чтобы оценить порядок модели для первой комбинации вход/выход:
Использовать struc для создания матрицы возможных порядков моделей.
NN1 = struc(2:5,1:5,5);
Использовать selstruc вычислить функции потерь для моделей ARX с порядками в NN1.
selstruc(arxstruc(ze(:,:,1),zv(:,:,1),NN1))
Примечание
ze(:,:,1) выбирает первый вход в данных.
Эта команда открывает интерактивное окно Выбор структуры модели ARX.
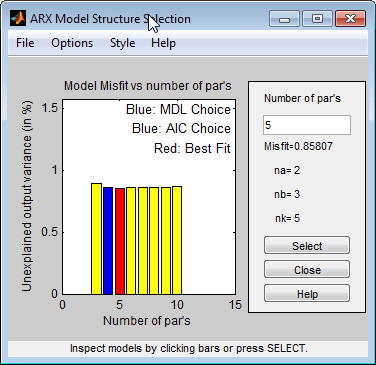
Примечание
Критерии Rissanen MDL и Akaike AIC дают эквивалентные результаты и оба обозначаются синим прямоугольником на графике.
Красный прямоугольник представляет лучшую общую подгонку, которое происходит при na = 2, nb = 3 и nk = 5. Различие высот между красным и синим прямоугольниками незначительно. Поэтому можно выбрать комбинацию параметров, которая соответствует самому низкому порядку модели и самой простой модели.
Щелкните синий прямоугольник, а затем щелкните Select, чтобы выбрать эту комбинацию порядков:
na = 2
nb = 2
nk = 5
Для продолжения нажмите любую клавишу в Командном Окне MATLAB.
Имеет смысл попробовать следующие комбинации порядка для второй комбинации вход/выход:
na = 1:3
nb = 1:3
nk = 10
Это связано с тем, что непараметрические модели, которые вы оценили в Оценке моделей импульсной характеристики, показывают, что реакция для второй комбинации вход/выход может иметь ответ первого порядка. Точно так же при оценке задержек в системе с несколькими входами задержка для этой комбинации вход/выход была оценена в 10.
Чтобы оценить порядок модели для второй комбинации вход/выход:
Использовать struc для создания матрицы возможных порядков моделей.
NN2 = struc(1:3,1:3,10);
Использовать selstruc вычислить функции потерь для моделей ARX с порядками в NN2.
selstruc(arxstruc(ze(:,:,2),zv(:,:,2),NN2))
Эта команда открывает интерактивное окно Выбор структуры модели ARX.
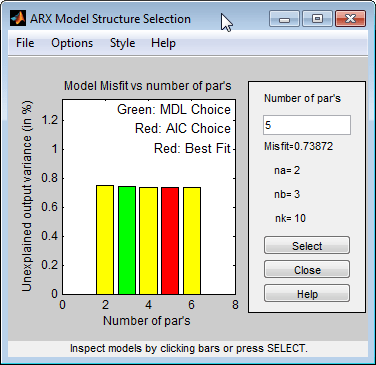
Примечание
Akaike AIC и общие критерии наилучшей подгонки дают эквивалентные результаты. Оба обозначены одним и тем же красным прямоугольником на графике.
Различие высот всех прямоугольников незначительно, и все эти порядки модели приводят к сходной производительности модели. Поэтому можно выбрать комбинацию параметров, которая соответствует самому низкому порядку модели и самой простой модели.
Щелкните желтый прямоугольник в крайнем левом углу, а затем щелкните Select, чтобы выбрать самый низкий порядок: na = 1, nb = 1 и nk = 10.
Для продолжения нажмите любую клавишу в Командном Окне MATLAB.
В этом фрагменте руководства вы оцениваете передаточную функцию в непрерывном времени. Вы, должно быть, уже подготовили свои данные, как описано в разделе Подготовка данных. Для определения порядков модели можно использовать следующие результаты оценочных заказов модели:
Для первой комбинации вход/выход используйте:
Два полюса, соответствующих na=2 в модели ARX.
Задержка 5, соответствующая nk=5 выборки (или 2,5 минуты) в модели ARX.
Для второй комбинации вход/выход используйте:
Один полюс, соответствующий na=1 в модели ARX
Задержка 10, соответствующая nk=10 выборки (или 5 минуты) в модели ARX.
Можно оценить передаточную функцию из этих порядков, используя tfest команда. Для оценки можно также выбрать просмотр отчета о прогрессе путем установки Display опция для on в наборе опций, созданном tfestOptions команда.
Opt = tfestOptions('Display','on');
Соберите порядки моделей и задержки в переменные, которые будут переданы tfest.
np = [2 1]; ioDelay = [2.5 5];
Оцените передаточную функцию.
mtf = tfest(Ze1,np,[],ioDelay,Opt);

Просмотрите коэффициенты модели.
mtf
mtf =
From input "ConsumptionRate" to output "Production":
-1.382 s + 0.0008305
exp(-2.5*s) * -------------------------
s^2 + 1.014 s + 5.447e-12
From input "Current" to output "Production":
5.93
exp(-5*s) * ----------
s + 0.5858
Continuous-time identified transfer function.
Parameterization:
Number of poles: [2 1] Number of zeros: [1 0]
Number of free coefficients: 6
Use "tfdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using TFEST on time domain data "Ze1".
Fit to estimation data: 78.92%
FPE: 14.22, MSE: 13.97
Отображение модели показывает более 85% подгонки к данным оценки.
В этом фрагменте руководства вы создаете график, который сравнивает фактический выход и выход модели с помощью compare команда.
compare(Zv1,mtf)

Сравнение показывает, что подгонка составляет около 60%.
Используйте resid команда для оценки характеристик невязок.
resid(Zv1,mtf)

Невязки показывают высокую степень автокорреляции. Это не неожиданно с момента создания модели mtf не имеет никаких компонентов, чтобы описать характер шума отдельно. Чтобы смоделировать как измеренную динамику вход-выход, так и динамику нарушения порядка, вам потребуется использовать структуру модели, которая содержит элементы для описания шумового компонента. Можно использовать bj, ssest и procest команды, которые создают модели полиномиальных, пространственно-состояний и технологических структур соответственно. Эти структуры, среди прочих, содержат элементы для захвата шумового поведения.
В этом фрагменте руководства вы оцениваете передаточную функцию низкого порядка и непрерывного времени (модель процесса). продукт System Identification Toolbox поддерживает модели в непрерывном времени с максимум тремя полюсами (которые могут содержать недостаточно демпфированные полюса), одним нулями, элементом задержки и интегратором.
Вы, должно быть, уже подготовили свои данные, как описано в разделе Подготовка данных.
Для определения порядков модели можно использовать следующие результаты оценочных заказов модели:
Для первой комбинации вход/выход используйте:
Два полюса, соответствующий na = 2 в модели ARX.
Задержка 5, соответствующая nk = 5 выборки (или 2,5 минут) в модели ARX.
Для второй комбинации вход/выход используйте:
Один полюс, соответствующий na = 1 в модели ARX.
Задержка 10, соответствующая nk = 10 выборки (или 5 минут) в модели ARX.
Примечание
Поскольку нет связи между количеством нулей, оцененным моделью ARX в дискретном времени, и ее аналогом в непрерывном времени, у вас нет оценки количества нулей. В этом руководстве можно задать один ноль для первой комбинации вход/выход, и нет нуля для комбинации второй вывод.
Используйте idproc команда для создания двух структур модели, по одной для каждой комбинации вход/выход:
midproc0 = idproc({'P2ZUD','P1D'}, 'TimeUnit', 'minutes');
Массив ячеек {'P2ZUD','P1D'} задает структуру модели для каждой комбинации вход/выход:
'P2ZUD' представляет передаточную функцию с двумя полюсами (P2 ), один нуль (Z ), недостаточно демпфированные (комплексно-сопряженные) полюсы (U ) и задержку (D ).
'P1D' представляет передаточную функцию с одним полюсом (P1 ) и задержку (D ).
В примере также используется TimeUnit параметр для определения модуля времени, используемой.
Просмотрите две получившиеся модели.
midproc0
midproc0 =
Process model with 2 inputs: y = G11(s)u1 + G12(s)u2
From input 1 to output 1:
1+Tz*s
G11(s) = Kp * ---------------------- * exp(-Td*s)
1+2*Zeta*Tw*s+(Tw*s)^2
Kp = NaN
Tw = NaN
Zeta = NaN
Td = NaN
Tz = NaN
From input 2 to output 1:
Kp
G12(s) = ---------- * exp(-Td*s)
1+Tp1*s
Kp = NaN
Tp1 = NaN
Td = NaN
Parameterization:
{'P2DUZ'} {'P1D'}
Number of free coefficients: 8
Use "getpvec", "getcov" for parameters and their uncertainties.
Status:
Created by direct construction or transformation. Not estimated.
Значения параметров установлены в NaN потому что они еще не оценены.
Установите свойство задержки по времени для объекта модели в 2.5 мин и 5 min для каждой входной/выходной пары в качестве начальных догадок. Кроме того, установите верхний предел задержки, потому что доступны хорошие начальные предположения.
midproc0.Structure(1,1).Td.Value = 2.5; midproc0.Structure(1,2).Td.Value = 5; midproc0.Structure(1,1).Td.Maximum = 3; midproc0.Structure(1,2).Td.Maximum = 7;
Примечание
При установке ограничений задержки необходимо задать задержки с точки зрения фактических временных модулей (минуты, в этом случае), а не количества выборок.
procest является итерационным оценщиком моделей процессов, что означает, что он использует итерационный алгоритм нелинейного метода наименьших квадратов для минимизации функции затрат. Функция стоимости является взвешенной суммой квадратов ошибок.
В зависимости от его аргументов, procest оценивает различные модели черного полинома. Можно использовать procestдля примера оценить параметры для структур линейного непрерывного времени передаточной функции, пространства состояний или полиномиальной модели. Как использовать procestнеобходимо предоставить структуру модели с неизвестными параметрами и данные оценки в качестве входных параметров.
Для этого фрагмента руководства необходимо уже определить структуру модели, как описано в разделе «Определение структуры модели процесса». Использование midproc0 как структура модели и Ze1 как данные оценки:
midproc = procest(Ze1,midproc0); present(midproc)
midproc =
Process model with 2 inputs: y = G11(s)u1 + G12(s)u2
From input "ConsumptionRate" to output "Production":
1+Tz*s
G11(s) = Kp * ---------------------- * exp(-Td*s)
1+2*Zeta*Tw*s+(Tw*s)^2
Kp = -1.1807 +/- 0.29987
Tw = 1.6437 +/- 714.6
Zeta = 16.036 +/- 6958.9
Td = 2.426 +/- 64.276
Tz = -109.19 +/- 63.738
From input "Current" to output "Production":
Kp
G12(s) = ---------- * exp(-Td*s)
1+Tp1*s
Kp = 10.264 +/- 0.048404
Tp1 = 2.049 +/- 0.054901
Td = 4.9175 +/- 0.034374
Parameterization:
{'P2DUZ'} {'P1D'}
Number of free coefficients: 8
Use "getpvec", "getcov" for parameters and their uncertainties.
Status:
Termination condition: Maximum number of iterations reached..
Number of iterations: 20, Number of function evaluations: 279
Estimated using PROCEST on time domain data "Ze1".
Fit to estimation data: 86.2%
FPE: 6.081, MSE: 5.984
More information in model's "Report" property.
В отличие от моделей полинома в дискретном времени, модели в непрерывном времени позволяют вам оценить задержки. В этом случае предполагаемые значения задержки отличаются от начальных догадок, которые вы задали 2.5 и 5 , соответственно. Большие неопределенности в оценочных значениях параметров G_1(s) указать, что динамика от входных 1 к выходу не захватываются хорошо.
Чтобы узнать больше об оценке моделей, см. «Модели процесса».
В этом фрагменте руководства вы создаете график, который сравнивает фактический выход и выход модели.
compare(Zv1,midproc)

График показывает, что результат модели разумно согласен с измеренным выходом: существует согласие 60% между моделью и данными валидации.
Использование resid для выполнения остаточного анализа.
resid(Zv1,midproc)

Перекрестная корреляция между второй входной и остаточной ошибками значительна. Автокорреляционный график показывает значения за пределами доверительной области и указывает, что невязки коррелируются.
Измените алгоритм итерационной оценки параметра на Левенберг-Марквардт.
Opt = procestOptions;
Opt.SearchMethod = 'lm';
midproc1 = procest(Ze1,midproc,Opt);
Корректировка свойств алгоритма или установка начальных догадок параметра и повторное выполнение оценки могут улучшить результаты симуляции. Добавление модели шума может улучшить результаты предсказания, но не обязательно результаты симуляции.
Этот фрагмент руководства показывает, как оценить модель процесса и включить модель шума в оценку. Включение шумовой модели обычно улучшает результаты предсказания модели, но не обязательно результаты симуляции.
Используйте следующие команды, чтобы задать шум ARMA первого порядка:
Opt = procestOptions;
Opt.DisturbanceModel = 'ARMA1';
midproc2 = procest(Ze1,midproc0,Opt);
Можно вводить 'dist' вместо 'DisturbanceModel'. Имена свойства не чувствительны к регистру, и вы должны включать только фрагмент имени, которая уникально идентифицирует свойство.
Сравните полученную модель с измеренными данными.
compare(Zv1,midproc2)

График показывает, что выход модели поддерживает разумное согласие с выходными данными валидации.
Выполните остаточный анализ.
resid(Zv1,midproc2)

Остаточный график показывает, что значения автокорреляции находятся внутри доверительных границ. Таким образом, добавление модели шума производит некоррелированные невязки. Это указывает на более точную модель.
В этом фрагменте руководства вы оцениваете несколько различных типов черно-коробочных, входно-выходных полиномиальных моделей.
Вы, должно быть, уже подготовили свои данные, как описано в разделе Подготовка данных.
Можно использовать следующие предыдущие результаты оценочных порядков модели, чтобы задать порядки полиномиальной модели:
Для первой комбинации вход/выход используйте:
Два полюса, соответствующий na = 2 в модели ARX.
Один нуль, соответствующий nb = 2 в модели ARX.
Задержка 5, соответствующая nk = 5 выборки (или 2,5 минут) в модели ARX.
Для второй комбинации вход/выход используйте:
Один полюс, соответствующий na = 1 в модели ARX.
Нет нулей, соответствующих nb = 1 в модели ARX.
Задержка 10, соответствующая nk = 10 выборки (или 5 минут) в модели ARX.
О моделях ARX. Для системы с одним входом/одним выходом (SISO), структура модели ARX:
y (t) представляет вывод в момент t, u (t) представляет вход в момент t, na - количество полюсов, nb - количество нулей плюс 1, nk - количество выборок перед тем, как вход влияет на выход системы (называемый задержкой или потерей времени модели), и e (t) - нарушение порядка белого шума.
Структура модели ARX не различает полюсы для отдельных входных/выходных путей: деление уравнения ARX на A, которое содержит полюсы, показывает, что A появляется в знаменателе для обоих входов. Поэтому можно задать na в сумме полюсов для каждой пары вход/выход, которая равна 3 в этом случае.
Продукт System Identification Toolbox оценивает параметры и используя заданные данные и порядок модели.
Оценка моделей ARX с использованием arx. Использовать arx чтобы вычислить полиномиальные коэффициенты с помощью быстрого, нежесткого метода arx:
marx = arx(Ze1,'na',3,'nb',[2 1],'nk',[5 10]); present(marx) % Displays model parameters % with uncertainty information
marx =
Discrete-time ARX model: A(z)y(t) = B(z)u(t) + e(t)
A(z) = 1 - 1.027 (+/- 0.02907) z^-1 + 0.1678 (+/- 0.042) z^-2 + 0.01289 (
+/- 0.02583) z^-3
B1(z) = 1.86 (+/- 0.189) z^-5 - 1.608 (+/- 0.1888) z^-6
B2(z) = 1.612 (+/- 0.07392) z^-10
Sample time: 0.5 minutes
Parameterization:
Polynomial orders: na=3 nb=[2 1] nk=[5 10]
Number of free coefficients: 6
Use "polydata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using ARX on time domain data "Ze1".
Fit to estimation data: 90.7% (prediction focus)
FPE: 2.768, MSE: 2.719
More information in model's "Report" property.
MATLAB оценивает полиномы A , B1 , и B2. Неопределенность для каждого из параметров модели вычисляется как 1 стандартное отклонение и появляется в круглых скобках рядом с каждым значением параметров.
Кроме того, можно использовать следующий синтаксис стенограммы и задать порядки модели как один вектор:
marx = arx(Ze1,[3 2 1 5 10]);
Доступ к данным моделям. Модель, которую вы оценили, marx, является дискретным временем idpoly объект. Чтобы получить свойства этого объекта модели, можно использовать get функция:
get(marx)
A: [1 -1.0267 0.1678 0.0129]
B: {[0 0 0 0 0 1.8599 -1.6084] [0 0 0 0 0 0 0 0 0 0 1.6118]}
C: 1
D: 1
F: {[1] [1]}
IntegrateNoise: 0
Variable: 'z^-1'
IODelay: [0 0]
Structure: [1x1 pmodel.polynomial]
NoiseVariance: 2.7436
InputDelay: [2x1 double]
OutputDelay: 0
Ts: 0.5000
TimeUnit: 'minutes'
InputName: {2x1 cell}
InputUnit: {2x1 cell}
InputGroup: [1x1 struct]
OutputName: {'Production'}
OutputUnit: {'mg/min'}
OutputGroup: [1x1 struct]
Notes: [0x1 string]
UserData: []
Name: ''
SamplingGrid: [1x1 struct]
Report: [1x1 idresults.arx]
Вы можете получить доступ к информации, хранимой этими свойствами, используя запись через точку. Для примера можно вычислить дискретные полюсы модели, найдя корни A полином.
marx_poles = roots(marx.a)
marx_poles =
0.7953
0.2877
-0.0564
В этом случае вы получаете доступ к A полином с использованием marx.a.
Модель marx описывает динамику системы с помощью трех дискретных полюсов.
Совет
Вы также можете использовать pole для непосредственного вычисления полюсов модели.
Подробнее. Чтобы узнать больше об оценке полиномиальных моделей, см. «Входно-выходные полиномиальные модели».
Для получения дополнительной информации о доступе к данным данных моделей Раздел «Извлечение данных».
О моделях пространства состояний. Общая структура модели пространства состояний:
y (t) представляет выход в момент t, u (t) представляет вход в момент t, x (t) является вектором состояния в момент t, а e (t) является нарушением порядка белого шума.
Необходимо задать одно целое число в качестве порядка модели (размерность вектора состояния), чтобы оценить модель пространства состояний. По умолчанию задержка равна 1.
Продукт System Identification Toolbox оценивает матрицы А, B, C, D и K пространства состояний, используя порядок модели и заданные вами данные.
Структура модели пространства состояний является хорошим выбором для быстрой оценки, потому что она содержит только два параметра: n количество полюсов (размер матрицы A) и nk - задержка.
Оценка моделей пространства состояний с использованием n4sid. Используйте n4sid команда для определения области значений порядков моделей и оценки эффективности нескольких моделей пространства состояний (порядки 2-8):
mn4sid = n4sid(Ze1,2:8,'InputDelay',[4 9]);Эта команда использует быстрый, нежесткий (подпространство) метод и открывает следующий график. Вы используете этот график, чтобы решить, какие состояния обеспечивают значительный относительный вклад в поведение ввода/вывода, и какие состояния обеспечивают наименьший вклад.
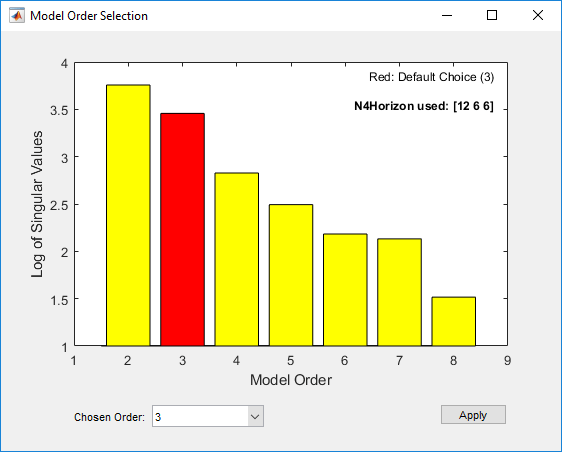
Вертикальная ось является относительной мерой того, насколько каждое состояние способствует поведению ввода/вывода модели (журнал сингулярных значений ковариационной матрицы). Горизонтальная ось соответствует порядку модели n. Этот график рекомендует n=3, обозначенный красным прямоугольником.
В поле порядка Chosen Order отображается рекомендуемый порядок модели, 3 в этом случае по умолчанию. Выбор порядка можно изменить с помощью раскрывающегося списка Chosen Order. Примените значение в поле Chosen Order и закройте окно выбора заказа нажав Apply.
По умолчанию n4sid использует свободную параметризацию формы пространство состояний. Чтобы оценить каноническую форму, установите значение SSParameterization свойство к 'Canonical' . Можно также задать задержку ввода-вывода (в выборках), используя 'InputDelay' свойство.
mCanonical = n4sid(Ze1,3,'SSParameterization','canonical','InputDelay',[4 9]); present(mCanonical); % Display model properties
mCanonical =
Discrete-time identified state-space model:
x(t+Ts) = A x(t) + B u(t) + K e(t)
y(t) = C x(t) + D u(t) + e(t)
A =
x1 x2 x3
x1 0 1 0
x2 0 0 1
x3 0.0737 +/- 0.05919 -0.6093 +/- 0.1626 1.446 +/- 0.1287
B =
ConsumptionR Current
x1 1.844 +/- 0.175 0.5633 +/- 0.122
x2 1.063 +/- 0.1673 2.308 +/- 0.1222
x3 0.2779 +/- 0.09615 1.878 +/- 0.1058
C =
x1 x2 x3
Production 1 0 0
D =
ConsumptionR Current
Production 0 0
K =
Production
x1 0.8674 +/- 0.03169
x2 0.6849 +/- 0.04145
x3 0.5105 +/- 0.04352
Input delays (sampling periods): 4 9
Sample time: 0.5 minutes
Parameterization:
CANONICAL form with indices: 3.
Feedthrough: none
Disturbance component: estimate
Number of free coefficients: 12
Use "idssdata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Estimated using N4SID on time domain data "Ze1".
Fit to estimation data: 91.39% (prediction focus)
FPE: 2.402, MSE: 2.331
More information in model's "Report" property.
Примечание
mn4sid и mCanonical являются моделями в дискретном времени. Чтобы оценить модель в непрерывном времени, установите 'Ts' свойство к 0 в команде оценки или используйте ssest команда:
mCT1 = n4sid(Ze1, 3, 'Ts', 0, 'InputDelay', [2.5 5]) mCT2 = ssest(Ze1, 3,'InputDelay', [2.5 5])
Подробнее. Чтобы узнать больше об оценке моделей пространства состояний, смотрите Модели пространства состояний.
О моделях Бокса-Дженкинса. Общая структура Box-Jenkins (BJ):
Чтобы оценить модель BJ, необходимо задать параметры nb, nf, nc, nd и nk.
В то время как структура модели ARX не различает полюсы для отдельных входных/выходных путей, модель BJ обеспечивает большую гибкость в моделировании полюсов и нулей нарушения порядка отдельно от полюсов и нулей динамики системы.
Оценка модели BJ с использованием полиеста. Вы можете использовать polyest для оценки модели BJ. polyest является итерационным методом и имеет следующий общий синтаксис:
polyest(data,[na nb nc nd nf nk]);
Чтобы оценить модель BJ, введите:
na = 0; nb = [ 2 1 ]; nc = 1; nd = 1; nf = [ 2 1 ]; nk = [ 5 10]; mbj = polyest(Ze1,[na nb nc nd nf nk]);
Эта команда задает nf=2 , nb=2 , nk=5 для первого входа и nf=nb=1 и nk=10 для второго входа.
Отобразите информацию о модели.
present(mbj)
mbj =
Discrete-time BJ model: y(t) = [B(z)/F(z)]u(t) + [C(z)/D(z)]e(t)
B1(z) = 1.823 (+/- 0.1792) z^-5 - 1.315 (+/- 0.2367) z^-6
B2(z) = 1.791 (+/- 0.06431) z^-10
C(z) = 1 + 0.1068 (+/- 0.04009) z^-1
D(z) = 1 - 0.7452 (+/- 0.02694) z^-1
F1(z) = 1 - 1.321 (+/- 0.06936) z^-1 + 0.5911 (+/- 0.05514) z^-2
F2(z) = 1 - 0.8314 (+/- 0.006441) z^-1
Sample time: 0.5 minutes
Parameterization:
Polynomial orders: nb=[2 1] nc=1 nd=1 nf=[2 1]
nk=[5 10]
Number of free coefficients: 8
Use "polydata", "getpvec", "getcov" for parameters and their uncertainties.
Status:
Termination condition: Near (local) minimum, (norm(g) < tol)..
Number of iterations: 6, Number of function evaluations: 13
Estimated using POLYEST on time domain data "Ze1".
Fit to estimation data: 90.75% (prediction focus)
FPE: 2.733, MSE: 2.689
More information in model's "Report" property.
Неопределенность для каждого из параметров модели вычисляется как 1 стандартное отклонение и появляется в круглых скобках рядом с каждым значением параметров.
Полиномы C и D дать числитель и знаменатель шумовой модели, соответственно.
Совет
Кроме того, можно использовать следующий синтаксис стенограммы, который задает порядки как один вектор:
mbj = bj(Ze1,[2 1 1 1 2 1 5 10]);
bj является версией polyest который специально оценивает структуру модели BJ.
Подробнее. Чтобы узнать больше об идентификации моделей полинома ввода-вывода, таких как BJ, смотрите Модели Полинома ввода-вывода.
Сравните выходные данные моделей ARX, пространства состояний и Box-Jenkins с измеренным выходом.
compare(Zv1,marx,mn4sid,mbj)

compare строит графики измеренного выхода в наборе данных валидации относительно моделируемого выхода моделей. Входные данные из набора данных валидации служат входными данными для моделей.
Выполните остаточный анализ на моделях ARX, пространства состояний и Box-Jenkins.
resid(Zv1,marx,mn4sid,mbj)

Все три модели моделируют выход одинаково хорошо и имеют некоррелированные невязки. Поэтому выберите модель ARX, потому что она является самой простой из трех полиномиальных моделей ввода-вывода и адекватно захватывает динамику процесса.
В этом фрагменте руководства вы симулируете выход модели. Вы, должно быть, уже создали модель непрерывного времени midproc2, как описано в Оценке Моделей Процесса.
Симуляция выхода модели требует следующей информации:
Входные значения в модель
Начальные условия для симуляции (также называемые начальными состояниями)
Например, следующие команды используют iddata и idinput команды для создания набора входных данных и использования sim для симуляции выхода модели:
% Create input for simulation U = iddata([],idinput([200 2]),'Ts',0.5,'TimeUnit','min'); % Simulate the response setting initial conditions equal to zero ysim_1 = sim(midproc2,U);
Чтобы максимизировать подгонку между моделируемой характеристикой модели и измеренным выходом для того же входа, можно вычислить начальные условия, соответствующие измеренным данным. Лучшие подходящие начальные условия могут быть получены при помощи findstates на версии предполагаемой модели в пространстве состояний. Следующие команды оценивают начальные состояния X0est из набора данных Zv1:
% State-space version of the model needed for computing initial states
midproc2_ss = idss(midproc2);
X0est = findstates(midproc2_ss,Zv1);
Затем симулируйте модель с помощью начальных состояний, оцененных из данных.
% Simulation input Usim = Zv1(:,[],:); Opt = simOptions('InitialCondition',X0est); ysim_2 = sim(midproc2_ss,Usim,Opt);
Сравните моделируемый и измеренный выходы на графике.
figure
plot([ysim_2.y, Zv1.y])
legend({'model output','measured'})
xlabel('time'), ylabel('Output')

Многие приложения система управления требуют, чтобы вы предсказали будущие выходы динамической системы, используя прошлые входные/выходные данные.
Для примера используйте predict чтобы предсказать ответ модели на пять шагов вперед:
predict(midproc2,Ze1,5)

Сравните предсказанные выходные значения с измеренными выходными значениями. Третий аргумент compare задает пятиэтапное предсказание. Когда вы не задаете третий аргумент, compare принимает бесконечный горизонт предсказания и симулирует выход модели вместо этого.
compare(Ze1,midproc2,5)

Использовать pe чтобы вычислить ошибку предсказания Err между предсказанным выходом midproc2 и измеренный выход. Затем постройте график спектра ошибок с помощью spectrum команда.
[Err] = pe(midproc2,Zv1); spectrum(spa(Err,[],logspace(-2,2,200)))

Ошибки предсказания строятся с интервалом доверия 1-стандартного отклонения. Ошибки больше на высоких частотах из-за высокочастотной природы нарушения порядка.
