Сценарии симуляции
SimBiology.Scenarios является объектом, который позволяет вам генерировать различные сценарии симуляции на основе различных выборочных значений величин модели. Можно объединить эти величины с различными дозами или вариантами и моделировать различные сценарии, чтобы исследовать поведение модели в различных экспериментальных условиях и режимах дозирования.
sObj = SimBiology.Scenarios(name,content)Scenarios sObj объекта с одной записью. name - имя величины модели или имя группы вариантов или доз для генерации сценария. content содержит соответствующие числовые значения для величины модели или вектора вариантов объектов или вектора объектов дозы.
sObj = SimBiology.Scenarios(quantityNames,probDist,Name,Value)quantityNames от совместного распределения вероятностей probDist. Задайте дополнительные опции для распределений вероятностей и метода дискретизации, используя один или несколько аргументы пары "имя-значение". Чтобы задать распределения вероятностей, вы должны иметь Statistics and Machine Learning Toolbox™.
add | Добавьте значения количества, дозы или варианты к SimBiology.Scenarios объект |
getEntry | Получение содержимого записи из SimBiology.Scenarios объект |
updateEntry | Обновление содержимого записи из SimBiology.Scenarios объект |
rename | Переименуйте запись из SimBiology.Scenarios объект |
remove | Удаление записей из SimBiology.Scenarios объект |
verify | Проверьте SimBiology.Scenarios объект |
generate | Сгенерируйте сценарии из SimBiology.Scenarios объект и таблица возврата |
getNumberScenarios | Возвращает количество сценариев из SimBiology.Scenarios объект |
Загрузите модель глюкозо-инсулиновой реакции. Для получения дополнительной информации о модели смотрите раздел «Фон» в Симуляции ответа глюкозы-инсулина.
sbioloadproject('insulindemo','m1');
Модель содержит различные значения параметров и начальные условия, которые представляют различные нарушения инсулина (такие как диабет 2 типа, низкая чувствительность к инсулину и так далее), сохраненные в пяти вариантах.
variants = getvariant(m1)
variants = SimBiology Variant Array Index: Name: Active: 1 Type 2 diabetic false 2 Low insulin se... false 3 High beta cell... false 4 Low beta cell ... false 5 High insulin s... false
Подавить информационное предупреждение, которое выдается во время симуляций.
warnSettings = warning('off','SimBiology:DimAnalysisNotDone_MatlabFcn_Dimensionless');
Выберите дозу, которая представляет один прием пищи 78 граммов глюкозы.
singleMeal = sbioselect(m1,'Name','Single Meal');
Создайте Scenarios объект для представления различных начальных условий в сочетании с дозой. То есть создайте scenario объект, где каждый вариант спарен (или объединен) с дозой, для в общей сложности пяти сценариев симуляции.
sObj = SimBiology.Scenarios; add(sObj,'cartesian','variants',variants); add(sObj,'cartesian','dose',singleMeal)
ans =
Scenarios (5 scenarios)
Name Content Number
________ ___________________ ______
Entry 1 variants SimBiology variants 5
x Entry 2 dose SimBiology dose 1
See also Expression property.
sObj содержит две записи. Используйте generate функция для объединения записей и генерации пяти сценариев. Функция возвращает таблицу сценариев, где каждая строка представляет сценарий, а каждый столбец представляет запись Scenarios объект.
scenariosTbl = generate(sObj)
scenariosTbl=5×2 table
variants dose
________________________ ___________________________
[1x1 SimBiology.Variant] [1x1 SimBiology.RepeatDose]
[1x1 SimBiology.Variant] [1x1 SimBiology.RepeatDose]
[1x1 SimBiology.Variant] [1x1 SimBiology.RepeatDose]
[1x1 SimBiology.Variant] [1x1 SimBiology.RepeatDose]
[1x1 SimBiology.Variant] [1x1 SimBiology.RepeatDose]
Измените имя записи первой записи.
rename(sObj,1,'Insulin Impairements')ans =
Scenarios (5 scenarios)
Name Content Number
____________________ ___________________ ______
Entry 1 Insulin Impairements SimBiology variants 5
x Entry 2 dose SimBiology dose 1
See also Expression property.
Создайте SimFunction объект для симуляции сгенерированных сценариев. Используйте Scenarios объект в качестве входов и определения концентраций глюкозы и инсулина в плазме в качестве репонсов (выходы функции, которая будет нанесена). Задайте [] для входного параметра дозы с момента Scenarios объект уже имеет информацию о дозах.
f = createSimFunction(m1,sObj,{'[Plasma Glu Conc]','[Plasma Ins Conc]'},[])f =
SimFunction
Parameters:
Name Value Type Units
____________________________ ______ _____________ ___________________________________________
{'Plasma Volume (Glu)' } 1.88 {'parameter'} {'deciliter' }
{'k1' } 0.065 {'parameter'} {'1/minute' }
{'k2' } 0.079 {'parameter'} {'1/minute' }
{'Plasma Volume (Ins)' } 0.05 {'parameter'} {'liter' }
{'m1' } 0.19 {'parameter'} {'1/minute' }
{'m2' } 0.484 {'parameter'} {'1/minute' }
{'m4' } 0.1936 {'parameter'} {'1/minute' }
{'m5' } 0.0304 {'parameter'} {'minute/picomole' }
{'m6' } 0.6469 {'parameter'} {'dimensionless' }
{'Hepatic Extraction' } 0.6 {'parameter'} {'dimensionless' }
{'kmax' } 0.0558 {'parameter'} {'1/minute' }
{'kmin' } 0.008 {'parameter'} {'1/minute' }
{'kabs' } 0.0568 {'parameter'} {'1/minute' }
{'kgri' } 0 {'parameter'} {'1/minute' }
{'f' } 0.9 {'parameter'} {'dimensionless' }
{'a' } 0 {'parameter'} {'1/milligram' }
{'b' } 0.82 {'parameter'} {'dimensionless' }
{'c' } 0 {'parameter'} {'1/milligram' }
{'d' } 0.01 {'parameter'} {'dimensionless' }
{'Stomach Glu After Dosing'} 78 {'parameter'} {'gram' }
{'kp1' } 2.7 {'parameter'} {'milligram/minute' }
{'kp2' } 0.0021 {'parameter'} {'1/minute' }
{'kp3' } 0.009 {'parameter'} {'(milligram/minute)/(picomole/liter)' }
{'kp4' } 0.0618 {'parameter'} {'(milligram/minute)/picomole' }
{'ki' } 0.0079 {'parameter'} {'1/minute' }
{'[Ins Ind Glu Util]' } 1 {'parameter'} {'milligram/minute' }
{'Vm0' } 2.5129 {'parameter'} {'milligram/minute' }
{'Vmx' } 0.047 {'parameter'} {'(milligram/minute)/(picomole/liter)' }
{'Km' } 225.59 {'parameter'} {'milligram' }
{'p2U' } 0.0331 {'parameter'} {'1/minute' }
{'K' } 2.28 {'parameter'} {'picomole/(milligram/deciliter)' }
{'alpha' } 0.05 {'parameter'} {'1/minute' }
{'beta' } 0.11 {'parameter'} {'(picomole/minute)/(milligram/deciliter)'}
{'gamma' } 0.5 {'parameter'} {'1/minute' }
{'ke1' } 0.0005 {'parameter'} {'1/minute' }
{'ke2' } 339 {'parameter'} {'milligram' }
{'Basal Plasma Glu Conc' } 91.76 {'parameter'} {'milligram/deciliter' }
{'Basal Plasma Ins Conc' } 25.49 {'parameter'} {'picomole/liter' }
Observables:
Name Type Units
_____________________ ___________ _______________________
{'[Plasma Glu Conc]'} {'species'} {'milligram/deciliter'}
{'[Plasma Ins Conc]'} {'species'} {'picomole/liter' }
Dosed:
TargetName TargetDimension
__________ _____________________
{'Dose'} {'Mass (e.g., gram)'}
Симулируйте модель в течение 24 часов и постройте график данных моделирования. Данные содержат пять запуски, где каждый запуск представляет сценарий в объекте Scenarios.
sd = f(sObj,24); sbioplot(sd)

ans =
Axes (SbioPlot) with properties:
XLim: [0 30]
YLim: [0 450]
XScale: 'linear'
YScale: 'linear'
GridLineStyle: '-'
Position: [0.0951 0.1100 0.2521 0.8150]
Units: 'normalized'
Show all properties
Если у вас есть Statistics and Machine Learning Toolbox™, можно также нарисовать выборку значения для величин модели из различных распределений вероятностей. Например, предположим, что параметры Vmx и kp3, которые известны низкой и высокой чувствительностью к инсулину, следуют логнормальному распределению. Можно сгенерировать значения выборки для этих параметров из такого распределения и выполнить скан, чтобы исследовать поведение модели.
Задайте объект лагнормального распределения вероятностей для Vmx.
pd_Vmx = makedist('lognormal')pd_Vmx =
LognormalDistribution
Lognormal distribution
mu = 0
sigma = 1
По определению, параметр mu - среднее значение логарифмических значений. Чтобы изменить значение параметров вокруг базового (модельного) значения параметра, установите mu на log(model_value). Установите стандартное отклонение (сигма) равным 0,2. Для небольшого значения сигмы среднее значение логнормального распределения приблизительно равно log(model_value). Для получения дополнительной информации смотрите Lognormal Distribution (Statistics and Machine Learning Toolbox).
Vmx = sbioselect(m1,'Name','Vmx'); pd_Vmx.mu = log(Vmx.Value); pd_Vmx.sigma = 0.2
pd_Vmx =
LognormalDistribution
Lognormal distribution
mu = -3.05761
sigma = 0.2
Точно так же задайте распределение вероятностей для kp3.
pd_kp3 = makedist('lognormal'); kp3 = sbioselect(m1,'Name','kp3'); pd_kp3.mu = log(kp3.Value); pd_kp3.sigma = 0.2
pd_kp3 =
LognormalDistribution
Lognormal distribution
mu = -4.71053
sigma = 0.2
Теперь задайте совместное распределение вероятностей, чтобы нарисовать выборочные значения для Vmx и kp3 с ранговой корреляцией, чтобы задать некоторую корреляцию между этими двумя параметрами. Обратите внимание, что это предположение корреляции предназначено только для иллюстративных целей этого примера и может не иметь биологического значения.
Сначала удалите запись вариантов (запись 1) из sObj.
remove(sObj,1)
ans =
Scenarios (1 scenarios)
Name Content Number
____ _______________ ______
Entry 1 dose SimBiology dose 1
See also Expression property.
Добавьте запись, которая задает совместное распределение вероятностей с матрицей ранговой корреляции.
add(sObj,'cartesian',["Vmx","kp3"],[pd_Vmx, pd_kp3],'RankCorrelation',[1,0.5;0.5,1])
ans =
Scenarios (2 scenarios)
Name Content Number
____ ______________________ ___________
Entry 1 dose SimBiology dose 1
x (Entry 2.1 Vmx Lognormal distribution 2 (default)
+ Entry 2.2) kp3 Lognormal distribution 2 (default)
See also Expression property.
По умолчанию количество выборок, полученных из распределения соединений, устанавливается равным 2. Увеличьте количество выборок.
updateEntry(sObj,2,'Number',50)ans =
Scenarios (50 scenarios)
Name Content Number
____ ______________________ ______
Entry 1 dose SimBiology dose 1
x (Entry 2.1 Vmx Lognormal distribution 50
+ Entry 2.2) kp3 Lognormal distribution 50
See also Expression property.
Проверьте, что Scenarios объект может быть симулирован с помощью модели. The verify функция выдает ошибку, если какая-либо запись не разрешается однозначно для объекта в модели или содержимое записи имеет несогласованные длины (размеры выборки). Функция выдает предупреждение, если несколько записей разрешаются к одному и тому же объекту в модели.
verify(sObj,m1)
Сгенерируйте сценарии симуляции. Постройте график значений выборки с помощью plotmatrix. Вы можете увидеть значение Vmx изменяется вокруг значения модели 0.047 и значения модели kp3 около 0,009.
sTbl = generate(sObj); [s,ax,bigax,h,hax] = plotmatrix([sTbl.Vmx,sTbl.kp3]); ax(1,1).YLabel.String = "Vmx"; ax(2,1).YLabel.String = "kp3"; ax(2,1).XLabel.String = "Vmx"; ax(2,2).XLabel.String = "kp3";

Симулируйте сценарии с помощью той же SimFunction, что вы создали ранее. Вам не нужно создавать новый объект SimFunction, даже если объект Scenarios был обновлен.
sd2 = f(sObj,24); sbioplot(sd2);

По умолчанию SimBiology использует метод случайной выборки. Можно изменить его на латинскую выборку гиперкуба (или соболь или галтон) для более систематического подхода заполнения пространства.
entry2struct = getEntry(sObj,2)
entry2struct = struct with fields:
Name: {'Vmx' 'kp3'}
Content: [2x1 prob.LognormalDistribution]
Number: 50
RankCorrelation: [2x2 double]
Covariance: []
SamplingMethod: 'random'
entry2struct.SamplingMethod = 'lhs'entry2struct = struct with fields:
Name: {'Vmx' 'kp3'}
Content: [2x1 prob.LognormalDistribution]
Number: 50
RankCorrelation: [2x2 double]
Covariance: []
SamplingMethod: 'lhs'
Теперь можно использовать обновленную структуру для изменения записи 2.
updateEntry(sObj,2,entry2struct)
ans =
Scenarios (50 scenarios)
Name Content Number
____ ______________________ ______
Entry 1 dose SimBiology dose 1
x (Entry 2.1 Vmx Lognormal distribution 50
+ Entry 2.2) kp3 Lognormal distribution 50
See also Expression property.
Визуализация выборочных значений.
sTbl2 = generate(sObj); [s,ax,bigax,h,hax] = plotmatrix([sTbl2.Vmx,sTbl2.kp3]); ax(1,1).YLabel.String = "Vmx"; ax(2,1).YLabel.String = "kp3"; ax(2,1).XLabel.String = "Vmx"; ax(2,2).XLabel.String = "kp3";

Моделируйте сценарии.
sd3 = f(sObj,24); sbioplot(sd3);

Восстановите параметры предупреждения.
warning(warnSettings);
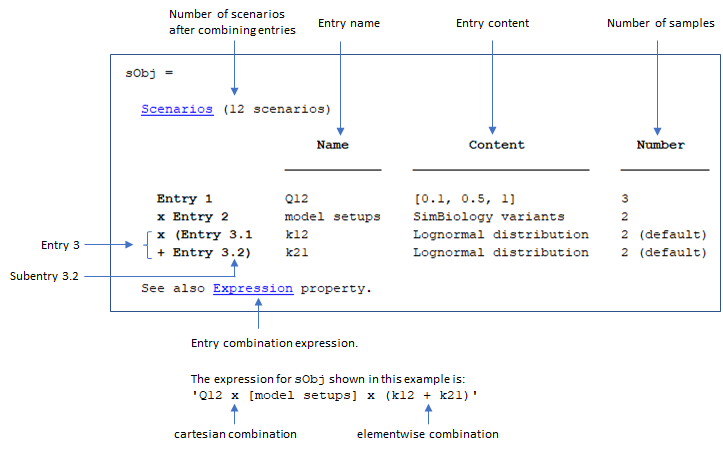
SimBiology.Scenarios ТерминологияВ этом разделе описывается отображение командной строки SimBiology.Scenarios и объясняет условия, показанные в выходах. В частности, в нем объясняются следующие терминологии: Scenarios, Entry, Subentry, Name, Content, Number, Expression, inconsistent и Diagnosis.
Последовательное
Scenarios объект имеет записи, которые имеют правильное количество выборок, так что записи могут быть объединены без ошибок. Пример последовательного Scenarios объект показан следующим.
Несогласованный объект Scenarios имеет одну или несколько записей с неправильным количеством выборок. Необходимо исправить эти записи, прежде чем использовать объект для симуляции. Пример несогласованного объекта показан следующим.

The Diagnosis столбец предлагает, какие записи нужно исправить, чтобы иметь правильное количество выборок. Использовать updateEntry, rename, и remove для редактирования записей.
[1] Иман, Р. и У. Дж. Коновер. 1982. Подход без распределения к индукции ранговой корреляции среди входных переменных. Коммуникации в статистике - симуляция и расчеты. 11(3):311–334.
