Квантили набора данных
Y = quantile(X,p)X для совокупной вероятности или вероятностей p в интервале [0,1].
Если X является вектором, тогда Y - скаляр или вектор, имеющий ту же длину, что и p.
Если X является матрицей, тогда Y - вектор-строка или матрица, где количество строк Y равно длине p.
Для многомерных массивов, quantile действует по первой нежесткой размерности X.
Y = quantile(X,N)N равномерно разнесенные совокупные вероятности (1/( N + 1), 2 / (N + 1)..., N/ (N + 1)) для целого числа N>1.
Если X является вектором, тогда Y является скаляром или вектором с длиной N.
Если X является матрицей, тогда Y - матрица, в которой количество строк Y равно N.
Для многомерных массивов, quantile действует по первой нежесткой размерности X.
Y = quantile(___,vecdim)vecdim для любого из первых двух синтаксисов. Для примера, если X является матрицей, тогда quantile(X,0.5,[1 2]) возвращает 0,5 квантиля всех элементов X потому что каждый элемент массива матрицы содержится в срезе массива, заданном размерностями 1 и 2.
T-digest [2] является вероятностной структурой данных, которая является разреженным представлением эмпирической кумулятивной функции распределения (CDF) набора данных. T-дайджест полезен для вычисления приближений основанной на рангах статистики (таких как процентили и квантили) из онлайновых или распределенных данных таким образом, чтобы это позволяло контролировать точность, особенно вблизи хвостов распределения данных.
Для данных, которые распределены в различных разделах, t-digest вычисляет оценки квантиля (и оценки процентиля) для каждого раздела данных отдельно, а затем объединяет оценки с сохранением постоянной памяти и постоянной относительной точности расчета ( для q-го квантиля). По этим причинам t-digest практичен для работы с длинными массивами.
Чтобы оценить квантования массива, который распределен в различных разделах, сначала создайте t-дайджест в каждом разделе данных. t-digest группирует данные в разделе и суммирует каждый кластер по центроидному значению и накопленному весу, которое представляет количество выборок, вносящих вклад в кластер. T-digest использует большие кластеры (широко разнесенные центроиды), чтобы представлять области CDF, которые близки q = 0.5 и использует небольшие кластеры (плотно расположенные центроиды), чтобы представлять области CDF, которые близки q = 0 или q = 1.
T-digest управляет размером кластера с помощью функции масштабирования, которая сопоставляет q квантования с индексом, k с параметром сжатия . То есть,
где k отображения монотонна с минимальным значением k (0, δ) = 0 и максимальным значением k (1, δ) = δ. Следующий рисунок показывает функцию масштабирования для δ = 10.
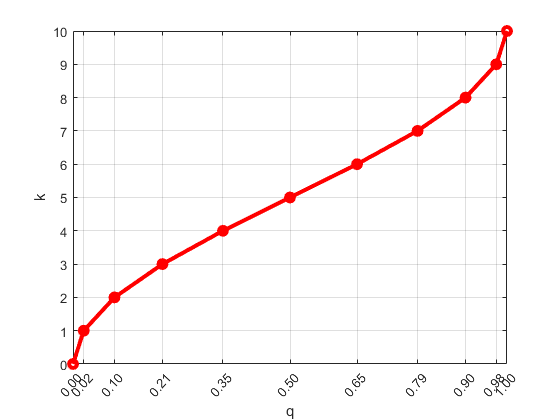
Функция масштабирования переводит q квантования в коэффициент масштабирования k в порядок, чтобы задать шаги переменного размера в q. В результате размеры кластера неравны (больше вокруг центральных величин и меньше вблизи q = 0 или q = 1). Меньшие кластеры обеспечивают лучшую точность вблизи ребер данных.
Чтобы обновить t-дайджест с новым наблюдением, которое имеет вес и расположение, найдите кластер, ближайший к новому наблюдению. Затем прибавьте вес и обновите центроид кластера на основе средневзвешенного среднего значения условии, что обновленный вес кластера не превышает ограничения по размеру.
Можно объединить независимые t-дайджесты из каждого раздела данных, взяв объединение t-дайджестов и объединив их центроиды. Чтобы объединить t-дайджесты, сначала отсортируйте кластеры из всех независимых t-дайджестов в порядке уменьшения весов кластеров. Затем объедините соседние кластеры, когда они удовлетворяют ограничению размера, чтобы сформировать новый t-дайджест.
Если вы формируете t-digest, который представляет полный набор данных, можно оценить конечные точки (или контуры) каждого кластера в t-digest, а затем использовать интерполяцию между конечными точками каждого кластера, чтобы найти точные оценки квантиля.
Для вектора n -element X, quantile вычисляет квантования с помощью основанного на сортировке алгоритма следующим образом:
Отсортированные элементы в X приняты как (0. 5/ n), (1. 5/ n),..., ([n - 0,5 ]/ n) квантили. Для примера:
Для вектора данных из пяти элементов, таких как {6, 3, 2, 10, 1}, отсортированные элементы {1, 2, 3, 6, 10} соответственно соответствуют величинам 0,1, 0,3, 0,5, 0,7, 0,9.
Для вектора данных из шести элементов, таких как {6, 3, 2, 10, 8, 1}, отсортированные элементы {1, 2, 3, 6, 8, 10} соответственно соответствуют (0,5/6), (1,5/6), (2,5/6), (3,5/6), (4,5/6), (5,5/6).
quantile Использует Линейную Интерполяцию, чтобы вычислить квантования для вероятностей между (0 .5/ n) и ([n - 0,5 ]/ n).
Для квантилей, соответствующих вероятностям за пределами этой области значений, quantile присваивает минимальные или максимальные значения элементов в X.
quantile лечит NaNs как отсутствующие значения и удаляет их.
[1] Langford, E. «Quartiles in Elementary Statistics», Journal of Statistics Education. Том 14, № 3, 2006.
