Параметрический подбор кривой включает коэффициенты открытия (параметры) для одной или нескольких моделей, которые вы подбираете к данным. Данные приняты, чтобы быть статистическими по своей природе и разделены на два компонента:
данные = детерминированный компонент + случайный компонент
Детерминированный компонент дан параметрической моделью, и случайный компонент часто описывается как ошибка, сопоставленная с данными:
данные = параметрическая модель + ошибка
Модель является функцией независимого политика (предиктор) переменная и один или несколько коэффициентов. Ошибка представляет случайные изменения данных, которые следуют за определенным вероятностным распределением (обычно Гауссов). Изменения могут прибыть из многих других источников, но всегда присутствуют на некотором уровне, когда вы имеете дело с результатами измерений. Систематические изменения могут также существовать, но они могут привести к подобранной модели, которая не представляет данные хорошо.
Коэффициенты модели часто имеют физическое значение. Например, предположите, что вы собрали данные, которые соответствуют одному режиму затухания радиоактивного нуклида, и вы хотите оценить период полураспада (T 1/2) затухания. Закон радиоактивного затухания утверждает, что действие радиоактивного вещества затухает экспоненциально вовремя. Поэтому моделью, чтобы использовать в подгонке дают
где y 0 является количеством ядер во время t = 0, и λ является постоянным затуханием. Данные могут быть описаны
И y 0 и λ являются коэффициентами, которые оцениваются подгонкой. Поскольку T 1/2 = ln (2)/λ, подходящее значение затухания постоянные выражения подходящий период полураспада. Однако, потому что данные содержат некоторую ошибку, детерминированный компонент уравнения не может быть определен точно из данных. Поэтому коэффициенты и вычисление периода полураспада будут иметь некоторую неопределенность сопоставленной с ними. Если неопределенность приемлема, то вы - сделанная подгонка данных. Если неопределенность не приемлема, то вам придется предпринять шаги, чтобы уменьшать ее или путем сбора большего количества данных или путем сокращения погрешности измерения и сбора новых данных и повторения подгонки модели.
С другими проблемами, где нет никакой теории продиктовать модель, вы можете также изменить модель путем добавления или удаления терминов, или заменить совершенно различной моделью.
Curve Fitting Toolbox™ параметрические модели библиотеки описан в следующих разделах.
Выберите тип модели, чтобы соответствовать из выпадающего списка в приложении Curve Fitting.
Какие подходящие типы можно использовать для кривых или поверхностей? На основе ваших выбранных данных подходящий список категорий показывает или кривую или поверхностные категории. Следующая таблица описывает опции для кривых и поверхностей.
| Подходящая категория | Кривые | Поверхности |
|---|---|---|
| Regression Models | ||
| Полином | Да (до степени 9) | Да (до степени 5) |
| Экспоненциал | Да | |
| Фурье | Да | |
| Гауссов | Да | |
| Степень | Да | |
| Рациональный | Да | |
| Сумма синуса | Да | |
| Weibull | Да | |
| Interpolation | ||
| Interpolant | Да Методы: NearestNeighbor Линейный Кубический Сохранение формы (PCHIP) | Да Методы: NearestNeighbor Линейный Кубический Бигармонический Сплайн тонкой пластины |
| Smoothing | ||
| Сглаживание сплайна | Да | |
| Lowess | Да | |
| Custom | ||
| Пользовательское уравнение | Да | Да |
| Пользовательский линейный подбор кривой | Да | |
Для всех подходящих категорий посмотрите в панели Results, чтобы видеть термины модели, значения коэффициентов и статистику качества подгонки.
Совет
Если ваша подгонка имеет проблемы, сообщения в справке панели Results вы идентифицировать лучшие настройки.
Приложение Curve Fitting обеспечивает выбор подходящих типов и настройки, которые можно изменить к попытке улучшить подгонку. Попробуйте значения по умолчанию сначала, затем экспериментируйте с другими настройками.
Для обзора того, как использовать доступные подходящие опции, см. Опции Подгонки Определения и Оптимизированные Начальные точки.
Можно попробовать множество настроек в одной подходящей фигуре, и можно также создать несколько подгонок, чтобы выдержать сравнение. Когда вы создаете несколько подгонок, можно сравнить различные подходящие типы и настройки рядом друг с другом в приложении Curve Fitting. Смотрите Создают, Несколько Помещаются в Приложение Curve Fitting.
Можно задать имя модели библиотеки как вектор символов или строковый скаляр, когда вы вызываете fit функция. Например, чтобы задать квадратичный poly2:
f = fit( x, y, 'poly2' )
См. Список Моделей Библиотеки для Кривой и Поверхности, Соответствующей, чтобы просмотреть все доступные имена модели библиотеки.
Можно также использовать fittype функционируйте, чтобы создать fittype объект для модели библиотеки и использование fittype как вход к fit функция.
Используйте fitoptions функция, чтобы узнать, какие параметры можно установить, например:
fitoptions(poly2)
Для примеров смотрите разделы для каждого типа модели, перечисленного в таблице в Выборе Model Type Interactively. Для получения дополнительной информации на всех функциях для создания и анализа моделей, смотрите Кривую и Поверхностный Подбор кривой.
Большинство типов модели в приложении Curve Fitting совместно использует опцию Center and scale. Когда вы выбираете эту опцию, инструмент переоборудует данными, сосредоточенными и масштабированными путем применения Normalize установка на переменные. В командной строке можно использовать Normalize как входной параметр к fitoptions функция. Смотрите fitoptions страница с описанием.
Обычно это - хорошая идея нормировать входные параметры (также известный как данные о предикторе), который может облегчить числовые проблемы с переменными различных шкал. Например, предположите, что ваши поверхностные подходящие входные параметры являются скоростью вращения двигателя с областью значений 500-4500 об/мин и процентом загрузки механизма с областью значений 0–1. Затем Center and scale обычно улучшает подгонку из-за большой разницы по своим масштабам между двумя входными параметрами. Однако, если ваши входные параметры находятся в тех же модулях или подобной шкале (например, движения на восток и northings для географических данных), то Center and scale менее полезен. Когда вы нормируете входные параметры с этой опцией, значения подходящих коэффициентов изменяются когда по сравнению с исходными данными.
Если вы соответствуете кривой или поверхности, чтобы оценить коэффициенты, или коэффициенты имеют физическое значение, снимают флажок Center and scale. Графики приложения Curve Fitting используют исходную шкалу с или без опции Center and scale.
В командной строке, чтобы установить опцию сосредотачиваться и масштабировать данные перед подбором кривой, создают подходящую структуру опций по умолчанию, устанавливают Normalize к on, затем подгонка с опциями:
options = fitoptions;
options.Normal = 'on';
options
options =
Normalize: 'on'
Exclude: [1x0 double]
Weights: [1x0 double]
Method: 'None'
load census
f1 = fit(cdate,pop,'poly3',options)Интерактивные подходящие опции описаны в следующих разделах. Чтобы задать те же подходящие опции программно, см. Опции Подгонки Определения в Командной строке.
Чтобы задать подходящие опции в интерактивном режиме в приложении Curve Fitting, нажмите кнопку Fit Options, чтобы открыть Подходящее Окно параметров. Все подходящие категории кроме interpolants и сглаживающих сплайнов имеют конфигурируемые подходящие опции.
Доступные параметры зависят от того, соответствуете ли вы своим данным с помощью линейной модели, нелинейной модели или непараметрического подходящего типа:
Все опции описали, затем доступны для нелинейных моделей.
Более низкие и Верхние содействующие ограничения являются единственными подходящими опциями, доступными в диалоговом окне для полиномиальных линейных моделей. Для полиномов можно установить Robust в приложении Curve Fitting, не открывая Подходящее Окно параметров.
Непараметрические подходящие типы не имеют никакого дополнительного подходящего окна параметров (interpolant, сглаживая сплайн и lowess).
Подходящие варианты для одно термина экспоненциал показываются затем. Содействующие начальные значения и ограничения для данных о переписи.
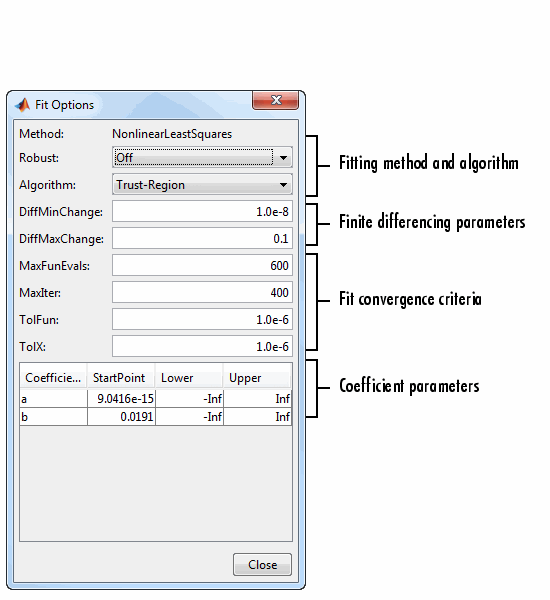
Method — Подходящий метод.
Метод автоматически выбран на основе библиотеки или пользовательской модели, которую вы используете. Для линейных моделей методом является LinearLeastSquares. Для нелинейных моделей методом является NonlinearLeastSquares.
Robust — Задайте, использовать ли устойчивые наименьшие квадраты подходящий метод.
Прочь — не используют устойчивый подходящий (значение по умолчанию).
На — Подгонка с устойчивым методом по умолчанию (bisquare веса).
LAR — Подгонка путем минимизации наименее абсолютных остаточных значений (LAR).
Bisquare — Подгонка путем минимизации суммированного квадрата остаточных значений, и уменьшает вес выбросов с помощью bisquare веса. В большинстве случаев это - лучший выбор для устойчивого подбора кривой.
Algorithm — Алгоритм использовал для подходящей процедуры:
Доверительная область — Это - алгоритм по умолчанию и должно использоваться, если вы задаете Более низкие или Верхние содействующие ограничения.
Levenberg-Marquardt — Если алгоритм доверительной области не производит разумную подгонку, и вы не имеете содействующих ограничений, пробуете алгоритм Levenberg-Marquardt.
DiffMinChange — Минимальное изменение в коэффициентах для Якобианов конечной разности. Значение по умолчанию равняется 10-8.
DiffMaxChange — Максимальное изменение в коэффициентах для Якобианов конечной разности. Значение по умолчанию 0.1.
Обратите внимание на то, что DiffMinChange и DiffMaxChange применяются:
Любое нелинейное пользовательское уравнение, то есть, нелинейное уравнение, которое вы пишете
Некоторым нелинейным уравнениям предоставляют программное обеспечение Curve Fitting Toolbox
Однако DiffMinChange и DiffMaxChange не применяются ни к каким линейным уравнениям.
MaxFunEvals — Максимальное количество функциональных оценок (модели) позволено. Значение по умолчанию 600.
MaxIter — Максимальное количество подходящих итераций позволено. Значение по умолчанию 400.
TolFun — Допуск завершения, используемый на останавливающихся условиях, включающих функциональное значение (модели). Значение по умолчанию равняется 10-6.
TolX — Допуск завершения, используемый на останавливающихся условиях, включающих коэффициенты. Значение по умолчанию равняется 10-6.
Coefficients — Символы для неизвестных коэффициентов, которые будут адаптированы.
StartPoint — Содействующие начальные значения. Значения по умолчанию зависят от модели. Для рационального, Weibull и пользовательских моделей, значения по умолчанию случайным образом выбраны в области значений [0,1]. Для всех других нелинейных моделей библиотеки начальные значения зависят от набора данных и вычисляются эвристическим образом. Смотрите оптимизированные начальные точки ниже.
Ниже Нижние границы на подходящих коэффициентах. Инструмент только использует границы с доверительным алгоритмом подбора области. Нижними границами по умолчанию для большинства моделей библиотеки является -Inf, который указывает, что коэффициенты неограничены. Однако несколько моделей имеют конечные нижние границы по умолчанию. Например, Gaussians ограничили параметр ширины так, чтобы он не мог быть меньше 0. Смотрите ограничения по умолчанию ниже.
Верхний Верхние границы на подходящих коэффициентах. Инструмент только использует границы с доверительным алгоритмом подбора области. Верхними границами по умолчанию для всех моделей библиотеки является Inf, который указывает, что коэффициенты неограничены.
Для получения дополнительной информации об этих подходящих опциях, смотрите lsqcurvefit функция в документации Optimization Toolbox™.
Содействующие начальные точки по умолчанию и ограничения для библиотеки и пользовательских моделей показывают в следующей таблице. Если начальные точки оптимизированы, то они вычисляются эвристическим образом на основе текущего набора данных. Случайные начальные точки заданы на интервале [0,1], и линейные модели не требуют начальных точек.
Если модель не имеет ограничений, коэффициенты не имеют ни нижней границы, ни верхней границы. Можно заменить начальные точки по умолчанию и ограничения путем введения собственных значений с помощью Подходящего Окна параметров.
Начальные точки по умолчанию и ограничения
Модель | Начальные точки | Ограничения |
|---|---|---|
Пользовательский линейный | N/A | 'none' |
Пользовательский нелинейный | Случайный | 'none' |
Экспоненциал | Оптимизированный | 'none' |
Фурье | Оптимизированный | 'none' |
Гауссов | Оптимизированный | c i> 0 |
Полином | N/A | 'none' |
Степень | Оптимизированный | 'none' |
Рациональный | Случайный | 'none' |
Сумма синуса | Оптимизированный | b i> 0 |
Weibull | Случайный | a, b> 0 |
Обратите внимание на то, что сумма синусов и серийных моделей Фурье особенно чувствительна к начальным точкам, и оптимизированные значения могут быть точными только для нескольких терминов в связанных уравнениях.
Создайте подходящую структуру опций по умолчанию и установите опцию сосредотачивать и масштабировать данные перед подбором кривой:
options = fitoptions;
options.Normal = 'on';
options
options =
Normalize: 'on'
Exclude: [1x0 double]
Weights: [1x0 double]
Method: 'None'Изменение подходящей структуры опций по умолчанию полезно, когда это необходимо, чтобы установить Normalize, Exclude, или Weights поля, и затем соответствуют вашим данным с помощью тех же опций с различными подходящими методами. Например:
load census f1 = fit(cdate,pop,'poly3',options); f2 = fit(cdate,pop,'exp1',options); f3 = fit(cdate,pop,'cubicsp',options);
Информационно-зависимые подходящие опции возвращены в третьем выходном аргументе fit функция. Например, параметр сглаживания для сглаживания сплайна информационно-зависим:
[f,gof,out] = fit(cdate,pop,'smooth');
smoothparam = out.p
smoothparam =
0.0089Используйте подходящие опции, чтобы изменить параметр сглаживания значения по умолчанию для новой подгонки:
options = fitoptions('Method','Smooth','SmoothingParam',0.0098);
[f,gof,out] = fit(cdate,pop,'smooth',options);Для получения дополнительной информации об использовании подходящих опций смотрите fitoptions страница с описанием.
