Оцените апостериорное распределение параметров байесовской линейной регрессионой модели
Чтобы выполнить выбор переменной предиктора для байесовской линейной регрессионой модели, см. estimate.
PosteriorMdl = estimate(PriorMdl,X,y)PosteriorMdl который характеризует апостериорные распределения коэффициентов в соединениях β и отклонение нарушения порядка σ2. PriorMdl задает предшествующее распределение параметров в соединениях и структуру линейной регрессионой модели. X - данные предиктора и y - данные отклика. PriorMdl и PosteriorMdl возможно, не совпадает с типом объекта.
Для создания PosteriorMdl, а estimate функция обновляет предшествующее распределение информацией о параметрах, которые она получает из данных.
NaNs в данных указывают отсутствующие значения, которые estimate удаляет при помощи спискового удаления.
PosteriorMdl = estimate(PriorMdl,X,y,Name,Value)
Если вы задаете Beta или Sigma2 аргумент пары "имя-значение", затем PosteriorMdl и PriorMdl равны.
[ использует любую из комбинаций входных аргументов в предыдущих синтаксисах, чтобы вернуть таблицу, содержащую следующее для каждого параметра: апостериорное среднее и стандартное отклонение, 95% доверительный интервал, апостериорную вероятность того, что параметр больше 0, и описание апостериорного распределения (если он существует). Кроме того, таблица содержит апостериорную ковариационную матрицу β и σ2. Если вы задаете PosteriorMdl,Summary]
= estimate(___)Beta или Sigma2 аргумент пары "имя-значение", затем estimate возвращает условные апостериорные оценки.
Рассмотрим модель, которая предсказывает расход топлива (в MPG) автомобиля с учетом объема и веса его двигателя.
Загрузите carsmall набор данных.
load carsmall
x = [Displacement Weight];
y = MPG;Регрессируйте экономию топлива на объем и вес двигателя, включая точку пересечения, для получения обычных оценок методом наименьших квадратов (OLS).
Mdl = fitlm(x,y)
Mdl =
Linear regression model:
y ~ 1 + x1 + x2
Estimated Coefficients:
Estimate SE tStat pValue
__________ _________ _______ __________
(Intercept) 46.925 2.0858 22.497 6.0509e-39
x1 -0.014593 0.0082695 -1.7647 0.080968
x2 -0.0068422 0.0011337 -6.0353 3.3838e-08
Number of observations: 94, Error degrees of freedom: 91
Root Mean Squared Error: 4.09
R-squared: 0.747, Adjusted R-Squared: 0.741
F-statistic vs. constant model: 134, p-value = 7.22e-28
Mdl.MSE
ans = 16.7100
Создайте диффузное предшествующее распределение по умолчанию для одного предиктора.
p = 2; PriorMdl = bayeslm(p);
PriorMdl является diffuseblm объект модели.
Используйте опции по умолчанию, чтобы оценить апостериорное распределение.
PosteriorMdl = estimate(PriorMdl,x,y);
Method: Analytic posterior distributions
Number of observations: 94
Number of predictors: 3
| Mean Std CI95 Positive Distribution
--------------------------------------------------------------------------------
Intercept | 46.9247 2.1091 [42.782, 51.068] 1.000 t (46.92, 2.09^2, 91)
Beta(1) | -0.0146 0.0084 [-0.031, 0.002] 0.040 t (-0.01, 0.01^2, 91)
Beta(2) | -0.0068 0.0011 [-0.009, -0.005] 0.000 t (-0.01, 0.00^2, 91)
Sigma2 | 17.0855 2.5905 [12.748, 22.866] 1.000 IG(45.50, 0.0013)
PosteriorMdl является conjugateblm объект модели.
Апостериорное средство и оценки коэффициентов OLS почти идентичны. Кроме того, апостериорные стандартные отклонения и стандартные ошибки OLS почти идентичны. Среднее апостериорное значение Sigma2 близок к средней квадратичной невязке OLS (MSE).
Рассмотрим множественную линейную регрессионую модель, которая предсказывает реальный валовой национальный продукт США (GNPR) с использованием линейной комбинации общей занятости (E) и реальная заработная плата (WR).

Для всех 
 является серией независимых Гауссовых нарушений порядка со средним значением 0 и отклонением.
является серией независимых Гауссовых нарушений порядка со средним значением 0 и отклонением.  Предположим, что эти предыдущие распределения:
Предположим, что эти предыдущие распределения:
 является 3-D t распределения с 10 степенями свободы для каждого компонента, корреляционная матрица
является 3-D t распределения с 10 степенями свободы для каждого компонента, корреляционная матрица C, местоположение ct, и масштабные st.
 , с формой
, с формой и шкалой.
и шкалой.
bayeslm рассматривает эти предположения и вероятность данных, как если бы соответствующий апостериор был аналитически неразрешим.
Объявите функцию MATLAB ®, которая:
Принимает значения и вместе в векторе-столбце и принимает значения гиперпараметров
и вместе в векторе-столбце и принимает значения гиперпараметров
Возвращает значение предыдущего распределения соединений,  учитывая значения и
учитывая значения и
function logPDF = priorMVTIG(params,ct,st,dof,C,a,b) %priorMVTIG Log density of multivariate t times inverse gamma % priorMVTIG passes params(1:end-1) to the multivariate t density % function with dof degrees of freedom for each component and positive % definite correlation matrix C. priorMVTIG returns the log of the product of % the two evaluated densities. % % params: Parameter values at which the densities are evaluated, an % m-by-1 numeric vector. % % ct: Multivariate t distribution component centers, an (m-1)-by-1 % numeric vector. Elements correspond to the first m-1 elements % of params. % % st: Multivariate t distribution component scales, an (m-1)-by-1 % numeric (m-1)-by-1 numeric vector. Elements correspond to the % first m-1 elements of params. % % dof: Degrees of freedom for the multivariate t distribution, a % numeric scalar or (m-1)-by-1 numeric vector. priorMVTIG expands % scalars such that dof = dof*ones(m-1,1). Elements of dof % correspond to the elements of params(1:end-1). % % C: Correlation matrix for the multivariate t distribution, an % (m-1)-by-(m-1) symmetric, positive definite matrix. Rows and % columns correspond to the elements of params(1:end-1). % % a: Inverse gamma shape parameter, a positive numeric scalar. % % b: Inverse gamma scale parameter, a positive scalar. % beta = params(1:(end-1)); sigma2 = params(end); tVal = (beta - ct)./st; mvtDensity = mvtpdf(tVal,C,dof); igDensity = sigma2^(-a-1)*exp(-1/(sigma2*b))/(gamma(a)*b^a); logPDF = log(mvtDensity*igDensity); end
Создайте анонимную функцию, которая работает как priorMVTIG, но принимает только значения параметров и содержит значения гиперзначений параметров, фиксированные при произвольно выбранных значениях.
prednames = ["E" "WR"]; p = numel(prednames); numcoeff = p + 1; rng(1); % For reproducibility dof = 10; V = rand(numcoeff); Sigma = 0.5*(V + V') + numcoeff*eye(numcoeff); st = sqrt(diag(Sigma)); C = diag(1./st)*Sigma*diag(1./st); ct = rand(numcoeff,1); a = 10*rand; b = 10*rand; logPDF = @(params)priorMVTIG(params,ct,st,dof,C,a,b);
Создайте пользовательскую модель предшествующего соединения для параметров линейной регрессии. Задайте количество предикторов p. Кроме того, задайте указатель на функцию для priorMVTIG и имена переменных.
PriorMdl = bayeslm(p,'ModelType','custom','LogPDF',logPDF,... 'VarNames',prednames);
PriorMdl является customblm Байесовский объект линейной регрессионной модели, представляющий предшествующее распределение коэффициентов регрессии и отклонение нарушения порядка.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда отклика и предиктора.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,"GNPR"};
Оцените маргинальные апостериорные распределения и использование гамильтонового анализатора Монте-Карло (HMC). Задайте рисунок 10000 выборок и период горения 1000 рисунков.
PosteriorMdl = estimate(PriorMdl,X,y,'Sampler','hmc','NumDraws',1e4,... 'Burnin',1e3);
Method: MCMC sampling with 10000 draws
Number of observations: 62
Number of predictors: 3
| Mean Std CI95 Positive Distribution
------------------------------------------------------------------------------
Intercept | -3.6486 5.6293 [-16.215, 6.143] 0.246 Empirical
E | -0.0056 0.0006 [-0.007, -0.004] 0.000 Empirical
WR | 15.2464 0.7727 [13.722, 16.749] 1.000 Empirical
Sigma2 | 1287.5830 243.1634 [894.978, 1849.210] 1.000 Empirical
PosteriorMdl является empiricalblm объект модели, сохраняющий рисунки из апостериорных распределений.
Просмотр графика трассировки и графика ACF рисунков из апостериорной части (для примера) и нарушение порядка отклонения. Не стройте график периода горения.
(для примера) и нарушение порядка отклонения. Не стройте график периода горения.
figure; subplot(2,1,1) plot(PosteriorMdl.BetaDraws(2,1001:end)); title(['Trace Plot ' char(8212) ' \beta_1']); xlabel('MCMC Draw') ylabel('Simulation Index') subplot(2,1,2) autocorr(PosteriorMdl.BetaDraws(2,1001:end)) figure; subplot(2,1,1) plot(PosteriorMdl.Sigma2Draws(1001:end)); title(['Trace Plot ' char(8212) ' Disturbance Variance']); xlabel('MCMC Draw') ylabel('Simulation Index') subplot(2,1,2) autocorr(PosteriorMdl.Sigma2Draws(1001:end))


По-видимому, выборка MCMC нарушения порядка отклонения хорошо перемешивается.
Рассмотрим регрессионую модель в оценке апостериорной функции с использованием гамильтонового сэмплера Монте-Карло. Этот пример использует те же данные и контекст, но вместо этого принимает диффузную предшествующую модель.
Создайте диффузную предшествующую модель для параметров линейной регрессии. Задайте количество предикторов p и имена коэффициентов регрессии.
p = 3; PriorMdl = bayeslm(p,'ModelType','diffuse','VarNames',["IPI" "E" "WR"])
PriorMdl =
diffuseblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4x1 cell}
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------
Intercept | 0 Inf [ NaN, NaN] 0.500 Proportional to one
IPI | 0 Inf [ NaN, NaN] 0.500 Proportional to one
E | 0 Inf [ NaN, NaN] 0.500 Proportional to one
WR | 0 Inf [ NaN, NaN] 0.500 Proportional to one
Sigma2 | Inf Inf [ NaN, NaN] 1.000 Proportional to 1/Sigma2
PriorMdl является diffuseblm объект модели.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда отклика и предиктора.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Оцените условное апостериорное распределение учитывая данные и что и возвращает сводную таблицу оценок для доступа к оценкам.
[Mdl,SummaryBeta] = estimate(PriorMdl,X,y,'Sigma2',2);Method: Analytic posterior distributions
Conditional variable: Sigma2 fixed at 2
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution
--------------------------------------------------------------------------------
Intercept | -24.2536 1.8696 [-27.918, -20.589] 0.000 N (-24.25, 1.87^2)
IPI | 4.3913 0.0301 [ 4.332, 4.450] 1.000 N (4.39, 0.03^2)
E | 0.0011 0.0001 [ 0.001, 0.001] 1.000 N (0.00, 0.00^2)
WR | 2.4682 0.0743 [ 2.323, 2.614] 1.000 N (2.47, 0.07^2)
Sigma2 | 2 0 [ 2.000, 2.000] 1.000 Fixed value
estimate отображает сводные данные условного апостериорного распределения . Поскольку фиксируется на уровне 2 во время оценки, выводы на ней тривиальны.
Извлеките вектор средних значений и ковариационную матрицу условного апостериора из сводной таблицы оценок.
condPostMeanBeta = SummaryBeta.Mean(1:(end - 1))
condPostMeanBeta = 4×1
-24.2536
4.3913
0.0011
2.4682
CondPostCovBeta = SummaryBeta.Covariances(1:(end - 1),1:(end - 1))
CondPostCovBeta = 4×4
3.4956 0.0350 -0.0001 0.0241
0.0350 0.0009 -0.0000 -0.0013
-0.0001 -0.0000 0.0000 -0.0000
0.0241 -0.0013 -0.0000 0.0055
Отобразите Mdl.
Mdl
Mdl =
diffuseblm with properties:
NumPredictors: 3
Intercept: 1
VarNames: {4x1 cell}
| Mean Std CI95 Positive Distribution
-----------------------------------------------------------------------------
Intercept | 0 Inf [ NaN, NaN] 0.500 Proportional to one
IPI | 0 Inf [ NaN, NaN] 0.500 Proportional to one
E | 0 Inf [ NaN, NaN] 0.500 Proportional to one
WR | 0 Inf [ NaN, NaN] 0.500 Proportional to one
Sigma2 | Inf Inf [ NaN, NaN] 1.000 Proportional to 1/Sigma2
Потому что estimate вычисляет условное апостериорное распределение, оно возвращает исходную предшествующую модель, а не апостериорную в первой позиции списка выходных аргументов.
Оцените условные апостериорные распределения учитывая, что является condPostMeanBeta.
[~,SummarySigma2] = estimate(PriorMdl,X,y,'Beta',condPostMeanBeta);Method: Analytic posterior distributions
Conditional variable: Beta fixed at -24.2536 4.3913 0.00112035 2.46823
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution
--------------------------------------------------------------------------------
Intercept | -24.2536 0 [-24.254, -24.254] 0.000 Fixed value
IPI | 4.3913 0 [ 4.391, 4.391] 1.000 Fixed value
E | 0.0011 0 [ 0.001, 0.001] 1.000 Fixed value
WR | 2.4682 0 [ 2.468, 2.468] 1.000 Fixed value
Sigma2 | 48.5138 9.0088 [33.984, 69.098] 1.000 IG(31.00, 0.00069)
estimate отображает сводные данные условного апостериорного распределения . Поскольку фиксировано на condPostMeanBeta во время оценки выводы на ней тривиальны.
Извлеките среднее значение и отклонение условного апостериора из сводной таблицы оценок.
condPostMeanSigma2 = SummarySigma2.Mean(end)
condPostMeanSigma2 = 48.5138
CondPostVarSigma2 = SummarySigma2.Covariances(end,end)
CondPostVarSigma2 = 81.1581
Рассмотрим регрессионую модель в оценке апостериорной функции с использованием гамильтонового сэмплера Монте-Карло. Этот пример использует те же данные и контекст, но вместо этого принимает полунъюгатную предшествующую модель.
Создайте полуконъюгатную предшествующую модель для параметров линейной регрессии. Задайте количество предикторов p и имена коэффициентов регрессии.
p = 3; PriorMdl = bayeslm(p,'ModelType','semiconjugate',... 'VarNames',["IPI" "E" "WR"]);
PriorMdl является semiconjugateblm объект модели.
Загрузите набор данных Нельсона-Плоссера. Создайте переменные для ряда отклика и предиктора.
load Data_NelsonPlosser X = DataTable{:,PriorMdl.VarNames(2:end)}; y = DataTable{:,'GNPR'};
Оцените маргинальные апостериорные распределения и .
rng(1); % For reproducibility
[PosteriorMdl,Summary] = estimate(PriorMdl,X,y);Method: Gibbs sampling with 10000 draws
Number of observations: 62
Number of predictors: 4
| Mean Std CI95 Positive Distribution
-------------------------------------------------------------------------
Intercept | -23.9922 9.0520 [-41.734, -6.198] 0.005 Empirical
IPI | 4.3929 0.1458 [ 4.101, 4.678] 1.000 Empirical
E | 0.0011 0.0003 [ 0.000, 0.002] 0.999 Empirical
WR | 2.4711 0.3576 [ 1.762, 3.178] 1.000 Empirical
Sigma2 | 46.7474 8.4550 [33.099, 66.126] 1.000 Empirical
PosteriorMdl является empiricalblm объект модели, потому что маргинальные апостериорные распределения семиконъюгатных моделей аналитически неразрешимы, так что estimate должен реализовать пробоотборник Гиббса. Summary - таблица, содержащая оценки и выводы, которые estimate отображается в командной строке.
Отображение сводной таблицы.
Summary
Summary=5×6 table
Mean Std CI95 Positive Distribution Covariances
_________ __________ ________________________ ________ _____________ ______________________________________________________________________
Intercept -23.992 9.052 -41.734 -6.1976 0.0053 {'Empirical'} 81.938 0.81622 -0.0025308 0.58928 0
IPI 4.3929 0.14578 4.1011 4.6782 1 {'Empirical'} 0.81622 0.021252 -7.1663e-06 -0.030939 0
E 0.0011124 0.00033976 0.00045128 0.0017883 0.9989 {'Empirical'} -0.0025308 -7.1663e-06 1.1544e-07 -8.4598e-05 0
WR 2.4711 0.3576 1.7622 3.1781 1 {'Empirical'} 0.58928 -0.030939 -8.4598e-05 0.12788 0
Sigma2 46.747 8.455 33.099 66.126 1 {'Empirical'} 0 0 0 0 71.487
Доступ к 95% справедливому достоверному интервалу коэффициента регрессии IPI.
Summary.CI95(2,:)
ans = 1×2
4.1011 4.6782
Если PriorMdl является empiricalblm объект модели. Вы не можете задать Beta или Sigma2. Вы не можете оценить условные апостериорные распределения с помощью эмпирического предшествующего распределения.
Симуляция Монте-Карло подвержена изменениям. Если estimate использует симуляцию Монте-Карло, тогда оценки и выводы могут варьироваться при вызове estimate несколько раз при, казалось бы, эквивалентных условиях. Чтобы воспроизвести результаты оценки, установите начальное число случайных чисел при помощи rng перед вызовом estimate.
Если estimate выдает ошибку при оценке апостериорного распределения с помощью пользовательской предыдущей модели, затем пытается настроить начальные значения параметров при помощи BetaStart или Sigma2Start, или попробуйте настроить объявленную функцию log previous, а затем восстановить модель. Ошибка может указать, что журнал предыдущего распределения –Inf при заданных начальных значениях.
Всякий раз, когда предшествующее распределение (PriorMdl) и вероятность данных дает аналитически отслеживаемое апостериорное распределение, estimate оценивает решения закрытой формы для оценок Байеса. В противном случае, estimate прибегает к симуляции Монте-Карло, чтобы оценить параметры и сделать выводы. Для получения дополнительной информации см. Апостериорная оценка и вывод.
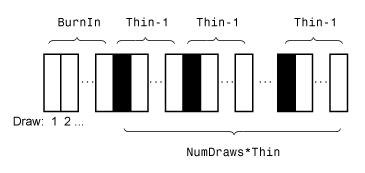
Этот рисунок иллюстрирует, как estimate уменьшает выборку Монте-Карло, используя значения NumDraws, Thin, и BurnIn. Прямоугольники представляют последовательные вытяжки из распределения. estimate удаляет белые прямоугольники из выборки Монте-Карло. Оставшиеся NumDraws чёрные прямоугольники составляют выборку Монте-Карло.