Симулируйте коэффициенты и инновации ковариационной матрицы модели Байесовской векторной авторегрессии (VAR)
[ возвращает случайный вектор коэффициентов Coeff,Sigma]
= simulate(PriorMdl)Coeff и случайные инновации ковариации матричных Sigma получен из предыдущей байесовской модели VAR (p)
PriorMdl.
[ задает опции, использующие один или несколько аргументы пары "имя-значение" в дополнение к любой комбинации входных аргументов в предыдущих синтаксисах. Для примера можно задать количество случайных рисований из распределения или указать данные отклика предварительного образца.Coeff,Sigma]
= simulate(___,Name,Value)
Рассмотрим 3-D модель VAR (4) для инфляции в США (INFL), безработица (UNRATE), и федеральные фонды (FEDFUNDS) ставки.
Для всех , - серия независимых 3-D нормальных инноваций со средним значением 0 и ковариацией . Предположим, что сопряженное предшествующее распределение управляет поведением параметров.
Создайте сопряженную предшествующую модель. Задайте имена рядов ответов. Получите сводные данные предыдущего распределения.
seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; numseries = numel(seriesnames); numlags = 4; PriorMdl = bayesvarm(numseries,numlags,'ModelType','conjugate',... 'SeriesNames',seriesnames); Summary = summarize(PriorMdl,'off');
Нарисуйте набор коэффициентов и ковариационную матрицу инноваций из предыдущего распределения.
rng(1) % For reproducibility
[Coeff,Sigma] = simulate(PriorMdl);Отобразите выбранные коэффициенты с соответствующими именами и ковариационной матрицей инноваций.
table(Coeff,'RowNames',Summary.CoeffMap)ans=39×1 table
Coeff
__________
AR{1}(1,1) 0.44999
AR{1}(1,2) 0.047463
AR{1}(1,3) -0.042106
AR{2}(1,1) -0.0086264
AR{2}(1,2) 0.034049
AR{2}(1,3) -0.058092
AR{3}(1,1) -0.015698
AR{3}(1,2) -0.053203
AR{3}(1,3) -0.031138
AR{4}(1,1) 0.036431
AR{4}(1,2) -0.058279
AR{4}(1,3) -0.02195
Constant(1) -1.001
AR{1}(2,1) -0.068182
AR{1}(2,2) 0.51029
AR{1}(2,3) -0.094367
⋮
AR {r} (j, k) является коэффициентом AR переменной отклика k (отстающие r модулей) в ответном уравнении j.
Sigma
Sigma = 3×3
0.1238 -0.0053 -0.0369
-0.0053 0.0456 0.0160
-0.0369 0.0160 0.1039
Строки и столбцы Sigma соответствуют нововведениям в уравнениях отклика, упорядоченных PriorMdl.SeriesNames.
Рассмотрим 3-D модель VAR (4) коэффициентов рисования и инноваций Ковариации матрицы из предыдущего распределения. В этом случае примите, что предшествующее распределение является диффузным.
Загрузка и предварительная обработка данных
Загрузите набор макроэкономических данных США. Рассчитать уровень инфляции, стабилизировать ставки по безработице и федеральным фондам и удалить отсутствующие значения.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте предыдущую модель
Создайте диффузную модель Bayesian VAR (4) для трех рядов откликов. Задайте имена рядов ответов.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = bayesvarm(numseries,numlags,'SeriesNames',seriesnames);Оценка апостериорного распределения
Оцените апостериорное распределение. Верните сводные данные оценок.
[PosteriorMdl,Summary] = estimate(PriorMdl,rmDataTable{:,seriesnames});Bayesian VAR under diffuse priors
Effective Sample Size: 197
Number of equations: 3
Number of estimated Parameters: 39
| Mean Std
-------------------------------
Constant(1) | 0.1007 0.0832
Constant(2) | -0.0499 0.0450
Constant(3) | -0.4221 0.1781
AR{1}(1,1) | 0.1241 0.0762
AR{1}(2,1) | -0.0219 0.0413
AR{1}(3,1) | -0.1586 0.1632
AR{1}(1,2) | -0.4809 0.1536
AR{1}(2,2) | 0.4716 0.0831
AR{1}(3,2) | -1.4368 0.3287
AR{1}(1,3) | 0.1005 0.0390
AR{1}(2,3) | 0.0391 0.0211
AR{1}(3,3) | -0.2905 0.0835
AR{2}(1,1) | 0.3236 0.0868
AR{2}(2,1) | 0.0913 0.0469
AR{2}(3,1) | 0.3403 0.1857
AR{2}(1,2) | -0.0503 0.1647
AR{2}(2,2) | 0.2414 0.0891
AR{2}(3,2) | -0.2968 0.3526
AR{2}(1,3) | 0.0450 0.0413
AR{2}(2,3) | 0.0536 0.0223
AR{2}(3,3) | -0.3117 0.0883
AR{3}(1,1) | 0.4272 0.0860
AR{3}(2,1) | -0.0389 0.0465
AR{3}(3,1) | 0.2848 0.1841
AR{3}(1,2) | 0.2738 0.1620
AR{3}(2,2) | 0.0552 0.0876
AR{3}(3,2) | -0.7401 0.3466
AR{3}(1,3) | 0.0523 0.0428
AR{3}(2,3) | 0.0008 0.0232
AR{3}(3,3) | 0.0028 0.0917
AR{4}(1,1) | 0.0167 0.0901
AR{4}(2,1) | 0.0285 0.0488
AR{4}(3,1) | -0.0690 0.1928
AR{4}(1,2) | -0.1830 0.1520
AR{4}(2,2) | -0.1795 0.0822
AR{4}(3,2) | 0.1494 0.3253
AR{4}(1,3) | 0.0067 0.0395
AR{4}(2,3) | 0.0088 0.0214
AR{4}(3,3) | -0.1372 0.0845
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.3028 -0.0217 0.1579
| (0.0321) (0.0124) (0.0499)
DUNRATE | -0.0217 0.0887 -0.1435
| (0.0124) (0.0094) (0.0283)
DFEDFUNDS | 0.1579 -0.1435 1.3872
| (0.0499) (0.0283) (0.1470)
PosteriorMdl является conjugatebvarm модель, которая аналитически отслеживается.
Симулируйте параметры из апостериорной функции
Нарисуйте 1000 выборки из апостериорного распределения.
rng(1)
[Coeff,Sigma] = simulate(PosteriorMdl,'NumDraws',1000);Coeff - матрица 39 на 1000 случайным образом нарисованных коэффициентов. Каждый столбец является индивидуальным рисунком, и каждая строка является индивидуальным коэффициентом. Sigma является массивом 3х3-х1000 случайным образом нарисованных инноваций ковариации матрицах. Каждая страница является индивидуальным розыгрышем.
Отобразите первый коэффициент, полученный из распределения с соответствующими именами параметров, и отобразите первую нарисованную ковариационную матрицу инноваций.
Coeffs = table(Coeff(:,1),'RowNames',Summary.CoeffMap)Coeffs=39×1 table
Var1
_________
AR{1}(1,1) 0.14994
AR{1}(1,2) -0.46927
AR{1}(1,3) 0.088388
AR{2}(1,1) 0.28139
AR{2}(1,2) -0.19597
AR{2}(1,3) 0.049222
AR{3}(1,1) 0.3946
AR{3}(1,2) 0.081871
AR{3}(1,3) 0.002117
AR{4}(1,1) 0.13514
AR{4}(1,2) -0.23661
AR{4}(1,3) -0.01869
Constant(1) 0.035787
AR{1}(2,1) 0.0027895
AR{1}(2,2) 0.62382
AR{1}(2,3) 0.053232
⋮
Sigma(:,:,1)
ans = 3×3
0.2653 -0.0075 0.1483
-0.0075 0.1015 -0.1435
0.1483 -0.1435 1.5042
Рассмотрим 3-D модель VAR (4) коэффициентов рисования и инноваций Ковариации матрицы из предыдущего распределения. В этом случае примите, что предшествующее распределение является полунъюгатным.
Загрузка и предварительная обработка данных
Загрузите набор макроэкономических данных США. Рассчитать уровень инфляции, стабилизировать ставки по безработице и федеральным фондам и удалить отсутствующие значения.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте предыдущую модель
Создайте полуконъюгатную предшествующую модель Bayesian VAR (4) для трех рядов откликов. Задайте имена переменных отклика.
numseries = numel(seriesnames); numlags = 4; PriorMdl = bayesvarm(numseries,numlags,'Model','semiconjugate',... 'SeriesNames',seriesnames);
Симулируйте параметры из апостериорной функции
Поскольку апостериорное распределение соединений полуконъюгатной предшествующей модели аналитически неразрешимо, simulate последовательно черпает из полных условных распределений.
Нарисуйте 1000 выборки из апостериорного распределения. Задайте период горения 10 000 и коэффициент утончения 5. Запустите семплер Гиббса, приняв апостериорное среднее - матрица 3-D тождеств.
rng(1)
[Coeff,Sigma] = simulate(PriorMdl,rmDataTable{:,seriesnames},...
'NumDraws',1000,'BurnIn',1e4,'Thin',5,'Sigma0',eye(3));Coeff - матрица 39 на 1000 случайным образом нарисованных коэффициентов. Каждый столбец является индивидуальным рисунком, и каждая строка является индивидуальным коэффициентом. Sigma является массивом 3х3-х1000 случайным образом нарисованных инноваций ковариации матрицах. Каждая страница является индивидуальным розыгрышем.
Рассмотрим 2-D модель VARX (1) для реального ВВП США (RGDP) и инвестиции (GCE) тарифы, которые лечат личное потребление (PCEC) скорость как экзогенная:
Для всех , - серия независимых 2-D нормальных инноваций со средним значением 0 и ковариацией . Примите следующие предыдущие распределения:
, где M является матрицей средств 4 на 2 и - матрица шкалы между коэффициентами 4 на 4. Эквивалентно, .
где И - матрица шкалы 2 на 2, - степени свободы.
Загрузите набор макроэкономических данных США. Вычислите реальный показатель ВВП, инвестиций и личного потребления. Удалите все отсутствующие значения из получившейся серии.
load Data_USEconModel DataTable.RGDP = DataTable.GDP./DataTable.GDPDEF; seriesnames = ["PCEC"; "RGDP"; "GCE"]; rates = varfun(@price2ret,DataTable,'InputVariables',seriesnames); rates = rmmissing(rates); rates.Properties.VariableNames = seriesnames;
Создайте сопряженную предшествующую модель для параметров модели 2-D VARX (1).
numseries = 2; numlags = 1; numpredictors = 1; PriorMdl = conjugatebvarm(numseries,numlags,'NumPredictors',numpredictors,... 'SeriesNames',seriesnames(2:end));
Симулируйте непосредственно из апостериорного распределения. Задайте экзогенные данные предиктора.
[Coeff,Sigma] = simulate(PriorMdl,rates{:,PriorMdl.SeriesNames},...
'X',rates{:,seriesnames(1)});По умолчанию simulate использует первые наблюдения p = 1 данных отклика, чтобы инициализировать динамический компонент модели, и удаляет соответствующие наблюдения из данных предиктора.
PriorMdl - Предыдущая байесовская модель VARconjugatebvarm объект модели | semiconjugatebvarm объект модели | diffusebvarm объект модели | normalbvarm объект моделиПредыдущая модель Bayesian VAR, заданная как объект модели в этой таблице.
| Объект модели | Описание |
|---|---|
conjugatebvarm | Зависимая, матричная-нормальная-обратная-Wishart сопряженная модель, возвращенная bayesvarm или conjugatebvarm |
semiconjugatebvarm | Независимая, нормальная-обратная-Wishart полусредняя предыдущая модель, возвращенная bayesvarm или semiconjugatebvarm |
diffusebvarm | Диффузная предыдущая модель, возвращенная bayesvarm или diffusebvarm |
normalbvarm | Нормальная сопряженная модель с фиксированной инновационной ковариационной матрицей, возвращенной bayesvarm или normalbvarm |
Y - Наблюдаемый многомерный ряд откликаНаблюдался многомерный ряд отклика, на который simulate подходит для модели, заданной как numobs-by- numseries числовая матрица.
numobs - размер выборки. numseries - количество переменных отклика (PriorMdl.NumSeries).
Строки соответствуют наблюдениям, а последняя строка содержит последнее наблюдение. Столбцы соответствуют отдельным переменным отклика.
Y представляет продолжение предварительной серии откликов в Y0.
Типы данных: double
Задайте необязательные разделенные разделенными запятой парами Name,Value аргументы. Name - имя аргумента и Value - соответствующее значение. Name должны находиться внутри кавычек. Можно задать несколько аргументов в виде пар имен и значений в любом порядке Name1,Value1,...,NameN,ValueN.
'Y0',Y0,'X',X задает предварительные данные отклика Y0 для инициализации модели VAR для апостериорной оценки и данных предиктора X для компонента экзогенной регрессии.'NumDraws' - Количество случайных рисок1 (по умолчанию) | положительное целое числоКоличество случайных рисований из распределений, заданное как разделенная разделенными запятой парами, состоящая из 'NumDraws' и положительное целое число.
Пример: 'NumDraws',1e7
Типы данных: double
'Y0' - Предварительный образец данных откликаПредварительный образец данных отклика для инициализации модели VAR для оценки, заданный как разделенная разделенными запятой парами, состоящая из 'Y0' и a numpreobs-by- numseries числовая матрица. numpreobs - количество предварительных наблюдений.
Строки соответствуют предварительным образцам наблюдений, а последняя строка содержит последнее наблюдение. Y0 должно иметь по крайней мере PriorMdl.P строки. Если вы поставляете больше строк, чем нужно, simulate использует последние PriorMdl.P только наблюдения.
Столбцы должны соответствовать ряду ответов в Y.
По умолчанию, simulate использует Y(1:PriorMdl.P,:) в качестве предварительного примера наблюдений, а затем оценивает апостериорное использование Y((PriorMdl.P + 1):end,:). Это действие уменьшает эффективный размер выборки.
Типы данных: double
'X' - Данные предиктораДанные предиктора для компонента экзогенной регрессии в модели, заданные как разделенная разделенными запятой парами, состоящая из 'X' и a numobs-by- PriorMdl.NumPredictors числовая матрица.
Строки соответствуют наблюдениям, а последняя строка содержит последнее наблюдение. simulate не использует регрессионный компонент в предварительном образце периода. X должно иметь, по крайней мере, столько наблюдений, сколько наблюдений, используемых после периода предварительного образца.
В любом случае, если вы поставляете больше строк, чем необходимо, simulate использует только последние наблюдения.
Столбцы соответствуют отдельным переменным предиктора. Все переменные предиктора присутствуют в регрессионном компоненте каждого уравнения отклика.
Типы данных: double
'BurnIn' - Количество розыгрышей для удаления из начала выборки0 (по умолчанию) | неотрицательной скаляромКоличество розыгрышей для удаления из начала выборки для уменьшения переходных эффектов, заданное как разделенная разделенными запятой парами, состоящая из 'BurnIn' и неотрицательный скаляр. Для получения дополнительной информации о том, как simulate уменьшает полную выборку, см. Алгоритмы.
Совет
Чтобы помочь вам указать соответствующий размер периода горения:
Определите степень переходного поведения в выборке путем определения 'BurnIn',0.
Симулируйте несколько тысяч наблюдений при помощи simulate.
Нарисуйте графики трассировки.
Пример: 'BurnIn',0
Типы данных: double
'Thin' - Скорректированный множитель размера выборки1 (по умолчанию) | положительное целое числоСкорректированный множитель размера выборки, заданный как разделенная разделенными запятой парами, состоящая из 'Thin' и положительное целое число.
Фактический размер выборки BurnIn + NumDraws*Thin. После отбрасывания горения, simulate отбрасывает каждый Thin – 1 рисует, а затем сохраняет следующий розыгрыш. Для получения дополнительной информации о том, как simulate уменьшает полную выборку, см. Алгоритмы.
Совет
Чтобы уменьшить потенциальную большую последовательную корреляцию в выборке или уменьшить потребление памяти рисунков, сохраненных в Coeff и Sigma, задайте большое значение для Thin.
Пример: 'Thin',5
Типы данных: double
'Coeff0' - Начальное значение коэффициентов модели VAR для дискретизатора ГиббсаНачальное значение коэффициентов модели VAR для семплера Гиббса, заданное как разделенная разделенными запятой парами, состоящая из 'Coeff0' и числовой вектор-столбец с (PrivateMdl.NumSeries ) -by* k- NumDraws элементы, где k = PriorMdl. NumSeries*PriorMdl. P + PriorMdl. IncludeIntercept + PriorMdl. IncludeTrend + PriorMdl. NumPredictorsCoeff0, см. выход Coeff.
По умолчанию Coeff0 - многомерная оценка методом наименьших квадратов.
Совет
Чтобы задать Coeff0:
Установите отдельные переменные для начальных значений каждой матрицы коэффициентов и вектора.
Горизонтально конкатенируйте все средства коэффициентов в этом порядке:
Векторизация транспонирования средней матрицы коэффициентов.
Coeff0 = Coeff.'; Coeff0 = Coeff0(:);
Хорошей практикой является запуск simulate несколько раз с различными начальными значениями параметра. Проверьте, что оценки из каждого запуска сходятся к аналогичным значениям.
Типы данных: double
'Sigma0' - Начальное значение ковариационной матрицы инноваций для семплера ГиббсаНачальное значение ковариационной матрицы инноваций для семплера Гиббса, заданное как разделенная разделенными запятой парами, состоящая из 'Sigma0' и a PriorMdl.NumSeries-by- PriorMdl.NumSeries положительная определенная числовая матрица. По умолчанию Sigma0 - невязка средняя квадратичная невязка из многомерных наименьших квадратов. Строки и столбцы соответствуют инновациям в уравнениях переменных отклика, упорядоченных по PriorMdl.SeriesNames.
Совет
Хорошей практикой является запуск simulate несколько раз с различными начальными значениями параметра. Проверьте, что оценки из каждого запуска сходятся к аналогичным значениям.
Типы данных: double
Coeff - Моделируемые коэффициенты модели VARМоделируемые коэффициенты модели VAR, возвращенные как (PriorMdl.NumSeries ) -by* k- NumDraws числовая матрица, где k = PriorMdl. NumSeries*PriorMdl. P + PriorMdl. IncludeIntercept + PriorMdl. IncludeTrend + PriorMdl. NumPredictors
Для рисования jКоефф (1 соответствует всем коэффициентам в уравнении переменной отклика : k, j)PriorMdl.SeriesNames(1), Коефф ( соответствует всем коэффициентам в уравнении переменной отклика (k + 1): (2* k), j)PriorMdl.SeriesNames(2)и так далее. Для набора индексов, соответствующих уравнению:
Элементы 1 через PriorMdl.NumSeries соответствуют задержке 1 AR коэффициентов переменных отклика, упорядоченных по PriorMdl.SeriesNames.
Элементы PriorMdl.NumSeries + 1 через 2*PriorMdl.NumSeries соответствуют задержке 2 коэффициентов AR переменных отклика, упорядоченных по PriorMdl.SeriesNames.
В целом элементы ( через q – 1) *PriorMdl. NumSeries + 1q*PriorMdl. NumSeriesqPriorMdl.SeriesNames.
Если PriorMdl.IncludeConstant является true, элемент PriorMdl.NumSeries*PriorMdl.P + 1 является моделью постоянной.
Если PriorMdl.IncludeTrend является true, элемент PriorMdl.NumSeries*PriorMdl.P + 2 - линейный коэффициент тренда времени.
Если PriorMdl.NumPredictors > 0, элементы PriorMdl.NumSeries*PriorMdl.P + 3 через k
Этот рисунок показывает структуру Coeff (L для 2-D модели VAR (3), которая содержит постоянный вектор и четыре экзогенных предиктора., j)
где
ϕ q jk является элементом (j, k) матрицы коэффициентов AR q задержки.
c j является моделью, константой в уравнении переменной j отклика.
<reservedrangesplaceholder4> <reservedrangesplaceholder3> <reservedrangesplaceholder2> - коэффициент регрессии внешней переменной u в уравнении переменной ответа j.
Sigma - Моделируемые ковариационные матрицы инновацийМоделируемые инновации ковариационные матрицы, возвращенные как PriorMdl.NumSeries-by- PriorMdl.NumSeries-by- NumDraws массив положительно определенных числовых матриц.
Каждая страница является отдельной ничьей (ковариацией) от распределения. Строки и столбцы соответствуют инновациям в уравнениях переменных отклика, упорядоченных по PriorMdl.SeriesNames.
Если PriorMdl является normalbvarm объект, все ковариации в Sigma равны PriorMdl.Covariance.
simulate невозможно получить значения из improper distribution, которая является распределением, плотность которого не интегрируется с 1.
A Bayesian VAR model обрабатывает все коэффициенты и ковариационную матрицу инноваций как случайные переменные в m -мерной, стационарной модели VARX (p). Модель имеет одну из трех форм, описанных в этой таблице.
| Модель | Уравнение |
|---|---|
| VAR (p) редуцированной формы в обозначении разностного уравнения |
|
| Многомерная регрессия |
|
| Матричная регрессия |
|
Для каждого временного t = 1,..., T:
yt - m -мерный вектор наблюдаемой отклика, где m = numseries.
Φ1,..., - p являются m -by m матрицами коэффициентов AR лагов с 1 по p, где p = numlags.
c - вектор m -by-1 констант модели, если IncludeConstant является true.
δ - вектор m -by-1 коэффициентов линейного временного тренда, если IncludeTrend является true.
Β - m -by - r матрица коэффициентов регрессии вектора r -by - 1 наблюдаемых экзогенных предикторов x t, где r = NumPredictors. Все переменные предиктора появляются в каждом уравнении.
который является вектором 1-by- (mp + r + 2), и Z t является m -by- m (mp + r + 2) блочной диагональной матрицей
где 0 z является 1-бай- (mp + r + 2) вектором нулей.
, которая является (mp + r + 2) -by m случайной матрицей коэффициентов, и m (mp + r + 2) -by-1 вектор λ = vec (
εt является m-на-1 вектором случайных, последовательно некоррелированных, многомерных нормальных инноваций с нулевым вектором для среднего и m -by- m матрицы Это предположение подразумевает, что вероятность данных является
где f m - размерная многомерная нормальная плотность со средним <reservedrangesplaceholder3> <reservedrangesplaceholder2> Λ и ковариацией Σ, оценен в <reservedrangesplaceholder1> <reservedrangesplaceholder0>.
Прежде, чем рассмотреть данные, Вы налагаете joint prior distribution предположение на (Λ,Σ), которым управляет распределение π (Λ,Σ). В байесовском анализе распределение параметров обновляется информацией о параметрах, полученных из вероятности данных. Результатом является joint posterior distribution π (Λ,Σ|<reservedrangesplaceholder2>,<reservedrangesplaceholder1>,<reservedrangesplaceholder0>0), где:
Y - T матрица m, содержащая весь ряд ответов {y t}, t = 1,..., T.
X - T матрица m, содержащая весь экзогенный ряд {x t}, t = 1,..., T.
Y 0 является p -by - m матрицей предварительных образцов данных, используемых для инициализации модели VAR для оценки.
Симуляция Монте-Карло подвержена изменениям. Если simulate использует симуляцию Монте-Карло, тогда оценки и выводы могут варьироваться при вызове simulate несколько раз при, казалось бы, эквивалентных условиях. Чтобы воспроизвести результаты оценки, установите начальное число случайных чисел при помощи rng перед вызовом simulate.
Если simulate оценивает апостериорное распределение (когда вы поставляете Y) и апостериор аналитически прослеживается, simulate симулирует непосредственно из апостериорной. В противном случае, simulate использует семплер Гиббса, чтобы оценить апостериор.
Этот рисунок показывает, как simulate уменьшает выборку при помощи значений NumDraws, Thin, и BurnIn. Прямоугольники представляют последовательные вытяжки из распределения. simulate удаляет белые прямоугольники из выборки. Оставшиеся NumDraws чёрные прямоугольники составляют выборку.
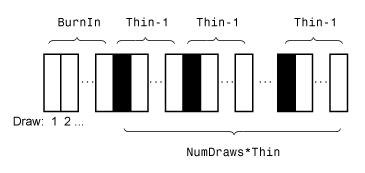
Если PriorMdl является semiconjugatebvarm объект и вы не задаете начальные значения (Coeff0 и Sigma0), simulate выборки из апостериорного распределения путем применения пробоотборника Гиббса.
simulate использует значение по умолчанию Sigma0 для, и черпает значение И, из π (и Y, X), полное условное распределение коэффициентов модели VAR.
simulate рисует значение И из π (и Y, X), полного условного распределения нововведений ковариации матрицы, при помощи ранее сгенерированного значения И.
Функция повторяет шаги 1 и 2 до сходимости. Чтобы оценить сходимость, нарисуйте график трассировки выборки.
Если вы задаете Coeff0, simulate рисует значение И из π (и Y, X), чтобы запустить семплер Гиббса.
simulate не возвращает начальные значения по умолчанию, которые она генерирует.
У вас есть измененная версия этого примера. Вы хотите открыть этот пример с вашими правками?
1. Если смысл перевода понятен, то лучше оставьте как есть и не придирайтесь к словам, синонимам и тому подобному. О вкусах не спорим.
2. Не дополняйте перевод комментариями “от себя”. В исправлении не должно появляться дополнительных смыслов и комментариев, отсутствующих в оригинале. Такие правки не получится интегрировать в алгоритме автоматического перевода.
3. Сохраняйте структуру оригинального текста - например, не разбивайте одно предложение на два.
4. Не имеет смысла однотипное исправление перевода какого-то термина во всех предложениях. Исправляйте только в одном месте. Когда Вашу правку одобрят, это исправление будет алгоритмически распространено и на другие части документации.
5. По иным вопросам, например если надо исправить заблокированное для перевода слово, обратитесь к редакторам через форму технической поддержки.
