Сглаживание симуляции модели байесовской векторной авторегрессии (VAR)
simsmooth хорошо подходит для продвинутых приложений, таких как выборочное условное прогнозирование из апостериорного прогнозирующего распределения байесовской модели VAR (p), прогнозирование модели VARX (p), вменение отсутствующего значения и оценка параметра в присутствии отсутствующих значений. Также,simsmooth позволяет вам настроить дискретизатор Гиббса для прогнозирования вне выборки. Для оценки выборочных прогнозов из байесовской модели VAR (p) см. forecast.
[ возвращает 1000 случайных рисунок векторов коэффициентов λ
CoeffCoeffDraws,SigmaDraws] = simsmooth(PriorMdl,Y) и инновации ковариации матрицах, Sigma, полученный из апостериорного распределения, образованного объединением предыдущей байесовской модели VAR (p)
PriorMdl и данные отклика Y.
Процедура дискретизации включает шаг увеличения Байесовских данных, который использует фильтр Калмана (см. Алгоритмы). Во время отбора проб, simsmooth заменяет отсутствующие значения без предварительного опредления в Y, обозначенный NaN значений с вмененными значениями.
[ использует дополнительные опции, заданные одним или несколькими аргументами пары "имя-значение". Для примера можно задать количество случайных рисований из распределения или указать данные отклика предварительного образца.CoeffDraws,SigmaDraws] = simsmooth(PriorMdl,Y,Name,Value)
[ также возвращает вмененные значения отклика каждого розыгрыша CoeffDraws,SigmaDraws,NaNDraws]
= simsmooth(___)NaNDraws использование любой комбинации входных аргументов в предыдущих синтаксисах.
[ также возвращает среднее CoeffDraws,SigmaDraws,NaNDraws,YMean,YStd]
= simsmooth(___)YMean и стандартное отклонение YStd апостериорного прогнозирующего распределения дополненных данных.
Когда simulate оценивает апостериорное распределение, из которого можно нарисовать параметры, удаляет все строки в данных, которые содержат по крайней мере одно отсутствующее значение (NaN). Однако simsmooth использует увеличение байесовских данных, чтобы вписать отсутствующие значения, не являющиеся предварительными, во время апостериорной оценки.
Рассмотрим 3-D модель VAR (4) для инфляции в США (INFL), безработица (UNRATE), и федеральные фонды (FEDFUNDS) ставки.
Для всех , - серия независимых 3-D нормальных инноваций со средним значением 0 и ковариацией . Предположим, что слабое сопряженное предшествующее распределение для параметров .
Загрузка и предварительная обработка данных
Загрузите набор макроэкономических данных США. Рассчитать уровень инфляции и стабилизировать показатели безработицы и федеральных фондов.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3);
Несколько серий имеют ведущие NaN значения, потому что их измерения были недоступны одновременно с другими измерениями. Потому что ведущие NaN значения могут влиять на предварительный образец спецификации, удалять все строки, содержащие по крайней мере одно начальное отсутствующее значение.
rmldDataTable = rmmissing(DataTable(:,seriesnames));
Создайте предыдущую модель
Создайте слабую сопряженную предшествующую модель путем определения больших предшествующих отклонений коэффициента. Задайте имена рядов ответов.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Случайное размещение отсутствующих значений в данных
Чтобы проиллюстрировать симуляцию при наличии отсутствующих значений, случайным образом поместите отсутствующие значения в данные после периода предварительного образца.
rng(1) % For reproducibility T = size(rmldDataTable,1); idxpre = 1:PriorMdl.P; % Presample period idxest = (PriorMdl.P + 1):T; % Estimation period nmissing = 20; % Simulate at most nmissing missing values sidx = [randsample(idxest,nmissing,true); randsample(1:numseries,nmissing,true)]; lsidx = sub2ind([T,numseries],sidx(1,:),sidx(2,:)); MissData = table2array(rmldDataTable); MissData(lsidx) = NaN; MissDataTable = rmldDataTable; MissDataTable{:,:} = MissData;
Симулируйте параметры из апостериорной функции
Нарисуйте 1000 наборов параметров из апостериорного распределения путем вызова simsmooth, который оценивает апостериорное распределение параметров, а затем формирует апостериорное прогнозирующее распределение.
[Coeff,Sigma] = simsmooth(PriorMdl,MissDataTable);
Coeff - матрица 39 на 1000 векторов случайным образом нарисованных коэффициентов из апостериорной матрицы. Sigma является массивом 3х3-х1000 случайным образом нарисованных инноваций ковариации матрицах.
По умолчанию simsmooth инициализирует модель VAR при помощи первых четырех наблюдений в данных.
Чтобы связать строки Coeff для коэффициентов получаем сводные данные предыдущего распределения при помощи summarize. В таблице отобразите первый набор случайным образом нарисованных коэффициентов с соответствующими именами.
Summary = summarize(PriorMdl,'off'); table(Coeff(:,1),'RowNames',Summary.CoeffMap)
ans=39×1 table
Var1
__________
AR{1}(1,1) 0.22109
AR{1}(1,2) -0.24034
AR{1}(1,3) 0.093315
AR{2}(1,1) 0.18329
AR{2}(1,2) -0.23178
AR{2}(1,3) -0.026301
AR{3}(1,1) 0.39991
AR{3}(1,2) 0.41141
AR{3}(1,3) 0.054702
AR{4}(1,1) 0.024944
AR{4}(1,2) -0.37372
AR{4}(1,3) -0.0095642
Constant(1) 0.21499
AR{1}(2,1) -0.073776
AR{1}(2,2) 0.36086
AR{1}(2,3) 0.071088
⋮
Кроме того, можно создать эмпирическую модель из рисунков и использовать summarize отображение модели путем задания любого параметра отображения.
Отобразите сводные данные апостериорных рисунков как уравнение.
EmpMdl = empiricalbvarm(numseries,numlags,'SeriesNames',seriesnames,... 'CoeffDraws',Coeff,'SigmaDraws',Sigma); summarize(EmpMdl,'equation')
VAR Equations
| INFL(-1) DUNRATE(-1) DFEDFUNDS(-1) INFL(-2) DUNRATE(-2) DFEDFUNDS(-2) INFL(-3) DUNRATE(-3) DFEDFUNDS(-3) INFL(-4) DUNRATE(-4) DFEDFUNDS(-4) Constant
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
INFL | 0.1447 -0.3685 0.1013 0.2974 -0.0959 0.0360 0.4115 0.2244 0.0474 0.0265 -0.2321 0.0030 0.1095
| (0.0744) (0.1314) (0.0370) (0.0833) (0.1509) (0.0398) (0.0833) (0.1440) (0.0403) (0.0879) (0.1301) (0.0370) (0.0744)
DUNRATE | -0.0187 0.4445 0.0314 0.0836 0.2372 0.0489 -0.0407 -0.0548 -0.0064 0.0483 -0.1753 0.0027 -0.0597
| (0.0447) (0.0808) (0.0234) (0.0514) (0.0863) (0.0230) (0.0507) (0.0906) (0.0243) (0.0514) (0.0779) (0.0225) (0.0466)
DFEDFUNDS | -0.2046 -1.1927 -0.2524 0.2864 -0.2282 -0.2657 0.2709 -0.6231 0.0289 -0.0404 0.1043 -0.1236 -0.2952
| (0.1530) (0.2931) (0.0816) (0.1832) (0.3123) (0.0857) (0.1736) (0.3105) (0.0900) (0.1866) (0.2880) (0.0758) (0.1684)
Innovations Covariance Matrix
| INFL DUNRATE DFEDFUNDS
-------------------------------------------
INFL | 0.2842 -0.0098 0.1346
| (0.0286) (0.0122) (0.0464)
DUNRATE | -0.0098 0.1062 -0.1496
| (0.0122) (0.0106) (0.0296)
DFEDFUNDS | 0.1346 -0.1496 1.3187
| (0.0464) (0.0296) (0.1422)
Рассмотрим 3-D модель VAR (4) моделирования параметров из апостериорного распределения при наличии отсутствующих значений .
Загрузите набор макроэкономических данных США. Рассчитать уровень инфляции и стабилизировать показатели безработицы и федеральных фондов.
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3);
Удалите все строки, содержащие начальные отсутствующие значения.
rmldDataTable = rmmissing(DataTable(:,seriesnames));
Создайте слабую сопряженную предшествующую модель. Задайте имена рядов ответов.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Случайным образом поместите отсутствующие значения в данные после периода предварительного образца.
rng(1) % For reproducibility T = size(rmldDataTable,1); idxpre = 1:PriorMdl.P; % Presample period idxest = (PriorMdl.P + 1):T; % Estimation period nmissing = 20; % Simulate at most nmissing missing values sidx = [randsample(idxest,nmissing,true); randsample(1:numseries,nmissing,true)]; lsidx = sub2ind([T,numseries],sidx(1,:),sidx(2,:)); MissData = table2array(rmldDataTable); MissData(lsidx) = NaN; MissDataTable = rmldDataTable; MissDataTable{:,:} = MissData;
Нарисуйте 1000 наборов параметров из апостериорного распределения путем вызова simsmooth. Верните значения, которые симуляция сглаживает для недостающих наблюдений.
[~,~,NaNDraws] = simsmooth(PriorMdl,MissDataTable);
NaNDraws - матрица 19 на 1000 случайным образом нарисованных векторов отклика из апостериорного прогнозирующего распределения. Элементы соответствуют отсутствующим значениям в данных, упорядоченных столбцовым поиском. Для примера, NaNDraws(3,1) - первый случайным образом нарисованный вмененный ответ третьего отсутствующего значения в данных. Найдите соответствующее значение в данных.
[idxi,idxj] = find(ismissing(MissDataTable),3); responsename = seriesnames(idxj(end))
responsename = "INFL"
observationtime = MissDataTable.Time(idxi(end))
observationtime = datetime
Q3-65
Постройте график эмпирического распределения вмененных значений уровня инфляции во время Q3-65.
histogram(NaNDraws(3,:))
title('Q3-65 Inflation Rate Empirical Distribution')
Рассмотрим 3-D модель VAR (4) моделирования параметров из апостериорного распределения при наличии отсутствующих значений.
Загрузите набор макроэкономических данных США. Вычислите уровень инфляции, стабилизируйте ставки безработицы и федеральных фондов и удалите недостающие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте слабую сопряженную предшествующую модель. Задайте имена рядов ответов.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Симулируйте 5000 коэффициентов и инновационных ковариационных матриц из апостериорного распределения. Задайте период горения 1000 и коэффициент утончения 5.
rng(1); % For reproducibility [Coeff,Sigma] = simsmooth(PriorMdl,rmDataTable{:,seriesnames},... 'NumDraws',5000,'BurnIn',1000,'Thin',5);
Coeff является матрицей коэффициентов 39 на 5000 и Sigma массив инновационных ковариационных матриц 3 на 3 на 5000. Оба Coeff и Sigma случайным образом вытягиваются из апостериорного распределения.
Рассмотрим 3-D модель VAR (4) моделирования параметров из апостериорного распределения при наличии отсутствующих значений. В этом случае примите, что предыдущая модель является полунъюгатной.
Загрузите набор макроэкономических данных США. Вычислите уровень инфляции, стабилизируйте ставки безработицы и федеральных фондов и удалите недостающие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте полуконъюгатную предшествующую модель. Задайте имена рядов ответов.
numseries = numel(seriesnames); numlags = 4; PriorMdl = bayesvarm(numseries,numlags,'ModelType','semiconjugate',... 'SeriesNames',seriesnames);
Чтобы получить начальные значения для коэффициентов, рассмотрите коэффициенты из модели VAR, подобранной к первым 30 наблюдениям.
Задайте наборы индексов, которые разделяют данные на четыре набора:
Длина p = 4 период инициализации для динамического компонента модели
= 30 наблюдений для оценки VAR начальных значений коэффициента
Длина p = 4 период инициализации для динамического компонента байесовской модели VAR
Оставление наблюдения для оценки апостериорной функции
T = size(rmDataTable); n0 = 30; idxpre0 = 1:PriorMdl.P; idxest0 = (idxpre0(end) + 1):(idxpre0(end) + 1 + n0); idxpre1 = (idxest0(end) + 1 - PriorMdl.P):idxest0(end); idxest1 = (idxest0(end) + 1):T; n1 = numel(idxest1);
Получите начальные значения коэффициентов путем подбора модели VAR к первым 34 наблюдениям. Используйте первые четыре наблюдения в качестве предварительной выборки.
Mdl0 = varm(PriorMdl.NumSeries,PriorMdl.P);
EstMdl0 = estimate(Mdl0,rmDataTable{idxest0,seriesnames},'Y0',rmDataTable{idxpre0,seriesnames});estimate возвращает объект модели, содержащий оценки коэффициентов AR в матричной форме и константы в векторе. Функции Bayesian VAR требуют начальных значений коэффициентов в векторе. Форматируйте начальные значения коэффициентов.
Coeff0 = [EstMdl0.AR{:} EstMdl0.Constant].';
Coeff0 = Coeff0(:);Симулируйте 1000 коэффициентов и ковариаций матриц из апостериорного распределения. Задайте оставшиеся наблюдения, из которых можно оценить апостериорные. Инициализируйте модель VAR, задав последние четыре наблюдения в предыдущей выборке оценки в качестве предварительной выборки и задайте вектор начального коэффициента, чтобы инициализировать апостериорную выборку.
rng(1); % For reproducibility [Coeff,Sigma] = simsmooth(PriorMdl,rmDataTable{idxest1,seriesnames},... 'Y0',rmDataTable{idxpre1,seriesnames},'Coeff0',Coeff0);
Coeff - матрица коэффициентов и Sigma 39 на 1000 массив инновационных ковариационных матриц 3 на 3 на 1000. Оба Coeff и Sigma случайным образом вытягиваются из апостериорного распределения.
Рассмотрим 3-D модель VAR (4) моделирования параметров из апостериорного распределения при наличии отсутствующих значений.
Загрузка и предварительная обработка данных
Загрузите набор макроэкономических данных США. Вычислите уровень инфляции, стабилизируйте ставки безработицы и федеральных фондов и удалите недостающие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте предыдущую модель
Создайте слабую сопряженную предшествующую модель. Задайте имена рядов ответов.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Прогнозирование ответов с использованием forecast
Непосредственно прогнозируется два года (восемь четвертей) наблюдений от апостериорного прогнозирующего распределения. forecast оценивает апостериорное распределение параметров, а затем формирует апостериорное прогнозирующее распределение.
rng(1); % For reproducibility
numperiods = 8;
YF = forecast(PriorMdl,numperiods,rmDataTable{:,seriesnames});YF - матрица прогнозируемых ответов 8 на 3.
Постройте график прогнозируемых откликов.
fh = rmDataTable.Time(end) + calquarters(1:8); for j = 1:PriorMdl.NumSeries subplot(3,1,j) plot(rmDataTable.Time(end - 20:end),rmDataTable{end - 20:end,seriesnames(j)},'r',... [rmDataTable.Time(end) fh],[rmDataTable{end,seriesnames(j)}; YF(:,j)],'b'); legend("Observed","Forecasted",'Location','NorthWest') title(seriesnames(j)) end

Прогнозирование ответов с использованием simsmooth
Сконфигурируйте набор данных для получения прогнозов от simsmooth путем конкатенации numperiods-by- numseries timetable отсутствующих значений до конца набора.
fTT = array2timetable(NaN(numperiods,numseries),'RowTimes',fh,... 'VariableNames',seriesnames); frmDataTable = [rmDataTable(:,seriesnames); fTT]; tail(frmDataTable)
ans=8×3 timetable
Time INFL DUNRATE DFEDFUNDS
_____ ____ _______ _________
Q2-09 NaN NaN NaN
Q3-09 NaN NaN NaN
Q4-09 NaN NaN NaN
Q1-10 NaN NaN NaN
Q2-10 NaN NaN NaN
Q3-10 NaN NaN NaN
Q4-10 NaN NaN NaN
Q1-11 NaN NaN NaN
Прогнозируйте модель VAR с помощью simsmooth. Как forecast, simsmooth оценивает апостериорное распределение, поэтому это требует предыдущей модели и данных. Укажите данные, содержащие конечные NaNс.
[~,~,~,YMean] = simsmooth(PriorMdl,frmDataTable);
YMean почти равен frmDataTable, за этими исключениями:
YMean исключает строки, соответствующие периоду предварительного образца frmDataTable(1:4,:).
Если frmDataTable(j,k) является NaN, YMean(j,k) - среднее значение апостериорного прогнозирующего распределения отклика k во время j.
Составьте расписание из YMean.
YMeanTT = array2timetable(YMean,'RowTimes',frmDataTable.Time((PriorMdl.P + 1):end),... 'VariableNames',seriesnames);
Постройте график прогнозируемых откликов.
for j = 1:PriorMdl.NumSeries subplot(3,1,j) plot(YMeanTT.Time((end - 20 - numperiods):(end - numperiods)),YMeanTT{(end - 20 - numperiods):(end - numperiods),j},'r',... YMeanTT.Time((end - numperiods):end),YMeanTT{(end - numperiods):end,j},'b'); legend("Observed","Forecasted",'Location','NorthWest') title(seriesnames(j)) end

Рассмотрим 3-D модель VAR (4) моделирования параметров из апостериорного распределения при наличии отсутствующих значений.
Загрузите набор макроэкономических данных США. Вычислите уровень инфляции, стабилизируйте ставки безработицы и федеральных фондов и удалите недостающие значения (данные включают только ведущие отсутствующие значения).
load Data_USEconModel seriesnames = ["INFL" "UNRATE" "FEDFUNDS"]; DataTable.INFL = 100*[NaN; price2ret(DataTable.CPIAUCSL)]; DataTable.DUNRATE = [NaN; diff(DataTable.UNRATE)]; DataTable.DFEDFUNDS = [NaN; diff(DataTable.FEDFUNDS)]; seriesnames(2:3) = "D" + seriesnames(2:3); rmDataTable = rmmissing(DataTable);
Создайте слабую сопряженную предшествующую модель. Задайте имена рядов ответов.
numseries = numel(seriesnames);
numlags = 4;
PriorMdl = conjugatebvarm(numseries,numlags,'SeriesNames',seriesnames);
numcoeffseqn = size(PriorMdl.V,1);
PriorMdl.V = 1e4*eye(numcoeffseqn);Условное прогнозирование происходит, когда значения отклика известны или гипотезированы в прогнозном горизонте, и неизвестные значения прогнозируются обусловленными известными значениями. Предположим, что уровень безработицы меняется (DUNRATE) остается на одной процентной точке через двухлетний прогнозный горизонт.
Сконфигурируйте набор данных для получения прогнозов от simsmooth путем конкатенации numperiods-by- numseries timetable отсутствующих значений до конца набора. Для изменения уровня безработицы замените отсутствующие значения вектором с таковыми.
rng(1); % For reproducibility numperiods = 8; fh = rmDataTable.Time(end) + calquarters(1:8); fTT = array2timetable(NaN(numperiods,numseries),'RowTimes',fh,... 'VariableNames',seriesnames); frmDataTable = [rmDataTable(:,seriesnames); fTT]; frmDataTable.DUNRATE((end - numperiods + 1):end) = ones(numperiods,1); tail(frmDataTable)
ans=8×3 timetable
Time INFL DUNRATE DFEDFUNDS
_____ ____ _______ _________
Q2-09 NaN 1 NaN
Q3-09 NaN 1 NaN
Q4-09 NaN 1 NaN
Q1-10 NaN 1 NaN
Q2-10 NaN 1 NaN
Q3-10 NaN 1 NaN
Q4-10 NaN 1 NaN
Q1-11 NaN 1 NaN
Получить прогнозы по уровню инфляции и федеральным фондам изменить ставки, учитывая, что изменение уровня безработицы является единичным для всего горизонта.
[~,~,~,YMean] = simsmooth(PriorMdl,frmDataTable);
YMean почти равен frmDataTable, за этими исключениями:
YMean исключает строки, соответствующие периоду предварительного образца frmDataTable(1:4,:).
Если frmDataTable(j,k) является NaN, YMean(j,k) - среднее значение апостериорного прогнозирующего распределения отклика k во время j.
Составьте расписание из YMean.
YMeanTT = array2timetable(YMean,'RowTimes',frmDataTable.Time((PriorMdl.P + 1):end),... 'VariableNames',seriesnames);
Постройте график прогнозируемых откликов.
for j = 1:PriorMdl.NumSeries subplot(3,1,j) plot(YMeanTT.Time((end - 20 - numperiods):(end - numperiods)),YMeanTT{(end - 20 - numperiods):(end - numperiods),j},'r',... YMeanTT.Time((end - numperiods):end),YMeanTT{(end - numperiods):end,j},'b'); legend("Observed","Forecasted",'Location','NorthWest') title(seriesnames(j)) end

Рассмотрим 2-D модель VARX (1) для реального ВВП США (RGDP) и инвестиции (GCE) тарифы, которые лечат личное потребление (PCEC) скорость как экзогенная:
Для всех , - серия независимых 2-D нормальных инноваций со средним значением 0 и ковариацией . Примите следующие предыдущие распределения:
, где M является матрицей средств 4 на 2 и - матрица шкалы между коэффициентами 4 на 4. Эквивалентно, .
где И - матрица шкалы 2 на 2, - степени свободы.
Загрузите набор макроэкономических данных США. Вычислите реальный показатель ВВП, инвестиций и личного потребления. Удалите все отсутствующие значения из получившейся серии.
load Data_USEconModel DataTable.RGDP = DataTable.GDP./DataTable.GDPDEF; seriesnames = ["PCEC"; "RGDP"; "GCE"]; rates = varfun(@price2ret,DataTable,'InputVariables',seriesnames); rates = rmmissing(rates); rates.Properties.VariableNames = seriesnames;
Создайте сопряженную предшествующую модель для параметров модели 2-D VARX (1).
numseries = 2; numlags = 1; numpredictors = 1; PriorMdl = conjugatebvarm(numseries,numlags,'NumPredictors',numpredictors,... 'SeriesNames',seriesnames(2:end));
Создайте наборы индексов, которые разделяют данные на оценочные и прогнозные выборки. Укажите горизонт прогноза на два года.
T = size(rates,1);
numperiods = 8;
idxest = 1:(T - numperiods); % Includes presample
idxf = (T - numperiods + 1):T;
idxtot = [idxest idxf];Симуляция сглаживает прогнозы путем ввода отсутствующих значений. Поэтому создайте набор данных, который содержит отсутствующие значения для откликов в горизонте прогноза.
missingrates = rates;
missingrates{idxf,PriorMdl.SeriesNames} = nan(numperiods,PriorMdl.NumSeries);Прогнозные отклики в прогнозном горизонте. Задайте наблюдения presample и данные экзогенного предиктора. Верните стандартные отклонения апостериорного прогнозирующего распределения.
rng(1) % For reproducibility [~,~,~,YMean,YStd] = simsmooth(PriorMdl,missingrates{:,PriorMdl.SeriesNames},... 'X',missingrates{:,seriesnames(1)});
Составьте расписание из YMean.
YMeanTT = array2timetable(YMean,'RowTimes',rates.Time((PriorMdl.P + 1):end),... 'VariableNames',PriorMdl.SeriesNames);
Постройте график прогнозируемых откликов.
for j = 1:PriorMdl.NumSeries subplot(PriorMdl.NumSeries,1,j) plot(rates.Time((end - 20):end),rates{(end - 20):end,PriorMdl.SeriesNames(j)},'r',... YMeanTT.Time((end - numperiods):end),YMeanTT{(end - numperiods):end,PriorMdl.SeriesNames(j)},'b'); legend("Observed","Forecasted",'Location','NorthWest') title(PriorMdl.SeriesNames(j)) end

Симуляция Монте-Карло подвержена изменениям. Если simsmooth использует симуляцию Монте-Карло, тогда оценки и выводы могут варьироваться при вызове simsmooth несколько раз при, казалось бы, эквивалентных условиях. Чтобы воспроизвести результаты оценки, установите начальное число случайных чисел при помощи rng перед вызовом simsmooth.
Этот рисунок показывает, как simsmooth уменьшает выборку при помощи значений NumDraws, Thin, и BurnIn. Прямоугольники представляют последовательные вытяжки из распределения. simsmooth удаляет белые прямоугольники из выборки. Оставшиеся NumDraws чёрные прямоугольники составляют выборку.
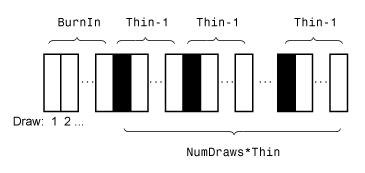
simsmooth не возвращает начальные значения по умолчанию, которые она генерирует.
[1] Литтерман, Роберт Б. «Прогнозирование с байесовскими векторными авторегрессиями: пятилетний опыт». Журнал деловой и экономической статистики 4, № 1 (январь 1986 года): 25-38. https://doi.org/10.2307/1391384.
