Проверьте кластеры в филогенетическом дереве
LeafClusters = cluster(Tree, Threshold)
[LeafClusters, NodeClusters]
= cluster(Tree, Threshold)
[LeafClusters, NodeClusters, Branches]
= cluster(Tree, Threshold)
cluster(..., 'Criterion', CriterionValue,
...)
cluster(..., 'MaxClust', MaxClustValue,
...)
cluster(..., 'Distances', DistancesValue,
...)
Tree | Филогенетический древовидный объект, созданный с помощью |
Threshold | Скаляр, задающий пороговое значение. |
CriterionValue | Вектор символов или строка, задающая критерий для определения количества кластеров как функции от видовых парных расстояний. Варианты:
|
MaxClustValue | Положительное целое число, указывающее максимальное количество возможных кластеров для протестированных разделов. По умолчанию это количество листьев в дереве. Совет При использовании Совет При использовании |
DistancesValue | Матрица парных расстояний, таких как возвращенная |
LeafClusters | Вектор-столбец, содержащий индекс кластера для каждого вида (листа) в |
NodeClusters | Вектор-столбец, содержащий индекс кластера для каждого конечного узла и узла ветви в |
Branches | Двухколоночная матрица, содержащая для каждого шага в алгоритме индекс рассматриваемой ветви и значение критерия. Каждая строка соответствует шагу в алгоритме. Первый столбец содержит индексы ветвей, а второй - значения критериев. Совет Чтобы получить целую кривую критерия от количества кластеров в |
LeafClusters = cluster(Tree, Threshold)
Начиная с двух кластеров (k = 2), выбирает раздел, который оптимизирует критерий, заданный 'Criterion' свойство
Шаги по k 1 и снова выбирает оптимальное разбиение
Продолжает увеличивать k и выбирать оптимальный раздел, пока значение критерия не = Threshold или k = максимальное количество кластеров (то есть количество листьев)
Из всех возможных k значений выбирает k значение, разбиение которого оптимизирует критерий
[ возвращает вектор-столбец, содержащий индекс кластера для каждого конечного узла и узла ветви в LeafClusters, NodeClusters]
= cluster(Tree, Threshold)Tree.
[ возвращает двухколоночную матрицу, содержащую для каждого шага в алгоритме индекс рассматриваемой ветви и значение критерия. Каждая строка соответствует шагу в алгоритме. Первый столбец содержит индексы ветвей, а второй - значения критериев.LeafClusters, NodeClusters, Branches]
= cluster(Tree, Threshold)
кластер (..., вызывает 'PropertyName', PropertyValue, ...)cluster с необязательными свойствами, которые используют пары имя/значение свойства. Можно задать одно или несколько свойств в любом порядке. Заключайте каждую PropertyName в одинарных кавычках. Каждый PropertyName является нечувствительным к регистру. Эти имена свойства/пары значения свойств следующие:.
cluster(..., 'Criterion', задает критерий для определения количества кластеров как функции парных расстояний вида. CriterionValue,
...)
cluster(..., 'MaxClust', задает максимальное количество возможных кластеров для протестированных разделов. По умолчанию это количество листьев в дереве.MaxClustValue,
...)
cluster(..., 'Distances', подставляет святоотеческие расстояния в DistancesValue,
...)Tree с пользовательской парной матрицей расстояний.
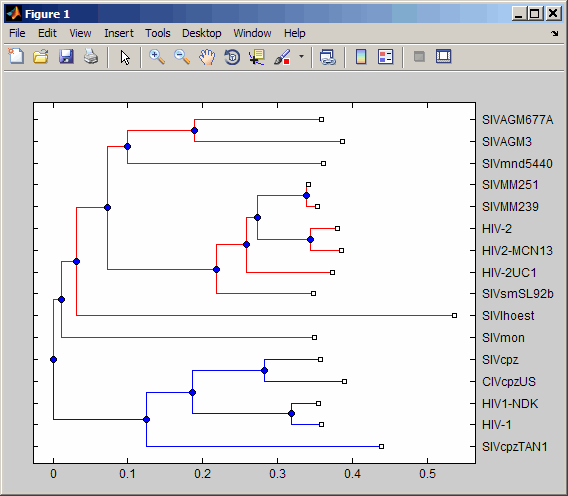
Проверьте кластеры в филогенетическом дереве:
% Read sequences from a multiple alignment file into a MATLAB
% structure
gagaa = multialignread('aagag.aln');
% Build a phylogenetic tree from the sequences
gag_tree = seqneighjoin(seqpdist(gagaa),'equivar',gagaa);
% Validate the clusters in the tree and find the best partition
% using the 'gain' criterion
[i,j] = cluster(gag_tree,[],'criterion','gain','maxclust',10);
% Use the returned vector of indices to color the branches of each
% cluster in a plot of the tree
h = plot(gag_tree);
set(h.BranchLines(j==2),'Color','b')
set(h.BranchLines(j==1),'Color','r')
[1] Дудойт, С. и Фридлян, Дж. (2002). Основанный на предсказании способ повторной дискретизации для оценки количества кластеров в наборе данных. Биология генома 3 (7), исследование 0036.1-0036.21.
[2] Theodoridis, S. and Koutroumbas, K. (1999). Распознавание шаблонов (Academic Press), стр. 434-435.
[3] Kaufman, L. and Rousseeu, P.J. (1990). Поиск групп в данных: введение в кластерный анализ (Нью-Йорк, Уайли).
[4] Calinski, R. and Harabasz, J. (1974). Метод дендрита для кластерного анализа. Commun Statistics 3, 1-27.
[5] Hartigan, J.A. (1985). Статистическая теория в кластеризации. J Классификация 2, 63-76.
cluster | phytree | phytreeread | phytreeviewer | plot | seqlinkage | seqneighjoin | seqpdist | silhouette | view
