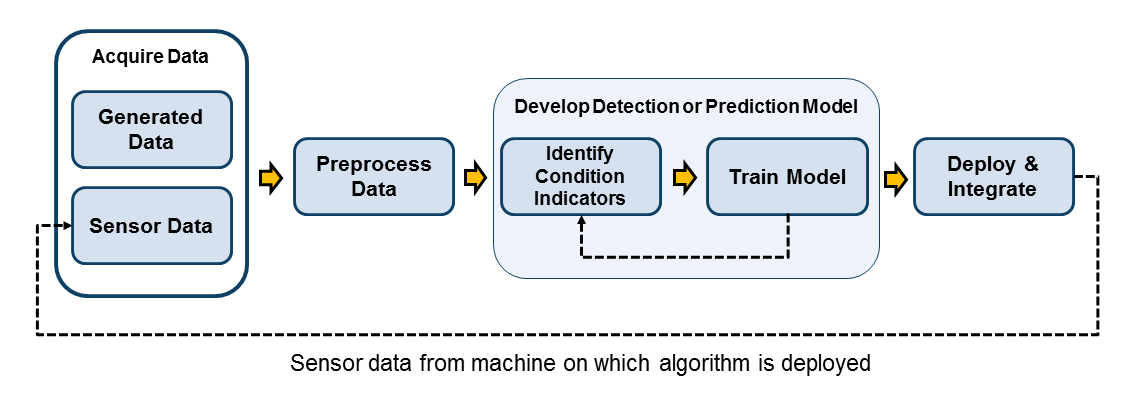
Мониторинг состояния включает в себя различие между состоянием неисправности и состоянием работоспособности (обнаружение неисправности) или, при наличии состояния неисправности, определение источника неисправности (диагностика неисправности). Для разработки алгоритма контроля условий используются индикаторы условий, извлеченные из системных данных, для обучения модели принятия решений, которая может анализировать индикаторы, извлеченные из тестовых данных, для определения текущего состояния системы. Таким образом, этот шаг в процессе разработки алгоритма является следующим шагом после идентификации индикаторов состояния.
(Сведения об использовании индикаторов условий для прогнозирования отказов см. в разделе Модели прогнозирования остаточного срока службы.)
Некоторые примеры моделей принятия решений для мониторинга состояния включают в себя:
Пороговое значение или набор ограничений для значения индикатора условия, указывающего на неисправность, когда индикатор превышает его
Распределение вероятностей, описывающее вероятность того, что какое-либо конкретное значение индикатора условия указывает на какой-либо конкретный тип неисправности
Классификатор, сравнивающий текущее значение индикатора состояния со значениями, связанными с состояниями отказа, и возвращающий вероятность наличия того или иного состояния отказа.
Как правило, при тестировании различных моделей для обнаружения или диагностики неисправностей создается таблица значений одного или нескольких индикаторов условий. Индикаторы состояния - это функции, которые извлекаются из данных в ансамбле, представляющих различные исправные и неисправные рабочие условия. (См. Индикаторы состояния для мониторинга, обнаружения неисправностей и прогнозирования.) Рекомендуется разделить данные на подмножество, используемое для обучения модели принятия решений (данные обучения), и непересекающееся подмножество, используемое для проверки (данные проверки). По сравнению с обучением и проверкой с перекрывающимися наборами данных, использование совершенно отдельных данных обучения и проверки, как правило, дает лучшее представление о том, как модель принятия решений будет работать с новыми данными.
При разработке алгоритма можно протестировать различные модели обнаружения и диагностики неисправностей с использованием различных индикаторов состояния. Таким образом, этот шаг в процессе конструирования, вероятно, является итеративным с шагом извлечения индикаторов условий, поскольку вы пробуете различные индикаторы, различные комбинации индикаторов и различные модели принятия решений.
Toolbox™ статистики и машинного обучения и другие панели инструментов включают функциональные возможности, которые можно использовать для обучения моделей принятия решений, таких как классификаторы и регрессионные модели. Здесь кратко излагаются некоторые общие подходы.
Методы выбора элементов помогают сократить большие наборы данных за счет исключения элементов, которые не имеют отношения к выполняемому анализу. В контексте контроля состояния неактуальными являются функции, которые не отделяют работоспособность от неисправной работы или помогают различать различные состояния отказа. Другими словами, выбор признаков означает идентификацию признаков, подходящих для использования в качестве индикаторов условий, поскольку они изменяются обнаруживаемым и надежным образом по мере снижения производительности системы. Некоторые функции для выбора элементов:
pca - выполнение анализа основных компонентов, при котором обнаруживается линейная комбинация независимых переменных данных, на которые приходится наибольшая вариация наблюдаемых значений. Например, предположим, что у вас есть десять независимых сигналов датчиков для каждого члена вашего ансамбля, из которых вы извлекаете много функций. В этом случае анализ основных компонентов может помочь определить, какие функции или комбинация функций наиболее эффективны для разделения различных здоровых и неисправных условий, представленных в вашем ансамбле. В примере «Прогноз высокоскоростного подшипника ветровой турбины» этот подход используется для выбора характеристик.
sequentialfs - Для набора признаков-кандидатов определите признаки, которые лучше всего различают здоровые и неисправные условия, путем последовательного выбора признаков до тех пор, пока не будет улучшена дискриминация.
fscnca - выбор элемента для классификации с помощью анализа компонентов окрестности. В примере «Использование Simulink для генерации данных об отказах» эта функция используется для взвешивания списка извлеченных индикаторов состояния в соответствии с их важностью для различения условий отказа.
Дополнительные функции, связанные с выбором элемента, см. в разделах Уменьшение размерности и Извлечение элемента.
При наличии таблицы значений индикаторов условий и соответствующих состояний отказов эти значения могут соответствовать статистическому распределению. Сравнение проверочных или тестовых данных с результирующим распределением дает вероятность того, что проверочные или тестовые данные соответствуют тому или иному состоянию отказа. Некоторые функции, которые можно использовать для такого фитинга:
ksdensity - Оценка плотности вероятности для данных выборки.
histfit - Создание гистограммы на основе данных и подгонка ее к нормальному распределению. Этот подход используется в примере Диагностика неисправностей центробежных насосов с использованием экспериментов в установившемся состоянии.
ztest - Проверка вероятности того, что данные получены из нормального распределения с указанным средним и стандартным отклонением.
Дополнительные сведения о статистических распределениях см. в разделе Распределения вероятностей.
Существует несколько способов применения методов машинного обучения к проблеме обнаружения и диагностики неисправностей. Классификация - это тип контролируемого машинного обучения, при котором алгоритм «учится» классифицировать новые наблюдения на примерах помеченных данных. В контексте обнаружения и диагностики неисправностей можно передать индикаторы состояния, полученные из ансамбля, и соответствующие им метки неисправностей функции подбора алгоритма, которая обучает классификатор.
Например, предположим, что вы вычисляете таблицу значений индикаторов условий для каждого члена в совокупности данных, которая охватывает различные здоровые и неисправные условия. Эти данные можно передать в функцию, которая соответствует модели классификатора. Эти учебные данные обучают модель классификатора принимать набор значений индикаторов условий, извлеченных из нового набора данных, и угадывать, какое здоровое или неисправное состояние применимо к данным. На практике вы используете часть своего ансамбля для обучения и резервируете непересекающуюся часть ансамбля для проверки обученного классификатора.
Набор инструментов для статистики и машинного обучения включает множество функций, которые можно использовать для обучения классификаторов. К этим функциям относятся:
fitcsvm - обучить модель двоичной классификации различать два состояния, например наличие или отсутствие состояния отказа. В примерах Использование Simulink для генерации данных об отказах эта функция используется для обучения классификатора с помощью таблицы индикаторов условий на основе признаков. В примере Диагностика неисправности центробежных насосов с использованием экспериментов в установившемся состоянии также использует эту функцию, при этом основанные на модели индикаторы состояния вычисляются на основе статистических свойств параметров, полученных путем подбора данных к статической модели.
fitcecoc - Подготовка классификатора для различения нескольких состояний. Эта функция сводит проблему мультиклассовой классификации к набору двоичных классификаторов. Эта функция используется в примере «Обнаружение многоклассных отказов с использованием моделируемых данных».
fitctree - обучить мультиклассовую классификационную модель, сократив проблему до набора двоичных деревьев решений.
fitclinear - Подготовка классификатора с использованием высокоразмерных обучающих данных. Эта функция может быть полезна при наличии большого количества индикаторов условий, которые невозможно уменьшить с помощью таких функций, как fscnca.
Другие методы машинного обучения включают кластеризацию k-средств (kmeans), который разбивает данные на взаимоисключающие кластеры. В этом методе новое измерение назначается кластеру путем минимизации расстояния от точки данных до среднего местоположения его назначенного кластера. Фасовка деревьев в мешки - еще один метод, который агрегирует ансамбль деревьев принятия решений для классификации. В примере Диагностика неисправностей центробежных насосов с использованием экспериментов в установившемся состоянии использует TreeBagger классификатор.
Дополнительные общие сведения о методах машинного обучения для классификации см. в разделе Классификация.
Другой подход к обнаружению и диагностике неисправностей заключается в использовании идентификации модели. Этот подход позволяет оценить динамические модели работы системы в работоспособном и неисправном состоянии. Затем анализируется, какая модель с большей вероятностью объясняет измерения в реальном времени из системы. Этот подход полезен при наличии информации о системе, которая поможет выбрать тип модели для идентификации. Для использования этого подхода необходимо:
Сбор или моделирование данных из системы, работающей в исправном состоянии и в известных неисправных, ухудшенных или истекших условиях.
Определите динамическую модель, представляющую поведение в каждом исправном и неисправном состоянии.
Используйте методы кластеризации, чтобы провести четкое различие между условиями.
Сбор новых данных с работающего компьютера и определение модели его поведения. Затем можно определить, какая из других моделей, здоровая или неисправная, скорее всего, объяснит наблюдаемое поведение.
Этот подход используется в примере Обнаружение неисправностей с использованием моделей на основе данных. Для идентификации динамических моделей можно использовать следующие функции:
Можно использовать такие функции, как forecast для прогнозирования будущего поведения идентифицированной модели.
Методы статистического контроля процессов (СТС) являются методами мониторинга и оценки качества промышленных товаров. SPC используется в программах, которые определяют, измеряют, анализируют, совершенствуют и контролируют процессы разработки и производства. В контексте прогностического обслуживания контрольные диаграммы и правила управления могут помочь определить, когда значение индикатора условия указывает на неисправность. Например, предположим, что у вас есть индикатор состояния, который указывает на ошибку, если она превышает пороговое значение, но также имеет некоторые обычные отклонения, которые затрудняют идентификацию при превышении порогового значения. Можно использовать правила управления, чтобы определить пороговое условие как возникающее, когда заданное число последовательных измерений превышает пороговое значение, а не только одно.
controlchart - Визуализация контрольной диаграммы.
controlrules - Определите правила контроля и определите, нарушены ли они.
cusum - Обнаружение небольших изменений в среднем значении данных.
Дополнительные сведения о статистическом управлении процессами см. в разделе Статистический контроль процессов.
Другим способом обнаружения состояний отказа является отслеживание значения индикатора состояния во времени и обнаружение резких изменений в поведении тренда. Такие резкие изменения могут указывать на неисправность. Некоторые функции, которые можно использовать для такого обнаружения точки изменения, включают в себя:
findchangepts - Найти резкие изменения в сигнале.
findpeaks - Найти пики в сигнале.
pdist, pdist2, mahal - Определение расстояния между измерениями или наборами измерений в соответствии с различными определениями расстояния.
segment - данные сегмента и оценка моделей AR, ARX, ARMA или ARMAX для каждого сегмента. Этот подход используется в примере Обнаружение неисправностей с использованием моделей на основе данных.
