Предварительная обработка данных используется для обучения, валидации и вывода. Предварительная обработка состоит из ряда детерминированных операций, которые нормализуют или улучшают желаемые функции данных. Для примера можно нормализовать данные до фиксированной области значений или перерассчитать данные до размера, требуемого слоем сетевого входа.
Предварительная обработка может происходить на двух этапах рабочего процесса глубокого обучения.
Обычно предварительная обработка происходит как отдельный шаг, который вы завершаете перед подготовкой данных, которые будут переданы в сеть. Вы загружаете свои исходные данные, применяете операции предварительной обработки, а затем сохраняете результат на диск. Преимущество этого подхода заключается в том, что накладные расходы на предварительную обработку требуются только один раз, тогда предварительно обработанные изображения легко доступны в качестве отправного места для всех будущих испытаний по обучению сети.
Если вы загружаете свои данные в datastore, то можно также применить предварительную обработку во время обучения с помощью transform и combine функций. Для получения дополнительной информации смотрите Datastores для глубокого обучения. Преобразованные изображения не хранятся в памяти. Этот подход удобен, чтобы избежать записи второй копии обучающих данных на диск, если ваши операции предварительной обработки не являются вычислительно дорогими и не оказывают заметного влияния на скорость обучения сети.
Увеличение количества данных состоит из рандомизированных операций, которые применяются к обучающим данным во время обучения сети. Увеличение увеличивает эффективный объем обучающих данных и помогает сделать сеть инвариантной общим искажениям в данных. Например, можно добавить искусственный шум к обучающим данным, чтобы сеть была инвариантна для шума.
Чтобы увеличить обучающие данные, начните с загрузки данных в datastore. Для получения дополнительной информации смотрите Datastores для глубокого обучения. Некоторые встроенные хранилища данных применяют определенный и ограниченный набор увеличения к данным для конкретных приложений. Можно также применить свой собственный набор операций увеличения к данным в datastore при помощи transform и combine функций. Во время обучения datastore случайным образом возмущает обучающие данные для каждой эпохи, так что каждая эпоха использует немного другой набор данных.
Увеличение данных изображения, чтобы симулировать изменения в сборе изображения. Для примера наиболее распространенным типом операций увеличения изображения являются геометрические преобразования, такие как поворот и перемещение, которые моделируют изменения ориентации камеры относительно сцены. Color jitter моделирует изменения условий подсветки и цвета в сцене. Искусственный шум описывает искажения, вызванные электрическими колебаниями в датчике и ошибками аналого-цифрового преобразования. Blur имитирует нефокусированный линз или движение камеры относительно сцены.
Общие операции предварительной обработки изображений включают удаление шума, сглаживание с сохранением края, преобразование цветового пространства, улучшение контрастности и морфологию.
Если у вас есть Image Processing Toolbox™, можно обработать данные с помощью этих операций, а также любых других функций в тулбоксе. Для примера, который показывает, как создать и применить эти преобразования, смотрите Дополнение изображений для рабочих процессов глубокого обучения с использованием Image Processing Toolbox.
| Тип обработки | Описание | Выборочные функции | Выходы выборки |
|---|---|---|---|
| Изменение размера изображений | Измените размер изображений с помощью фиксированного коэффициента масштабирования или на целевой размер |
| |
| Изображения деформации | Применить случайное отражение, вращение, шкалу, сдвиг и перемещение к изображениям |
|
|
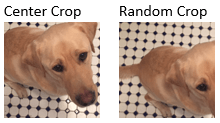
| Обрезка изображений | Обрезка изображения до целевого размера из центра или случайного положения |
|
|
| Цвет дрожания | Случайным образом настройте оттенок, насыщение, яркость или контрастность изображения |
|
|
| Симулируйте шум | Добавьте случайный Гауссов, Пуассон, соль и перец или мультипликативный шум |
|
|
| Симулируйте размытие | Добавьте Гауссов или прямое размытие движения |
|
|
Данные обнаружения объектов состоят из изображения и ограничивающих рамок, которые описывают местоположение и характеристики объектов в изображении.
Если у вас есть Computer Vision Toolbox™, то можно использовать приложения Image Labeler (Computer Vision Toolbox) и Video Labeler (Computer Vision Toolbox) для интерактивной маркировки ROIs и экспорта данных о метках для обучения нейронной сети. Если у вас есть Automated Driving Toolbox™, то вы также используете приложение Ground Truth Labeler (Automated Driving Toolbox) для создания маркированных основных истин обучающих данных.
При преобразовании изображения необходимо выполнить идентичное преобразование с соответствующими ограничивающими рамками. Если у вас есть Computer Vision Toolbox, можно обработать данные ограничивающего прямоугольника с помощью операций в таблице. Пример, в котором показано, как создать и применить эти преобразования, см. в разделе «Увеличение ограничивающих рамок для обнаружения объектов». Для получения дополнительной информации смотрите Начало работы с Обнаружением объектов Используя Глубокое Обучение (Computer Vision Toolbox).
| Тип обработки | Описание | Выборочные функции | Выходы выборки |
|---|---|---|---|
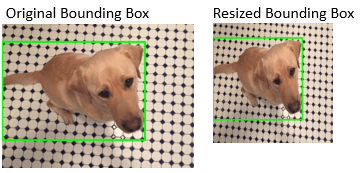
| Изменение размера ограничивающих рамок | Измените размер ограничивающих рамок на фиксированный масштабный коэффициент или на целевой размер |
|
|
| Обрезка ограничивающих рамок | Обрезать ограничивающий прямоугольник до целевого размера от центра или случайного положения |
|
|
| Ограничительные рамки деформации | Примените отражение, вращение, шкалу, сдвиг и перемещение к ограничивающим прямоугольникам |
|
|
Семантические данные сегментации состоят из изображений и соответствующих пиксельных меток, представленных в виде категориальных массивов.
Если у вас есть Computer Vision Toolbox, то можно использовать приложения Image Labeler (Computer Vision Toolbox) и Video Labeler (Computer Vision Toolbox) для интерактивной маркировки пикселей и экспорта данных о метках для настройки нейронной сети. Если у вас есть Automated Driving Toolbox, то вы также используете приложение Ground Truth Labeler (Automated Driving Toolbox) для создания маркированных основных истин обучающих данных.
Когда вы преобразовываете изображение, вы должны выполнить идентичное преобразование с соответствующим пиксельным маркированным изображением. Если у вас есть Image Processing Toolbox, то можно предварительно обработать изображения меток пикселей с помощью функций в таблице и любой другой функции тулбокса, которая поддерживает категориальный вход. Для примера, который показывает, как создать и применить эти преобразования, смотрите Увеличение Пиксельных Меток для Семантической Сегментации. Для получения дополнительной информации смотрите Начало работы с семантической сегментацией с использованием глубокого обучения (Computer Vision Toolbox).
| Тип обработки | Описание | Выборочные функции | Выходы выборки |
|---|---|---|---|
| Изменение размера меток пикселей | Измените размер изображений меток пикселей с помощью фиксированного коэффициента масштабирования или до целевого размера |
|
|
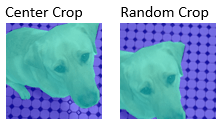
| Обрезка меток пикселей | Обрезать изображение метки пикселя до целевого размера из центра или случайного положения |
|
|
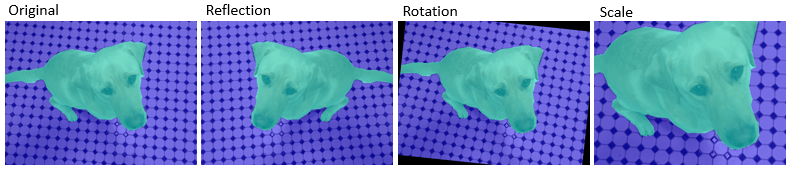
| Метки пикселей деформации | Применить случайное отражение, вращение, шкалу, сдвиг и перемещение к изображениям меток пикселей |
|
|
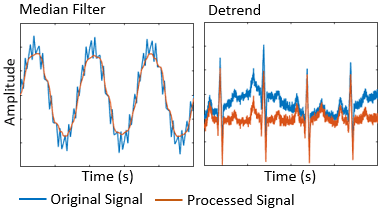
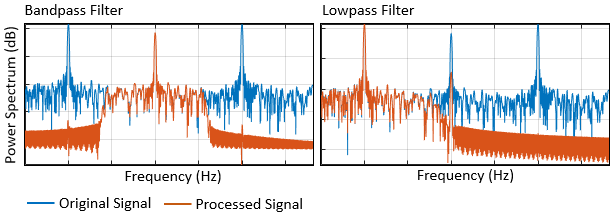
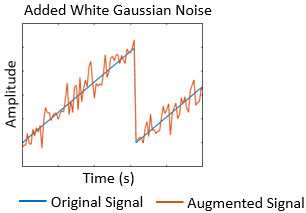
Signal Processing Toolbox™ позволяет вам обесценивать, сглаживать, детрендировать и сбрасывать сигналы. Можно дополнить обучающие данные шумом, многолучевым замиранием и синтетическими сигналами, такими как импульсы и щебет. Можно также создать маркированные наборы сигналов с помощью приложения Signal Labeler (Signal Processing Toolbox) и labeledSignalSet (Signal Processing Toolbox) объект. Для примера, который показывает, как создать и применить эти преобразования, смотрите Сегментацию формы волны с использованием глубокого обучения.
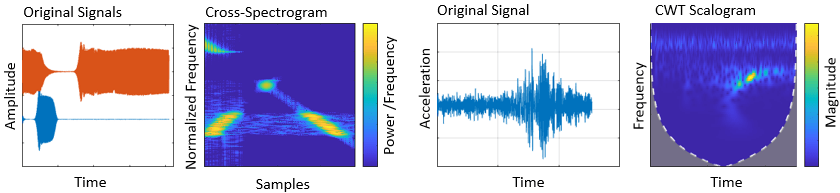
Wavelet Toolbox™ и Signal Processing Toolbox позволяют вам генерировать 2-D частотно-временные представления данных временных рядов, которые вы можете использовать в качестве входов изображений для приложений классификации сигналов. Для получения примера смотрите Классификация временных рядов с помощью Вейвлета анализа и глубокого обучения. Точно так же можно извлечь последовательности из данных сигнала, чтобы использовать их в качестве входа для сетей LSTM. Для получения примера смотрите Классификацию сигналов ЭКГ с использованием длинных краткосрочных Памятей сетей (Signal Processing Toolbox).
Communications Toolbox™ расширяются по функциональности обработки сигналов, чтобы вы могли выполнить коррекцию ошибок, перемежение, модуляцию, фильтрацию, синхронизацию и эквализацию систем связи. Для примера, который показывает, как создать и применить эти преобразования, смотрите Классификацию модуляции с глубоким обучением.
Можно обработать данные сигнала с помощью функций в таблице, а также любых других функциональных возможностей в каждом тулбоксе.
| Тип обработки | Описание | Выборочные функции | Выходы выборки |
|---|---|---|---|
| Чистые сигналы |
|
|
|
| Фильтрация сигналов |
|
|
|
| Сигналы увеличения |
|
| |
| Создайте частотно-временные представления | Создайте спектрограммы, скалограммы и другие 2-D представления сигналов 1-D |
| |
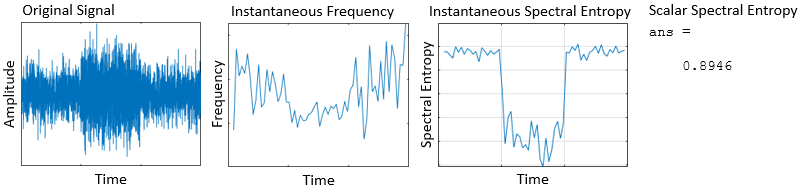
| Извлечение функций из сигналов | Оценка мгновенной частоты и спектральной энтропии |
|
Audio Toolbox™ предоставляет инструменты для обработки звука, анализа речи и акустического измерения. Используйте эти инструменты для извлечения слуховых функций и преобразования аудиосигналов. Увеличение аудио данных с рандомизированным или детерминированным масштабированием времени, растяжением времени и перемены тангажа. Вы также можете создать маркированные основные истины обучающих данных с помощью приложения Audio Labeler (Audio Toolbox). Вы можете обрабатывать аудиоданные с помощью функций этой таблицы, а также любых других функций в тулбоксе. Пример, показывающий, как создать и применить эти преобразования, см. в Augment Audio Dataset (Audio Toolbox).
| Тип обработки | Описание | Выборочные функции | Выходы выборки |
|---|---|---|---|
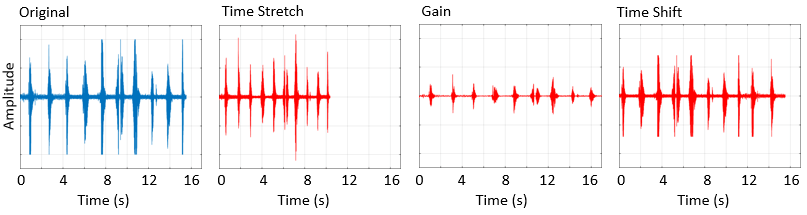
| Увеличение звуковых данных | Выполните случайное или детерминированную перемену тангажа, изменение шкалы времени, сдвиг времени, сложение шума и регулирование объема |
|
|
| Извлечение аудио функций | Извлеките спектральные параметры из аудиосегментов |
|
Обработанный выход:
ans = struct with fields:
mfcc: [1 2 3 4 5 6 7 8 9 10 11 12 13]
mfccDelta: [14 15 16 17 18 19 20 21 22 23 24 25 26]
mfccDeltaDelta: [27 28 29 30 31 32 33 34 35 36 37 38 39]
spectralCentroid: 40
pitch: 41
|
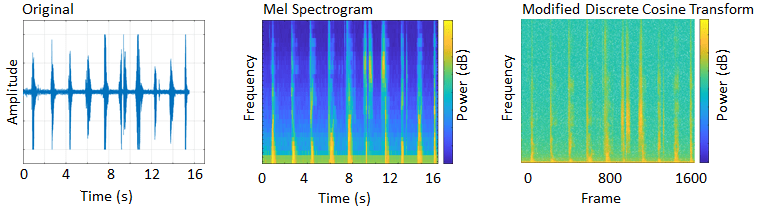
| Создайте частотно-временные представления | Создайте mel spectrograms и другие 2-D представления аудиосигналов |
|
|
Text Analytics Toolbox™ включает инструменты для обработки необработанного текста из источников, таких как журналы оборудования, ленты новостей, опросы, отчеты операторов и социальные сети. Используйте эти инструменты, чтобы извлечь текст из популярных файловых форматов, предварительно обработать необработанный текст, извлечь отдельные слова или многословные фразы (n-граммы), преобразовать текст в числовые представления и создать статистические модели. Обработать текстовые данные можно с помощью функций этой таблицы, а также любых других функциональных возможностей тулбокса. Пример, показывающий начало работы, см. в разделе Подготовка текстовых данных к анализу (Symbolic Math Toolbox).
| Тип обработки | Описание | Выборочные функции | Выходы выборки |
|---|---|---|---|
| Токенизация текста | Разобрать текст на слова и пунктуацию |
| Оригинал:
Обработанный выход:
|
| Чистый текст |
|
| Обработанный выход:
|
combine | read | trainingOptions | trainNetwork | transform